

ゾウは踊れないなんて誰が言った? ICLR 2024 のクロスモーダル インタラクションのタイミング予測を実現するための大規模言語モデルの再プログラミング

最近、オーストラリアのモナシュ大学、Ant Group、IBM Research、およびその他の機関の研究者は、大規模言語モデル (LLM) に対するモデル再プログラミング (モデル再プログラミング) の適用を検討し、次の新しい観点を提案しました。一般的な時系列予測システム、Time-LLM フレームワーク用の大規模言語モデル。このフレームワークは、言語モデルを変更せずに高精度かつ効率的な予測を実現でき、複数のデータセットや予測タスクにおいて従来の時系列モデルを上回ることができ、LLM がクロスモーダル時系列データを処理する際に、象が踊るように優れたパフォーマンスを発揮できるようになります。 。

最近、一般知能の分野における大規模言語モデルの開発に伴い、「大規模モデル時系列/時間データ」という新しい方向性が関連する多くの発展を示しています。現在の LLM は、時系列/時間データ マイニング方法に革命を起こす可能性を秘めており、それによって都市、エネルギー、交通、健康などの古典的な複雑なシステムにおける効率的な意思決定を促進し、より普遍的なインテリジェントな形式の時間/空間分析に移行します。 。
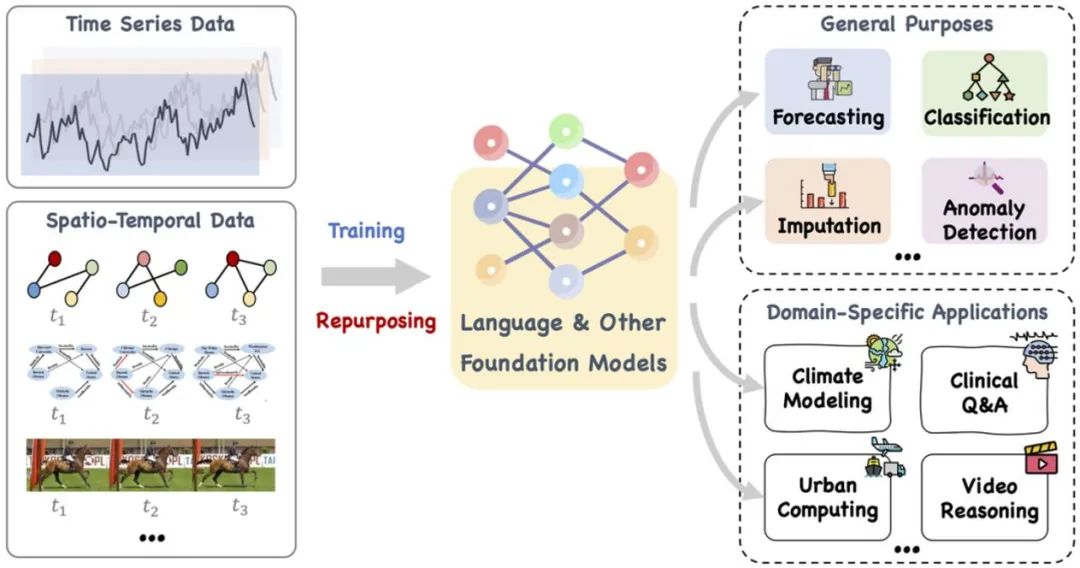
この論文では、言語やその他の関連モデルなど、トレーニングしたり、巧みに調整したりできる大規模な基本モデルを提案します。目的は、時系列を処理することです。さまざまな汎用タスクやドメイン固有のアプリケーションのための時空間データも含まれます。参照: https://arxiv.org/pdf/2310.10196.pdf。
最近の研究では、大規模な言語モデルが自然言語の処理から時系列および時空間タスクまで拡張されました。この新しい研究の方向性、すなわち「大規模モデル時系列/時空間データ」は、ゼロショット時系列予測推論に LLM を直接利用する LLMTime など、多くの関連開発を生み出しました。 LLM には強力な学習機能と表現機能があり、テキスト シーケンス データの複雑なパターンと長期的な依存関係を効果的にキャプチャできますが、自然言語の処理に焦点を当てた「ブラック ボックス」として、時系列タスクや時空間タスクでの LLM の適用は依然として課題に直面しています。チャレンジ。 TimesNet、TimeMixer などの従来の時系列モデルと比較すると、LLM はその膨大なパラメータとスケールにより「象」に匹敵します。
あなたが求めているのは、自然言語の分野でトレーニングされたこのような大規模言語モデル (LLM) を「飼いならす」方法で、テキスト パターン全体の数値シーケンス データを処理し、時系列および時空間タスクを実行できるようにする方法です。強力な推論能力と予測能力を開発することが、現在の研究の重要な焦点となっています。この目的を達成するには、言語データと時間データの間の潜在的なパターンの類似性を調査し、それらを特定の時系列および時空間タスクに効果的に適用するための、より深い理論的分析が必要です。
LLM リプログラミング モデル (LLM Reprogramming) は、一般的な時系列予測技術です。それは、(1) 時間的入力再プログラミングと (2) プロンプト事前プログラミングという 2 つの主要な技術を提案しています。これは、時間的予測タスクを、LLM によって効果的に解決できる「言語」タスクに変換し、大規模な言語モデルを有効化して高いレベルのデータを達成することに成功します。パフォーマンス 正確なタイミング推論を実行する能力。

論文のアドレス: https://openreview.net/pdf?id=Unb5CVPtae
論文のコード: https://github.com/KimMeen/時間-LLM
1. 問題の背景
時系列データは現実に広く保存されており、現実世界の多くの動的システムでは時系列予測が非常に重要です。も広く研究されています。単一の大規模モデルで複数のタスクを処理できる自然言語処理 (NLP) やコンピューター ビジョン (CV) とは異なり、時系列予測モデルは、多くの場合、さまざまなタスクやアプリケーション シナリオのニーズを満たすように特別に設計する必要があります。最近の研究では、大規模言語モデル (LLM) は、複雑な時系列シーケンスを処理する場合にも信頼できることが示されていますが、大規模言語モデル自体の推論機能を利用して時系列分析タスクを処理することは依然として課題です。
2. 論文の概要
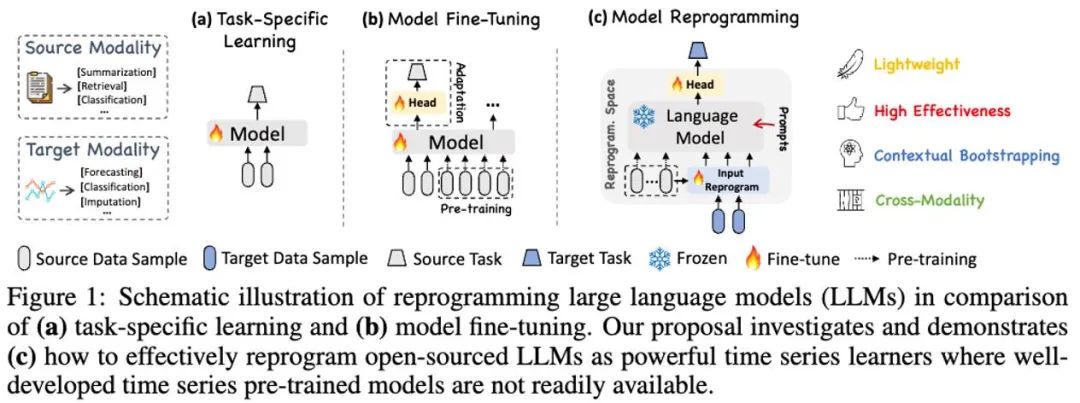
この研究では、著者は一般的な言語モデルの再プログラミングである Time-LLM を提案します。 (LLM 再プログラミング) フレームワークでは、大規模な言語モデル自体でトレーニングを行わなくても、一般的な時系列予測に LLM を簡単に使用できます。 Time-LLM は、まずテキスト プロトタイプ (テキスト プロトタイプ) を使用して入力時系列データを再プログラムし、自然言語表現を使用して時系列データのセマンティック情報を表現します。これにより、2 つの異なるデータ モダリティを調整するため、大規模な言語モデルが変更が必要な場合は、別のデータ モダリティの背後にある情報を理解できます。
入力時系列データと対応するタスクの LLM の理解をさらに強化するために、著者は、時系列データ表現の前に追加のコンテキスト プロンプトとタスク指示を追加することにより、プレフィックスとしてのプロンプト (PaP) パラダイムを提案しました。 LLM のタイミング タスクの処理機能。この研究では、著者は主流の時系列ベンチマーク データ セットで十分な実験を実施し、その結果、Time-LLM がほとんどの場合で従来の時系列モデルを上回り、少数ショットおよびゼロショット サンプルでより優れたパフォーマンスを達成できることが示されました。サンプル (ゼロショット) 学習タスクが大幅に改善されました。
この研究の主な貢献は次のように要約できます:
1. この研究は、バックボーン言語に変更を加えることなく、タイミング解析のために大規模な言語モデルを再プログラミングするという新しい概念を提案します。モデル。著者らは、時系列予測は、既製の LLM によって効果的に解決できる別の「言語」タスクとみなすことができることを示しています。
2. この研究では、一般的な言語モデルの再プログラミング フレームワーク、つまり Time-LLM を提案します。これは、入力時間データをより自然なテキスト プロトタイプ表現に再プログラミングし、ドメインの専門知識やタスクの説明などの宣言的なプロンプトを介して構成されます。 ) 入力コンテキストを強化して、LLM を効果的なクロスドメイン推論に導きます。このテクノロジーは、マルチモーダル タイミング基本モデルの開発に強固な基盤を提供します。
3. Time-LLM は、主流の予測タスク、特にサンプルが少ないシナリオやサンプルがゼロのシナリオにおいて、既存のモデルの最高のパフォーマンスを常に上回ります。さらに、Time-LLM は、優れたモデル再プログラミング効率を維持しながら、より高いパフォーマンスを実現できます。時系列データやその他の順次データに対する LLM の未開発の可能性を劇的に解き放ちます。
3. モデルの枠組み
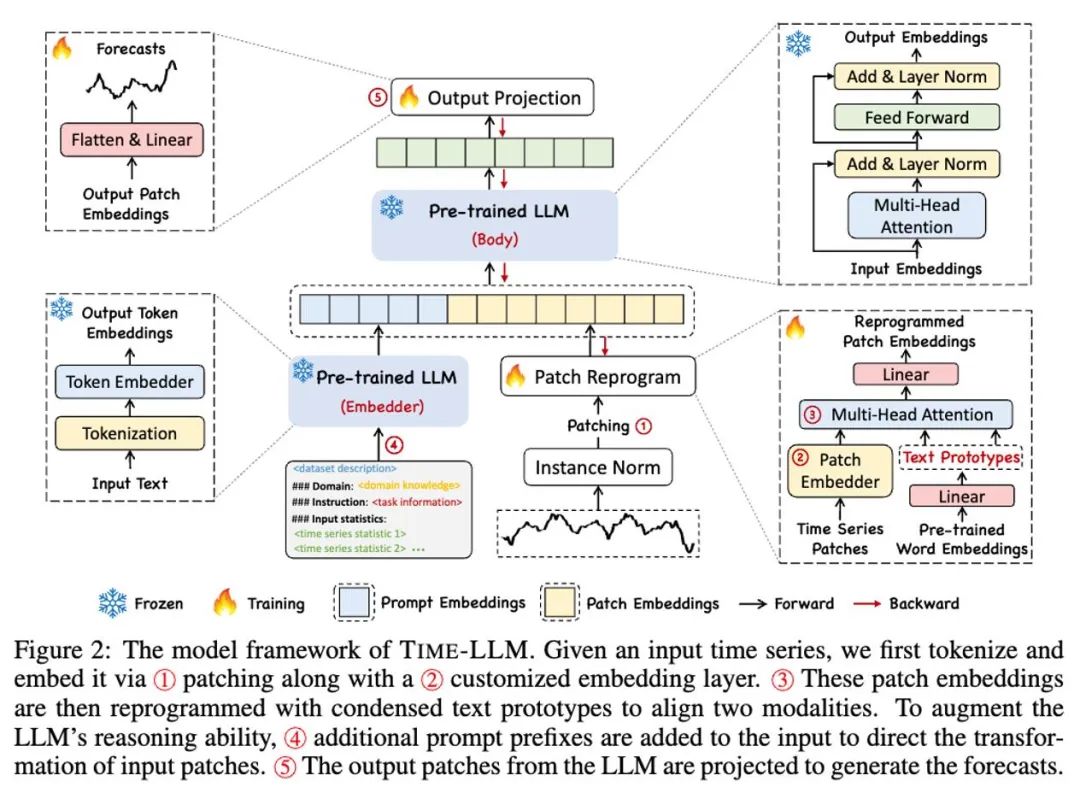
#上記のモデル枠組み図の①と②に示すように、入力時系列データ統合操作はまず RevIN を通じて洗練され、次に異なるパッチに分割され、潜在空間にマッピングされます。
時系列データとテキストデータでは表現方法に大きな違いがあり、異なるモダリティに属します。時系列を直接編集したり、自然言語でロスレスに記述したりすることはできないため、LLM に時系列の理解を直接促すには大きな課題が生じます。したがって、時間的入力特徴を自然言語テキスト領域に合わせる必要があります。
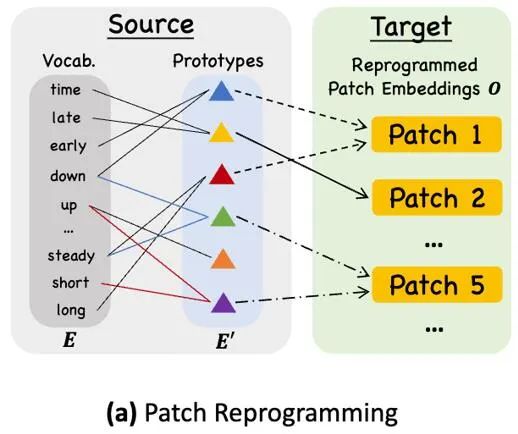
異なるモダリティを調整する一般的な方法は、モデル フレームワーク図の③に示すように、すべてのモダリティの埋め込みとタイミング入力機能を作成するだけです。単語のクロスアテンション (時系列入力特徴はクエリであり、すべての単語の埋め込みはキーと値です)。ただし、LLM に固有の語彙は非常に大きいため、時間的特徴をすべての単語に効果的に直接調整することはできません。また、すべての単語が時系列と意味関係を調整できるわけではありません。この問題を解決するために、この研究では、語彙の線形結合を実行して、元の語彙よりもはるかに少ないテキスト プロトタイプを取得します。この組み合わせは、次のような時系列データの変化する特性を表現するために使用できます。 「短期間の上昇または緩やかな下落」、図に示すように。
指定されたタイミングタスクでLLMの能力を完全に活性化するために、この研究では、モデルフレームワーク図の④に示すように、シンプルで効果的な方法であるプロンプトプレフィックスパラダイムを提案します。最近の進歩により、画像などの他のデータ パターンをキューのプレフィックスにシームレスに統合できることが示され、これらの入力に基づいた効率的な推論が可能になります。これらの発見に触発されて、著者らは、自分たちの方法を現実世界の時系列に直接適用できるようにするために、別の質問を提起しました。ヒントは、入力コンテキストを強化し、再プログラムされた時系列パッチの変換をガイドするプレフィックス情報として機能できるでしょうか?この概念は Prompt-as-Prefix (PaP) と呼ばれ、さらに、パッチの再プログラミングを補完しながら、下流のタスクに対する LLM の適応性が大幅に向上することを著者らは観察しました。平たく言えば、時系列データセットの事前情報をプレフィックスプロンプトとして自然言語の形式で入力し、それを整列された時系列特徴とつなぎ合わせて LLM に接続することを意味します。予測効果は向上しますか?
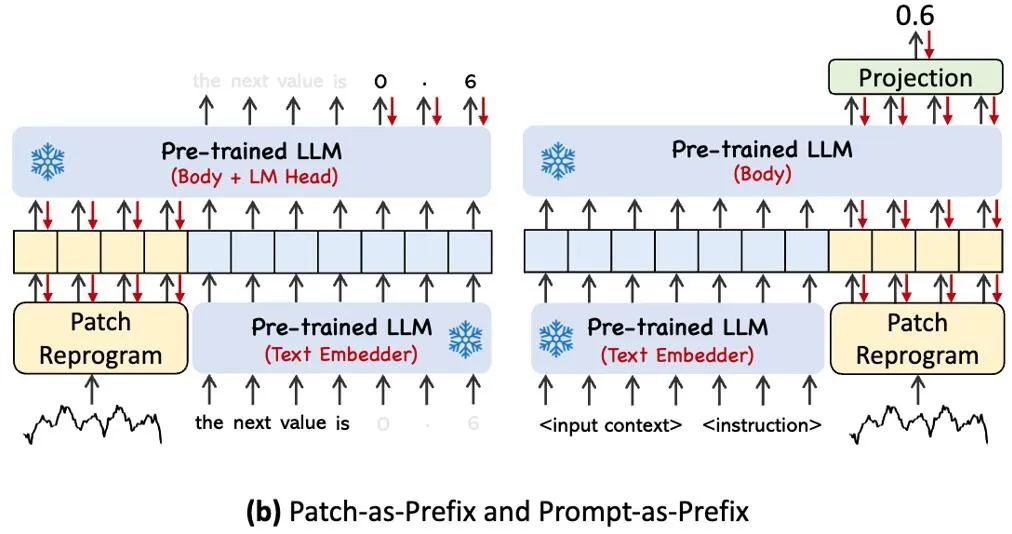
上の図は 2 つのプロンプト メソッドを示しています。 Patch-as-Prefix では、言語モデルは、自然言語で表現された時系列の後続の値を予測するように求められます。このアプローチにはいくつかの制約があります。(1) 外部ツールの支援なしで高精度の数値を処理する場合、言語モデルは感度が低いことがよくあり、長期予測タスクの正確な処理に重大な課題をもたらします。(2) 複雑なカスタマイズされた後処理。言語モデルが異なれば、言語モデルは異なるコーパスで事前トレーニングされ、高精度の数値を生成するときに異なる単語分割タイプを使用する可能性があるため、これらのモデルに必要です。その結果、予測は [‘0’, ‘.’, ‘6’, ‘1’] や 0.61 を表す [‘0’, ‘.’, ‘61’] など、さまざまな自然言語形式で表現されます。
実際に、著者らは効果的なプロンプトを構築するための 3 つの重要なコンポーネントを特定しました: (1) データセットのコンテキスト、(2) LLM をさまざまな下流タスクに適応させるためのタスクの指示、(3) 統計的記述。時間遅延などにより、LLM は時系列データの特性をよりよく理解できるようになります。以下の画像は、プロンプトの例を示しています。

#4. 実験結果
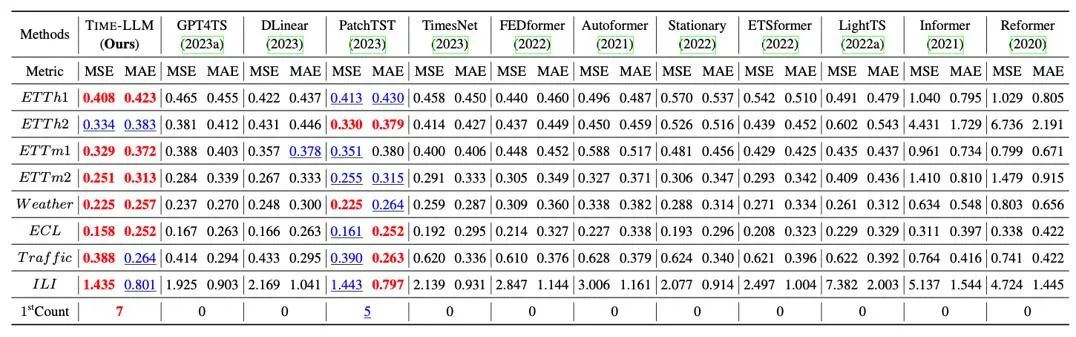
示されているように、8 つの古典的な公開データ セットに対して包括的なテストを実施しました。以下の表では、Time-LLM は、GPT-2 を直接使用する GPT4TS と比較して、ベンチマーク比較においてこれまでの最高の結果を大幅に上回っています。も大幅に改善されており、この方法の有効性が示されています。
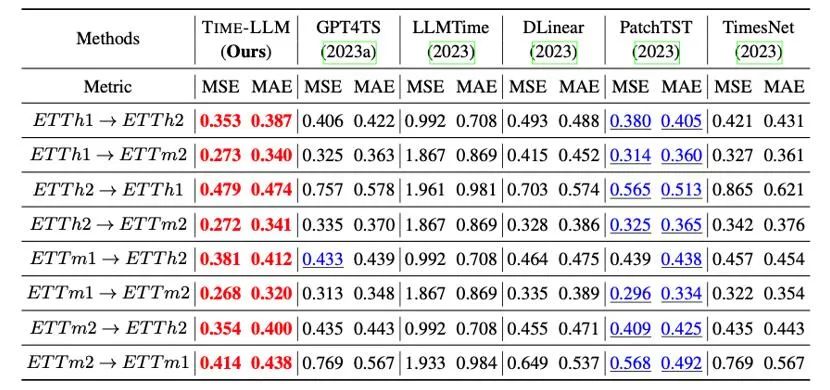
さらに、再プログラミングされた LLM のゼロショット学習能力を、再プログラミングの能力のおかげで、クロスドメイン適応の枠組み内で評価しました。以下の表に示すように、Time-LLM はゼロショット シナリオでも驚異的な予測効果を示します。
5. 概要
大規模言語モデル (LLM) の急速な開発により、人工知能のクロスアプリケーションが大幅に促進されました。 -モーダルシナリオが進歩し、多くの分野での幅広い応用が促進されます。ただし、LLM のパラメーターのスケールが大きく、主に自然言語処理 (NLP) シナリオを目的としたその設計は、クロスモーダルおよびクロスドメインのアプリケーションに多くの課題をもたらします。これを考慮して、テキストとシーケンスデータの間のクロスモーダルインタラクションを実現することを目的として、大規模モデルを再プログラミングするための新しいアイデアを提案し、この方法を大規模な時系列データおよび時空間データの処理に広く適用します。これにより、柔軟に踊る象のようにLLMがより幅広い応用シーンで強力な能力を発揮できるようにしたいと考えています。
興味のある友人は、論文 (https://arxiv.org/abs/2310.01728) を読むか、プロジェクト ページ (https://github.com/KimMeen/Time-LLM) にアクセスして詳細をご覧ください。 。
このプロジェクトは、Ant Group のインテリジェント エンジン部門の AI イノベーション研究開発部門である NextEvo から全面的なサポートを受けており、特に言語およびマシン インテリジェンス チームと、最適化インテリジェンス チーム。インテリジェント エンジン部門副社長の周君と最適化インテリジェンス チーム長の陸星宇のリーダーシップと指導の下、私たちは協力してこの重要な成果を無事に達成しました。
以上がゾウは踊れないなんて誰が言った? ICLR 2024 のクロスモーダル インタラクションのタイミング予測を実現するための大規模言語モデルの再プログラミングの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7480
7480
 15
1377
52
77
11
19
33
15
1377
52
77
11
19
33


 H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトを実行するには、次の手順が必要です。Webサーバー、node.js、開発ツールなどの必要なツールのインストール。開発環境の構築、プロジェクトフォルダーの作成、プロジェクトの初期化、コードの書き込み。開発サーバーを起動し、コマンドラインを使用してコマンドを実行します。ブラウザでプロジェクトをプレビューし、開発サーバーURLを入力します。プロジェクトの公開、コードの最適化、プロジェクトの展開、Webサーバーの構成のセットアップ。
 Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
GiteEpages静的Webサイトの展開が失敗しました:404エラーのトラブルシューティングと解像度Giteeを使用する
 Beego ormのモデルに関連付けられているデータベースを指定する方法は?
Apr 02, 2025 pm 03:54 PM
Beego ormのモデルに関連付けられているデータベースを指定する方法は?
Apr 02, 2025 pm 03:54 PM
Beegoormフレームワークでは、モデルに関連付けられているデータベースを指定する方法は?多くのBEEGOプロジェクトでは、複数のデータベースを同時に操作する必要があります。 Beegoを使用する場合...
 GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
大企業または有名なオープンソースプロジェクトによって開発されたGOのどのライブラリが開発されていますか? GOでプログラミングするとき、開発者はしばしばいくつかの一般的なニーズに遭遇します...
 H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページは、コードの脆弱性、ブラウザー互換性、パフォーマンスの最適化、セキュリティの更新、ユーザーエクスペリエンスの改善などの要因のため、継続的に維持する必要があります。効果的なメンテナンス方法には、完全なテストシステムの確立、バージョン制御ツールの使用、定期的にページのパフォーマンスの監視、ユーザーフィードバックの収集、メンテナンス計画の策定が含まれます。
 Redisストリームを使用してGO言語でメッセージキューを実装する場合、user_idタイプの変換の問題を解決する方法は?
Apr 02, 2025 pm 04:54 PM
Redisストリームを使用してGO言語でメッセージキューを実装する場合、user_idタイプの変換の問題を解決する方法は?
Apr 02, 2025 pm 04:54 PM
redisstreamを使用してGo言語でメッセージキューを実装する問題は、GO言語とRedisを使用することです...
 風光明媚なスポットコメント分析におけるJieba Wordセグメンテーションの精度を改善する方法は?
Apr 02, 2025 am 07:09 AM
風光明媚なスポットコメント分析におけるJieba Wordセグメンテーションの精度を改善する方法は?
Apr 02, 2025 am 07:09 AM
風光明媚なスポットコメント分析におけるJieba Wordセグメンテーションの問題を解決する方法は?風光明媚なスポットコメントと分析を行っているとき、私たちはしばしばJieba Wordセグメンテーションツールを使用してテキストを処理します...
