

DeepMind がトランスフォーマーをアップグレードし、フォワードパスの FLOP を最大半分に削減可能

ハイブリッドの深さを導入した DeepMind の新しい設計により、トランスの効率が大幅に向上します。



- #論文のタイトル: 深さの混合: トランスフォーマーベースの言語モデルでのコンピューティングの動的割り当て
- # #論文アドレス: https://arxiv.org/pdf/2404.02258.pdf
彼らは次のように構想しました: 各層で、ネットワークは意思決定を学習する必要がある利用可能なコンピューティング バジェットを動的に割り当てるために、トークンごとに作成されます。特定の実装では、総計算量は、ネットワークが動作する際の実行決定の関数ではなく、トレーニング前にユーザーによって設定され、変更されることはありません。これにより、ハードウェア効率の向上 (メモリ フットプリントの削減や順方向パスごとの FLOP の削減など) を事前に予測して活用することができます。チームの実験では、ネットワーク全体のパフォーマンスを損なうことなく、これらの利点を達成できることが示されています。
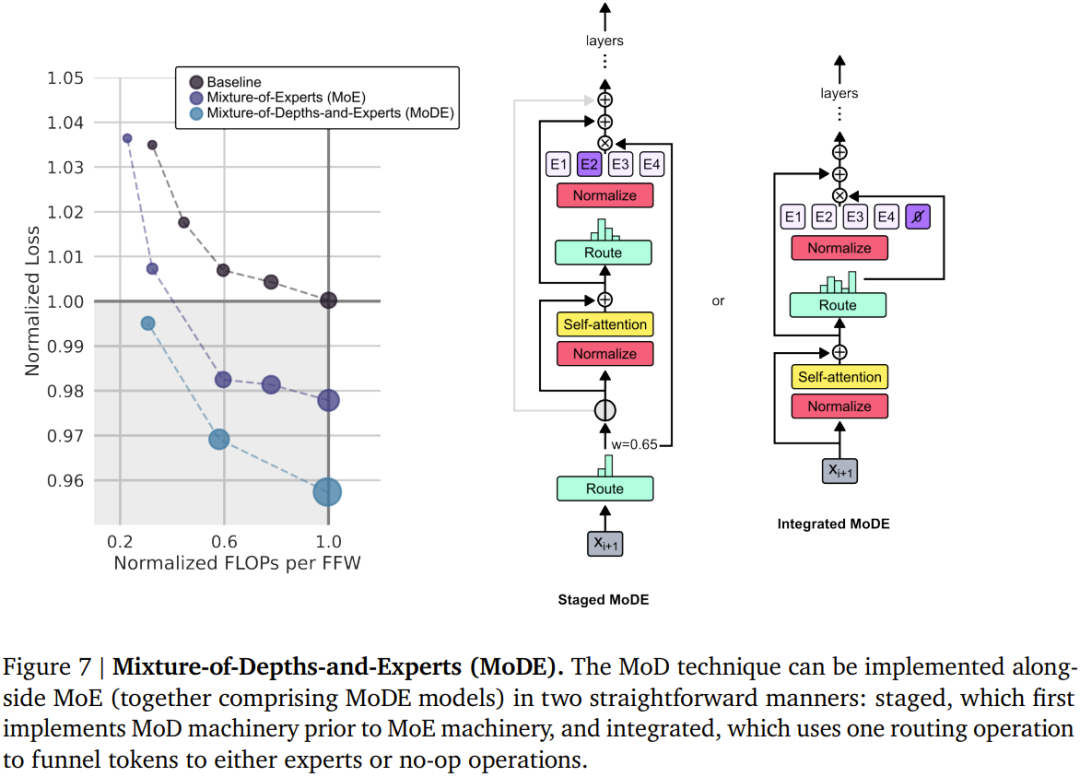
#DeepMind のチームは、Mixed Expert (MoE) Transformer と同様のアプローチを採用しており、動的なトークンレベルのルーティング決定がネットワーク深度全体にわたって実行されます。
MoE とは異なり、ここでの選択は、トークンに計算を適用するか (標準の Transformer と同じ)、残りの接続を介してトークンをラップするかです (変更せずにそのままにして、計算を保存します)。 MoE とのもう 1 つの違いは、このルーティング メカニズムが MLP とマルチヘッド アテンションの両方に使用されることです。したがって、これはネットワークによって処理されるキーとクエリにも影響するため、ルートはどのトークンが更新されるかだけでなく、どのトークンが注目に値するかを決定します。
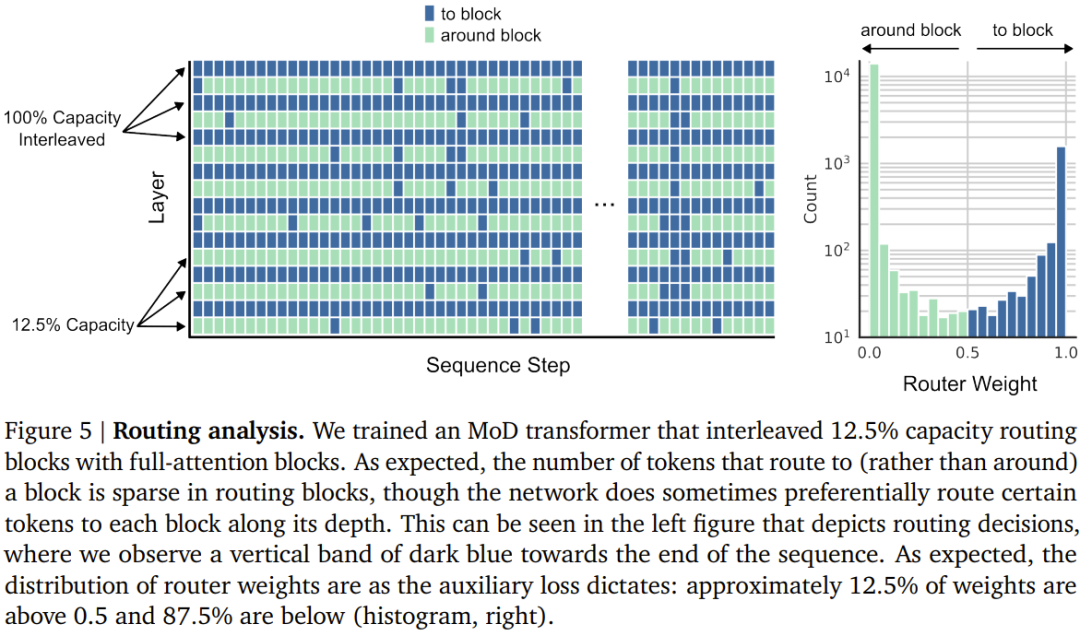
DeepMind は、各トークンが Transformer の深さで異なる数のレイヤーまたはモジュールを通過するという事実を強調するために、この戦略を Mixture-of-Depths (MoD) と名付けました。ここではこれを「混合の深さ」と訳します。図 1 を参照してください。
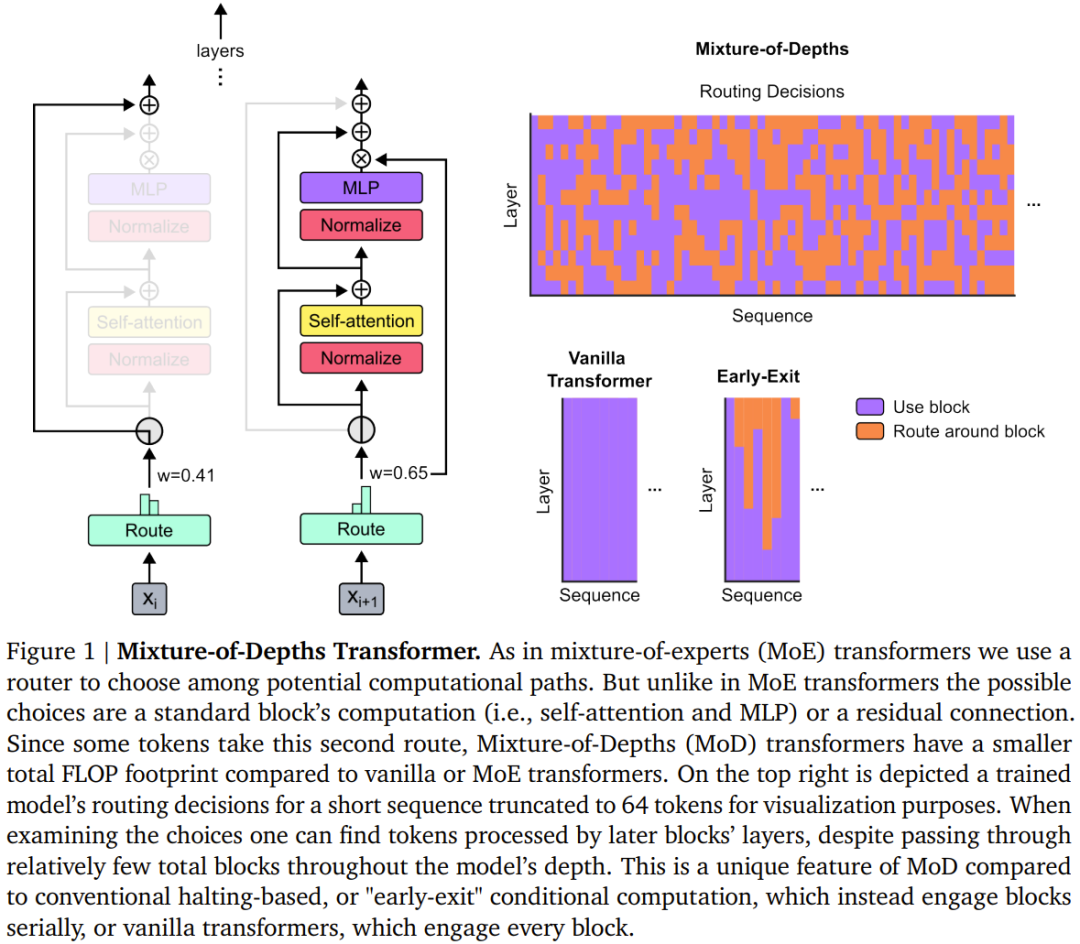 #MoD は、ユーザーがパフォーマンスと速度を比較検討できるようにサポートします。一方で、ユーザーは通常の Transformer と同じトレーニング FLOP で MoD Transformer をトレーニングでき、最終的な対数確率トレーニング ターゲットを最大 1.5% 向上させることができます。一方、MoD Transformer は、通常の Transformer と同じトレーニング損失を達成するために使用する計算量が少なく、フォワード パスあたりの FLOP が最大 50% 少なくなります。
#MoD は、ユーザーがパフォーマンスと速度を比較検討できるようにサポートします。一方で、ユーザーは通常の Transformer と同じトレーニング FLOP で MoD Transformer をトレーニングでき、最終的な対数確率トレーニング ターゲットを最大 1.5% 向上させることができます。一方、MoD Transformer は、通常の Transformer と同じトレーニング損失を達成するために使用する計算量が少なく、フォワード パスあたりの FLOP が最大 50% 少なくなります。 同等の通常の Transformer が必要とする計算量よりも少ない静的計算バジェットを設定します。これは、量を制限することによって行われます。シーケンス内の計算の数 モジュール計算 (つまり、セルフアテンション モジュールと後続の MLP) に参加できるトークンの数。たとえば、通常の Transformer ではシーケンス内のすべてのトークンがセルフ アテンション計算に参加することを許可できますが、MoD Transformer ではシーケンス内のトークンの 50% のみの使用を制限できます。 各トークンについて、スカラー重みを与えるルーティング アルゴリズムが各モジュールにあります。この重みは、各トークンのルーティング設定 (モジュールの計算に参加するかどうか) を表します。過去を回避するために。 各モジュールで、上位 k 個の最大スカラー重みを見つけます。それに対応するトークンがモジュールの計算に参加します。 k 個のトークンのみがこのモジュールの計算に参加する必要があるため、その計算グラフとテンソル サイズはトレーニング プロセス中は静的です。これらのトークンは、ルーティング アルゴリズムによって認識される動的でコンテキスト関連のトークンです。
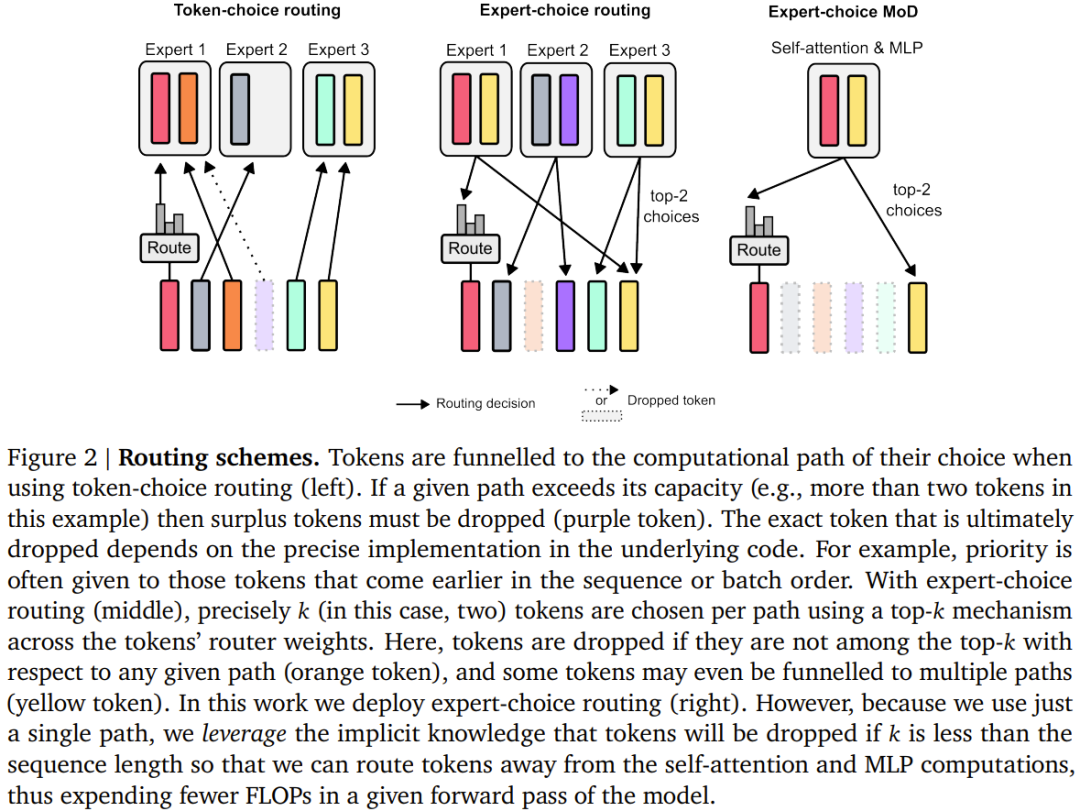
#第一に、補助的なバランスを失う必要がありません。
第 2 に、上位 k を選択する操作は配線の重みの大きさに依存するため、この配線スキームでは相対的な配線の重みを使用できるため、現在の配線の重みを決定するのに役立ちます。モジュール どのトークンが最も必要であるかを計算します。ルーティング アルゴリズムは、重みを適切に設定することで、最も重要なトークンが上位 k に含まれるように試みることができます。これは、トークン選択ルーティング スキームでは実行できないことです。特定の使用例では、本質的に null 操作である計算パスがあるため、重要なトークンを null にルーティングすることは避けるべきです。
第三に、ルーティングは 2 つのパスのみを通過するため、単一の top-k 操作でトークンを効率的に 2 つの相互排他的なセットに分割できます (それぞれがパスのセットを計算します)。 、上記の過剰または処理不足の問題に対処できます。
このルーティング スキームの具体的な実装については、元の論文を参照してください。
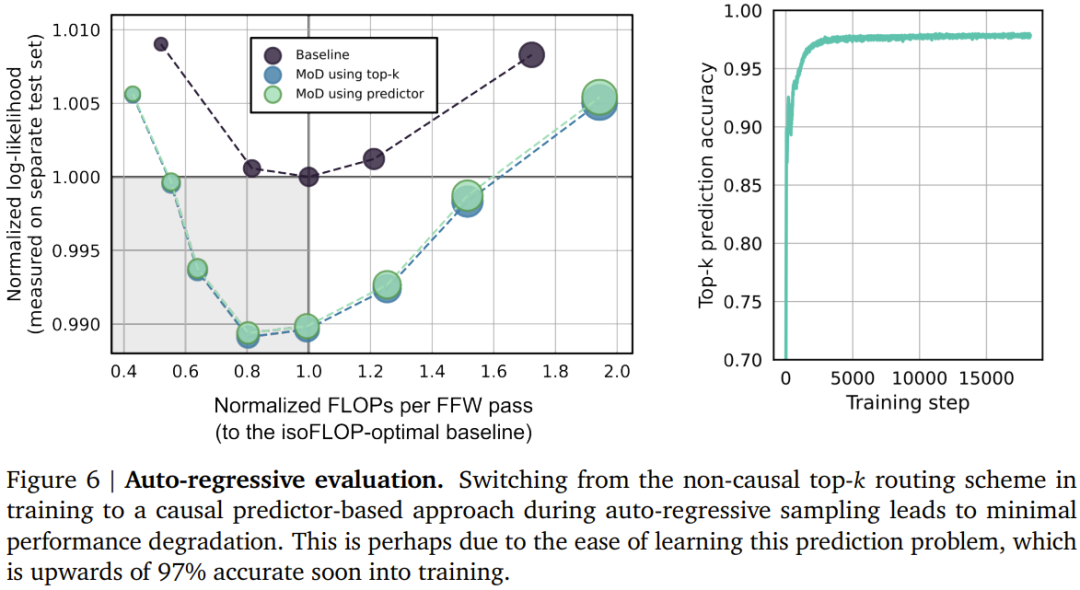
エキスパートによる選択ルーティングには多くの利点がありますが、明らかな問題もあります。 -k 操作は非因果的です。つまり、特定のトークンのルーティング重みが上位 k に入るかどうかは、その後のルーティング重みの値に依存しますが、自己回帰サンプリングを実行する場合、これらの重みを取得することはできません。
この問題を解決するために、チームは 2 つの方法をテストしました。
最初の方法は、単純な補助損失を導入することです。言語モデリングの主な目標に対するその影響は 0.2% ~ 0.3% であることが実践的に証明されていますが、これにより、モデルは自己回帰的にサンプリングします。彼らは、ルーティング アルゴリズムの出力がロジットを提供するバイナリ クロス エントロピー ロスを使用し、これらのロジットの上位 k を選択することでターゲットを提供できます (つまり、トークンが上位 k にある場合は 1、それ以外の場合は 1)。 0)。
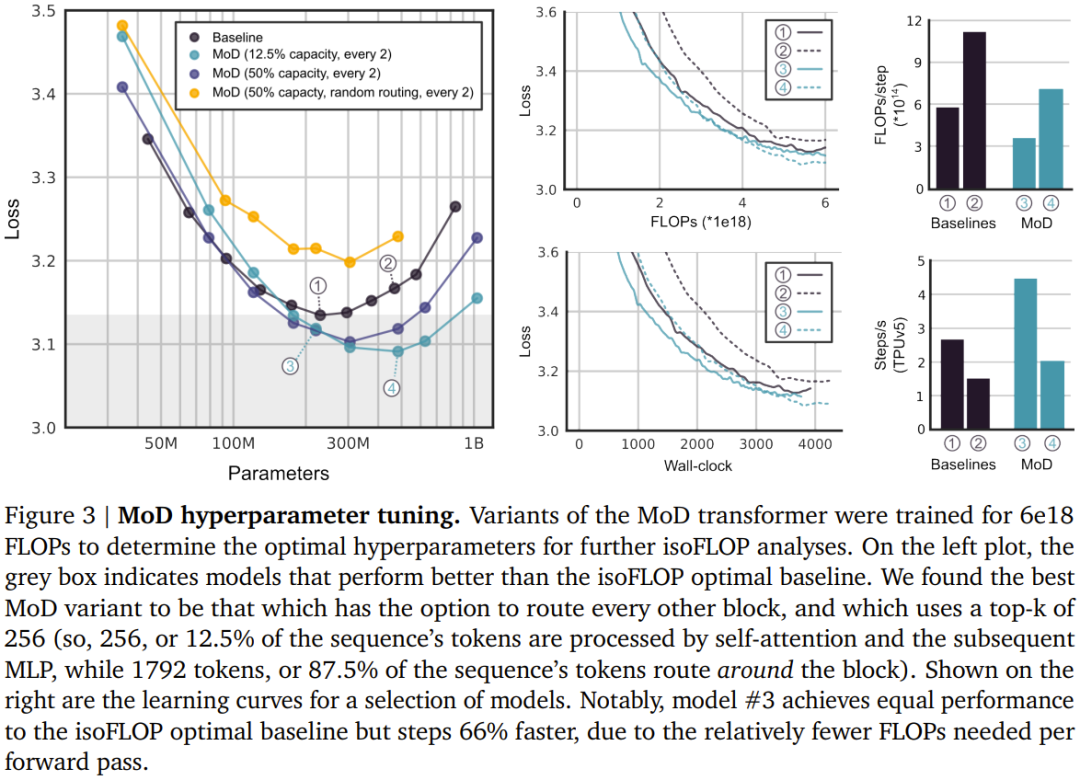
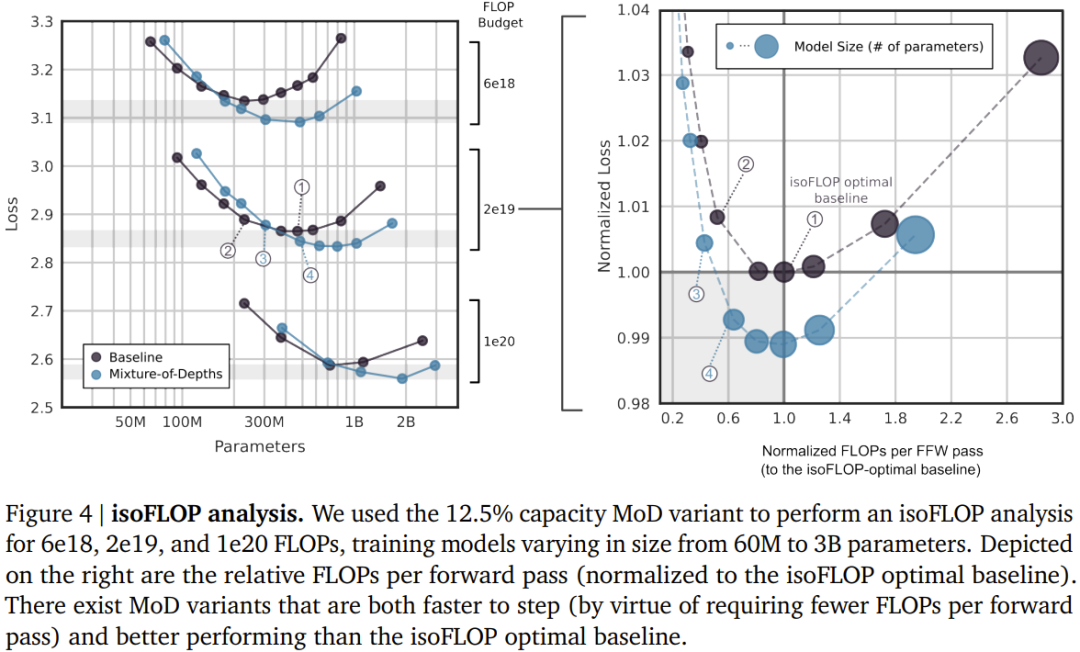
以上がDeepMind がトランスフォーマーをアップグレードし、フォワードパスの FLOP を最大半分に削減可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7721
7721
 15
1642
14
1396
52
1289
25
1233
29
15
1642
14
1396
52
1289
25
1233
29

 Gitプロジェクトをローカルにダウンロードする方法
Apr 17, 2025 pm 04:36 PM
Gitプロジェクトをローカルにダウンロードする方法
Apr 17, 2025 pm 04:36 PM
gitを介してローカルにプロジェクトをダウンロードするには、次の手順に従ってください。gitをインストールします。プロジェクトディレクトリに移動します。次のコマンドを使用してリモートリポジトリのクローニング:git clone https://github.com/username/repository-name.git
 gitでコードを更新する方法
Apr 17, 2025 pm 04:45 PM
gitでコードを更新する方法
Apr 17, 2025 pm 04:45 PM
GITコードを更新する手順:コードをチェックしてください:gitクローンhttps://github.com/username/repo.git最新の変更を取得:gitフェッチマージの変更:gitマージオリジン/マスタープッシュ変更(オプション):gitプッシュオリジンマスター
 gitコミットの使用方法
Apr 17, 2025 pm 03:57 PM
gitコミットの使用方法
Apr 17, 2025 pm 03:57 PM
GITコミットは、プロジェクトの現在の状態のスナップショットを保存するために、ファイルの変更をGITリポジトリに記録するコマンドです。使用方法は次のとおりです。一時的なストレージエリアに変更を追加する簡潔で有益な提出メッセージを書き込み、送信メッセージを保存して終了して送信を完了します。
 gitでコードをマージする方法
Apr 17, 2025 pm 04:39 PM
gitでコードをマージする方法
Apr 17, 2025 pm 04:39 PM
gitコードマージプロセス:競合を避けるために最新の変更を引き出します。マージするブランチに切り替えます。マージを開始し、ブランチをマージするように指定します。競合のマージ(ある場合)を解決します。ステージングとコミットマージ、コミットメッセージを提供します。
 Gitダウンロードがアクティブでない場合はどうすればよいですか
Apr 17, 2025 pm 04:54 PM
Gitダウンロードがアクティブでない場合はどうすればよいですか
Apr 17, 2025 pm 04:54 PM
解決:gitのダウンロード速度が遅い場合、次の手順を実行できます。ネットワーク接続を確認し、接続方法を切り替えてみてください。 GIT構成の最適化:ポストバッファーサイズ(Git Config -Global HTTP.Postbuffer 524288000)を増やし、低速制限(GIT Config -Global HTTP.LowsPeedLimit 1000)を減らします。 Gitプロキシ(Git-ProxyやGit-LFS-Proxyなど)を使用します。別のGitクライアント(SourcetreeやGithubデスクトップなど)を使用してみてください。防火を確認してください
 GITでリポジトリを削除する方法
Apr 17, 2025 pm 04:03 PM
GITでリポジトリを削除する方法
Apr 17, 2025 pm 04:03 PM
gitリポジトリを削除するには、次の手順に従ってください。削除するリポジトリを確認します。リポジトリのローカル削除:RM -RFコマンドを使用して、フォルダーを削除します。倉庫をリモートで削除する:倉庫の設定に移動し、「倉庫の削除」オプションを見つけて、操作を確認します。
 PHPプロジェクトで効率的な検索問題を解決する方法は?タイプセンスはあなたがそれを達成するのに役立ちます!
Apr 17, 2025 pm 08:15 PM
PHPプロジェクトで効率的な検索問題を解決する方法は?タイプセンスはあなたがそれを達成するのに役立ちます!
Apr 17, 2025 pm 08:15 PM
eコマースのウェブサイトを開発するとき、私は困難な問題に遭遇しました:大量の製品データで効率的な検索機能を達成する方法は?従来のデータベース検索は非効率的であり、ユーザーエクスペリエンスが低いです。いくつかの調査の後、私は検索エンジンタイプセンスを発見し、公式のPHPクライアントタイプセンス/タイプセンス-PHPを通じてこの問題を解決し、検索パフォーマンスを大幅に改善しました。
 Gitでローカルコードを更新する方法
Apr 17, 2025 pm 04:48 PM
Gitでローカルコードを更新する方法
Apr 17, 2025 pm 04:48 PM
ローカルGitコードを更新する方法は? Git Fetchを使用して、リモートリポジトリから最新の変更を引き出します。 Git Merge Origin/<リモートブランチ名>を使用して、地元のブランチへのリモート変更をマージします。合併から生じる競合を解決します。 Git Commit -M "Merge Branch< Remote Branch Name>"を使用してください。マージの変更を送信し、更新を適用します。
