

nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。

前書きと出発点
エンドツーエンドのパラダイムは、自動運転システムでマルチタスクを実現するために統一されたフレームワークを使用します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、動作の予測と計画が再考され、より合理的な動作計画のフレームワークが設計されます。困難な nuScenes データセット上で、SparseAD はエンドツーエンドのアプローチで最先端のフルタスク パフォーマンスを実現し、エンドツーエンド パラダイムとシングルタスク アプローチの間のパフォーマンス ギャップを削減します。
分野の背景
自動運転システムは、運転の安全性と快適性を確保するために、複雑な運転シナリオにおいて正しい判断を下す必要があります。通常、自動運転システムは、検出、追跡、オンライン マッピング、動作予測、計画などの複数のタスクを統合します。図 1a に示すように、従来のモジュラー パラダイムは、複雑なシステムを複数の個別のタスクに分割し、それぞれが個別に最適化されます。このパラダイムでは、独立した単一タスク モジュール間で手動の後処理が必要となり、プロセス全体がより煩雑になります。一方で、スタックされたタスク間でシーン情報の圧縮が失われるため、システム全体のエラーが蓄積し、潜在的な安全上の問題につながる可能性があります。
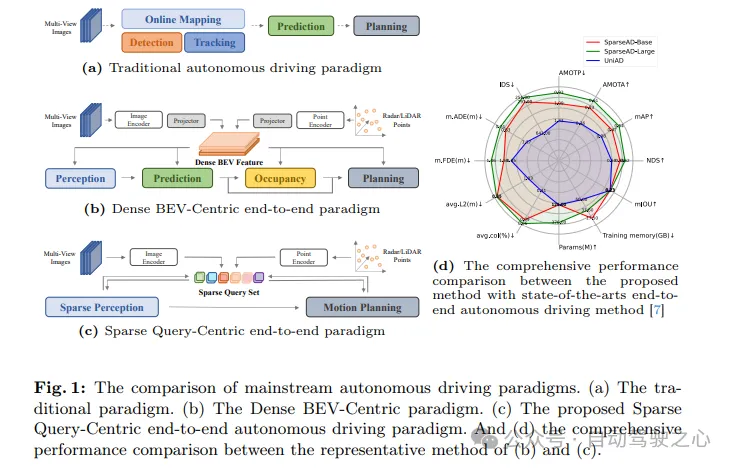
上記の問題に関して、エンドツーエンドの自動運転システムは生のパーセプトロン データを入力として受け取り、より簡潔な方法で計画結果を返します。初期の研究では、中間タスクをスキップし、生のパーセプトロン データから直接計画結果を予測することが提案されていました。このアプローチはより単純ですが、モデルの最適化、解釈可能性、および計画のパフォーマンスの点で満足のいくものではありません。より優れた解釈性を備えたもう 1 つの多面的なパラダイムは、自動運転の複数の部分をモジュール式のエンドツーエンド モデルに統合することです。これにより、多次元の監視が導入され、複雑な運転シナリオの理解が向上し、マルチタスクの機能がもたらされます。
図 1b に示すように、最も先進的なモジュラー エンドツーエンド手法では、運転シナリオ全体が、マルチセンサーと時間情報を含む鳥瞰図 (BEV) 機能の高密度の集合によって特徴付けられます。 、センシング、予測、計画などのフルスタック ドライバー タスクへの入力として機能します。高密度に集約された BEV の機能は、空間と時間を超えてマルチモダリティとマルチタスクを実現する上で重要な役割を果たしますが、BEV 表現を使用したこれまでのエンドツーエンドの手法は、高密度 BEV 中心のパラダイムとして要約されています。これらの手法の単純さと解釈のしやすさにもかかわらず、自動運転の各サブタスクにおけるパフォーマンスは、対応するシングルタスク手法に比べて依然として大幅に遅れています。さらに、Dense BEV-Centric パラダイムの下では、長期的な時間的融合とマルチモーダル フュージョンは主に複数の BEV 特徴マップを通じて実現されます。これにより、コンピューティング コストとメモリ使用量が大幅に増加し、実際のシステムに大きな負担をもたらします。展開。
ここでは、新しいスパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) を提案します。このパラダイムでは、図 1c に示すように、運転シーン全体の空間要素と時間要素がスパース ルックアップ テーブルによって表され、従来の高密度アンサンブル鳥瞰図 (BEV) 機能が放棄されます。このスパース表現により、エンドツーエンド モデルはより長い履歴情報をより効率的に利用し、計算コストとメモリ フットプリントを大幅に削減しながら、より多くのモードやタスクに拡張できるようになります。
モジュール式のエンドツーエンド アーキテクチャが再設計され、スパース センシングとモーション プランナーで構成される簡潔な構造に簡素化されました。スパース知覚モジュールでは、ユニバーサル時間デコーダを利用して、検出、追跡、オンライン マッピングなどの知覚タスクを統合します。このプロセスでは、マルチセンサーの特徴と履歴記録がトークンとして扱われ、オブジェクト クエリとマップ クエリはそれぞれ運転シーン内の障害物と道路要素を表します。モーション プランナーでは、まばらな知覚クエリが環境表現として使用され、マルチモーダル モーション予測が車両と周囲のエージェントに対して同時に実行され、自車両の複数の初期計画ソリューションが取得されます。その後、多次元の運転制約が十分に考慮されて、最終的な計画結果が生成されます。
主な貢献:
- は、新しいスパース クエリ中心のエンドツーエンド自動運転パラダイム (SparseAD) を提案します。これは、従来の高密度鳥瞰図 (BEV) 表現方法を放棄するため、効率的にスケーリングできる大きな可能性を秘めています。より多くのモダリティとタスクに。
- モジュール式のエンドツーエンド アーキテクチャを、スパース センシングとモーション プランニングの 2 つの部分に簡素化します。スパース知覚部分では、検出、追跡、オンライン マッピングなどの知覚タスクが完全にスパースな方法で統合され、動作計画部分では、より合理的なフレームワークの下で動作の予測と計画が実行されます。
- 困難な nuScenes データセット上で、SparseAD はエンドツーエンド方式の中で最先端のパフォーマンスを達成し、エンドツーエンド パラダイムとシングルタスク方式の間のパフォーマンス ギャップを大幅に縮小します。これは、提案されたスパース エンドツーエンド パラダイムの大きな可能性を十分に示しています。 SparseAD は、自動運転システムのパフォーマンスと効率を向上させるだけでなく、将来の研究と応用に新たな方向性と可能性をもたらします。
SparseAD ネットワーク構造
図 1c に示すように、提案されているスパース クエリ中心のパラダイムでは、さまざまなスパース クエリが全体を完全に表します。モジュール間の情報転送と相互作用を担当するだけでなく、エンドツーエンドの最適化のためにマルチタスクで逆勾配を伝播します。以前の高密度セット鳥瞰図 (BEV) 中心の方法とは異なり、SparseAD ではビュー投影と高密度 BEV 機能が使用されないため、大きな計算負荷とメモリ負荷が回避されます。SparseAD の詳細なアーキテクチャを図 2 に示します。
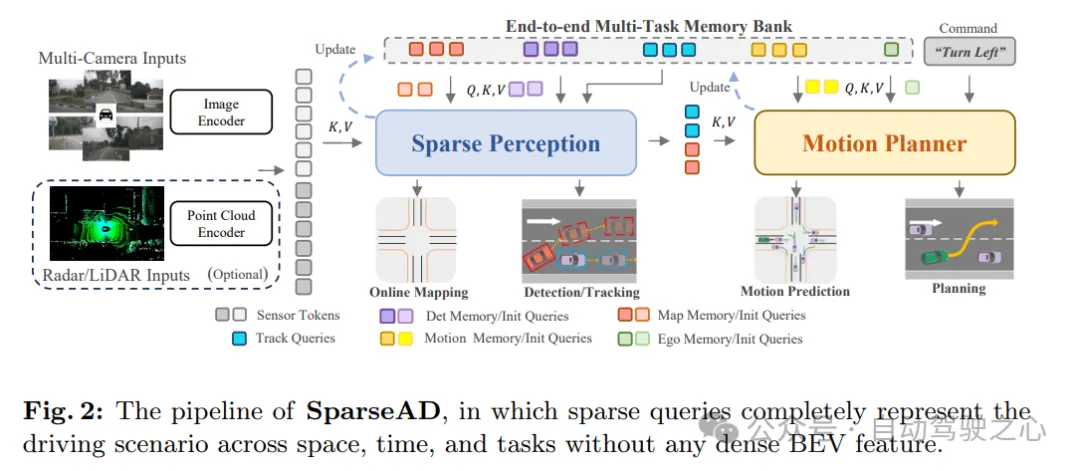
アーキテクチャ図を見ると、SparseAD は主に、センサー エンコーダー、スパース知覚、モーション プランナーの 3 つの部分で構成されています。具体的には、センサー エンコーダーは、マルチビュー カメラ画像、レーダーまたはライダー ポイントを入力として受け取り、それらを高次元の特徴にエンコードします。これらの特徴は、位置埋め込み (PE) とともにセンサー トークンとしてスパース センシング モジュールに入力されます。スパース センシング モジュールでは、センサーからの生データが、検出クエリ、追跡クエリ、地図クエリなどのさまざまなスパース センシング クエリに集約され、それぞれ運転シーンのさまざまな要素を表し、さらに下流のタスクに伝播されます。 。モーション プランナーでは、認識クエリは運転シーンのまばらな表現として扱われ、周囲のすべてのエージェントと自車に対して完全に活用されます。同時に、安全で動的に準拠した最終計画を生成するために、複数の運転制約が考慮されます。
さらに、エンドツーエンドのマルチタスク メモリ ライブラリがアーキテクチャに導入され、運転シーン全体のタイミング情報を均一に保存することで、システムは長期データの集約から恩恵を受けることができます。フルスタックの駆動タスクを完了するための履歴情報。
図 3 に示すように、SparseAD のスパース認識モジュールは、検出、追跡、オンライン マッピングなどの複数の認識タスクをスパースな方法で統合します。具体的には、メモリ バンクからの長期履歴情報を活用する、構造的に同一の時間デコーダが 2 つあります。デコーダの 1 つは障害物の検知に使用され、もう 1 つはオンライン マッピングに使用されます。
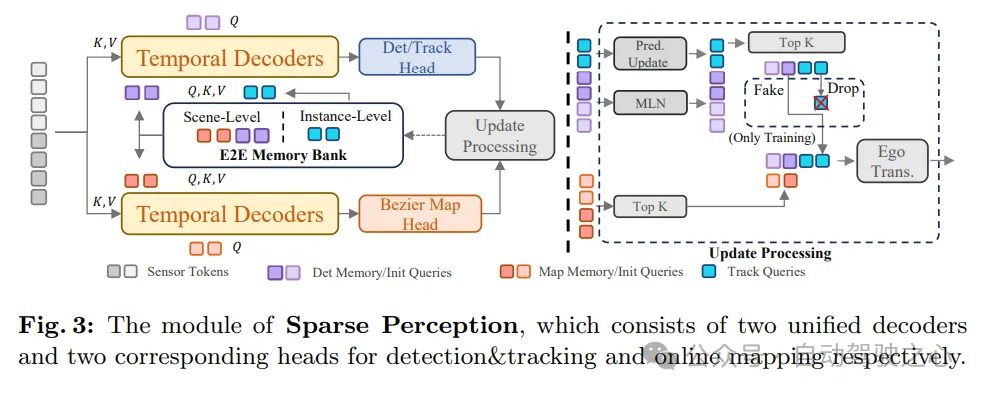
さまざまなタスクに対応する認識クエリを通じて情報を集約した後、検出および追跡ヘッドとマップ部分を使用して障害物とマップ要素をそれぞれデコードおよび出力します。その後、更新プロセスが実行され、現在のフレームの信頼度の高いセンシング クエリをフィルタリングして保存し、それに応じてメモリ バンクを更新します。これは、次のフレームのセンシング プロセスに利益をもたらします。
このようにして、SparseAD のスパース認識モジュールは、運転シーンの効率的かつ正確な認識を実現し、その後の動作計画に重要な情報基盤を提供します。同時に、メモリバンク内の履歴情報を利用することで、モジュールは知覚の精度と安定性をさらに向上させ、自動運転システムの信頼性の高い動作を保証します。
スパース知覚
障害物の知覚に関しては、統合されたデコーダ内で共同検出と追跡が採用されており、追加の手動後処理は必要ありません。検出クエリと追跡クエリの間には大きな不均衡があり、検出パフォーマンスの大幅な低下につながる可能性があります。上記の問題を軽減するために、多角度からの障害物検知の性能が向上しました。まず、フレーム間で時間情報を伝播するために 2 レベルのメモリ メカニズムが導入されます。その中で、シーンレベルのメモリはフレーム間の相関関係を持たずにクエリ情報を維持し、インスタンスレベルのメモリは追跡障害物の隣接するフレーム間の対応関係を維持します。第 2 に、2 つの異なる起源とタスクを考慮して、シーン レベルとインスタンス レベルのメモリには異なる更新戦略が採用されます。具体的には、シーン レベルのメモリは MLN 経由で更新され、インスタンス レベルのメモリは各障害物の将来の予測で更新されます。さらに、トレーニング プロセス中に、2 つのメモリ レベル間の監視のバランスをとるために、クエリの追跡に拡張戦略も採用され、それによって検出と追跡のパフォーマンスが向上します。その後、頭部を検出および追跡することで、属性および一意の ID を含む 3D 境界ボックスを検出または追跡クエリからデコードし、さらに下流のタスクで使用できます。
オンライン マップの構築は複雑かつ重要な作業です。現在の知識によれば、既存のオンライン マップ構築方法は、ほとんどが運転環境を表す高密度鳥瞰図 (BEV) 機能に依存しています。このアプローチでは、大量のメモリとコンピューティング リソースが必要となるため、センシング範囲を拡張したり、履歴情報を活用したりすることが困難です。私たちは、すべてのマップ要素はスパース方式で表現できると強く信じているため、スパース パラダイムの下でオンライン マップの構築を完了しようとしています。具体的には、障害物認識タスクと同じ時間デコーダ構造が採用されます。最初に、以前のカテゴリを含むマップ クエリが、運転平面上に均一に分散されるように初期化されます。テンポラル デコーダでは、マップ クエリがセンサー マーカーおよび履歴メモリ マーカーと対話します。これらの履歴メモリ マーカーは、実際には、以前のフレームからの信頼性の高いマップ クエリで構成されています。更新されたマップ クエリには、現在のフレームのマップ要素に関する有効な情報が含まれ、将来のフレームまたはダウンストリーム タスクで使用するためにメモリ バンクにプッシュできます。
明らかに、オンライン マップ構築のプロセスは障害物の認識とほぼ同じです。つまり、検出、追跡、オンライン マップ構築を含むセンシング タスクは、より大きな範囲 (100m × 100m など) または長期融合に拡張する場合により効率的であり、複雑な操作を必要としない共通のスパース アプローチに統合されます。 (変形可能なアテンションや多点アテンションなど)。私たちの知る限り、これは統一された認識アーキテクチャでオンライン マップ構築をまばらな方法で実装した最初の例です。その後、区分的ベジェ マップ Head を使用して、各スパース マップ要素の区分的ベジェ コントロール ポイントを返します。これらのコントロール ポイントは、下流タスクの要件を満たすように簡単に変換できます。
Motion Planner
私たちは、自動運転システムにおける動きの予測と計画の問題を再検討しました。その結果、これまでの多くの方法では、周囲の動きを予測する際にこの問題が無視されていたことがわかりました。自我車両のダイナミクス。ほとんどの状況ではこれは明らかではありませんが、近くの車両とホスト車両の間で密接な相互作用が存在する交差点などのシナリオでは、潜在的なリスクとなる可能性があります。これに触発されて、より合理的な動作計画フレームワークが設計されました。このフレームワークでは、動き予測器が周囲の車両と自車両の動きを同時に予測します。その後、自車両の予測結果は、後続のプランニング オプティマイザーでモーション事前分布として使用されます。計画プロセス中に、安全性と力学要件の両方を満たす最終的な計画結果を生み出すために、制約のさまざまな側面を考慮します。
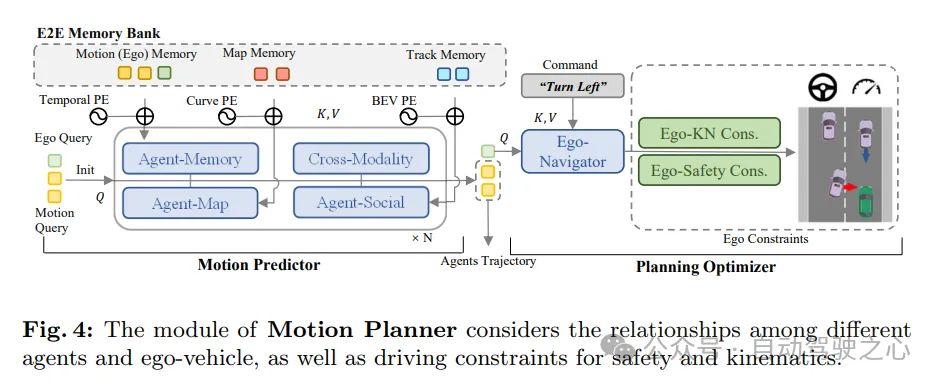
図 4 に示すように、SparseAD のモーション プランナーは、認識クエリ (軌跡クエリや地図クエリを含む) を現在の運転シーンのまばらな表現として処理します。マルチモーダル モーション クエリは、運転シナリオの理解、すべての車両 (自車両を含む) 間の相互作用の認識、および将来のさまざまな可能性のゲームを可能にする媒体として使用されます。次に、車両のマルチモーダル モーション クエリがプランニング オプティマイザーに入力され、高レベルの指示、安全性、ダイナミクスなどの運転上の制約が考慮されます。
動き予測器。以前の方法に従って、モーション クエリと現在の運転シーン表現 (軌跡クエリや地図クエリを含む) の間の認識と統合は、標準のトランスフォーマー レイヤーを通じて実現されます。さらに、自己車両エージェントとクロスモーダル相互作用を適用して、将来の時空間シーンにおける周囲のエージェントと自己車両間の相互作用を共同モデル化します。多層スタッキング構造内および多層スタッキング構造間のモジュール相乗効果を通じて、モーション クエリは静的環境と動的環境の両方から豊富なセマンティック情報を集約できます。
上記に加えて、動き予測器のパフォーマンスをさらに向上させるために 2 つの戦略も導入されています。まず、周囲のエージェントの動作クエリの初期化の一部として、軌道クエリのインスタンス レベルの一時メモリを使用して、単純かつ直接的な予測が行われます。このようにして、動き予測機能は上流のタスクから得られた事前知識から恩恵を受けることができます。第 2 に、エンドツーエンドのメモリ ライブラリのおかげで、ほとんど無視できるコストで、エージェント メモリ アグリゲータを介して、保存された履歴モーション クエリからストリーミング方式で有用な情報を同化できます。
この車両のマルチモーダル モーション クエリも同時に更新されることに注意してください。これにより、自車両の事前運動を取得することができ、計画学習をさらに容易にすることができる。
計画オプティマイザー。動き予測器によって提供される動き事前予測を使用すると、より適切な初期化が得られ、トレーニング中の迂回が少なくなります。モーション プランナーの重要なコンポーネントとして、コスト関数の設計は最終パフォーマンスの品質に大きな影響を与え、さらには決定するため、非常に重要です。提案された SparseAD モーション プランナーでは、満足のいく計画結果を生成することを目的として、安全性とダイナミクスという 2 つの主要な制約が主に考慮されます。具体的には、VAD で決定された制約に加えて、車両と近くのエージェントの間の動的安全関係にも焦点を当て、将来の瞬間におけるそれらの相対位置を考慮します。たとえば、エージェント i が車両に対して左前方エリアに留まり続け、車両が左に車線変更できない場合、エージェント i は左ラベルを取得し、エージェント i が車両に左方向の制約を課していることを示します。 。したがって、拘束は縦方向では前、後ろ、またはなしとして分類され、横方向では左、右、またはなしとして分類されます。プランナーでは、対応するクエリから他のエージェントと車両との水平方向および垂直方向の関係を解読します。このプロセスには、これらの方向における他のエージェントと自身の車両の間のすべての制約の確率を決定することが含まれます。次に、焦点損失をエゴ エージェント関係 (EAR) のコスト関数として利用して、近くのエージェントによってもたらされる潜在的なリスクを効果的に捕捉します。制御に従う システム実行の動的法則により、モーション プランナーに補助タスクが埋め込まれ、車両の動的状態の学習が促進されます。 Qego にクエリを実行して、自分の車両から速度、加速度、ヨー角などの状態をデコードし、ダイナミクス損失を使用してこれらの状態を監視します:
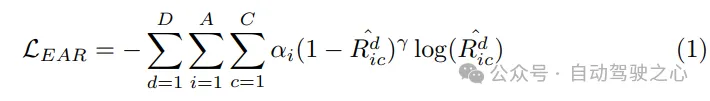
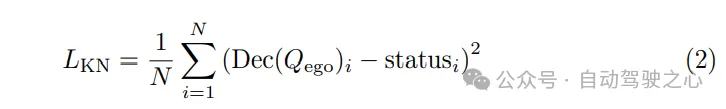
nuScenes 検証データセットでの 3D 検出と 3D マルチターゲット追跡の結果は次のとおりです。 「追跡のみのメソッド」とは、後処理相関を通じて追跡されるメソッドを指します。 「エンドツーエンドの自動運転方式」とは、フルスタックの自動運転タスクが可能な方式を指します。表内のすべてのメソッドは、フル解像度の画像入力を使用して評価されます。 †: 結果は公式のオープンソース コードを通じて再現されます。 -R: レーダー点群入力が使用されることを示します。
オンラインマッピング方式との性能比較は、[1.0m、1.5m、2.0m]の閾値で評価した結果です。 ‡: 公式オープンソース コードを通じて再現された結果。 †: SparseAD の計画モジュールのニーズに基づいて、境界を道路セグメントと車線にさらに細分化し、それらを個別に評価しました。 ※:バックボーンネットワークとスパースセンシングモジュールのコスト。 -R: レーダー点群入力が使用されることを示します。
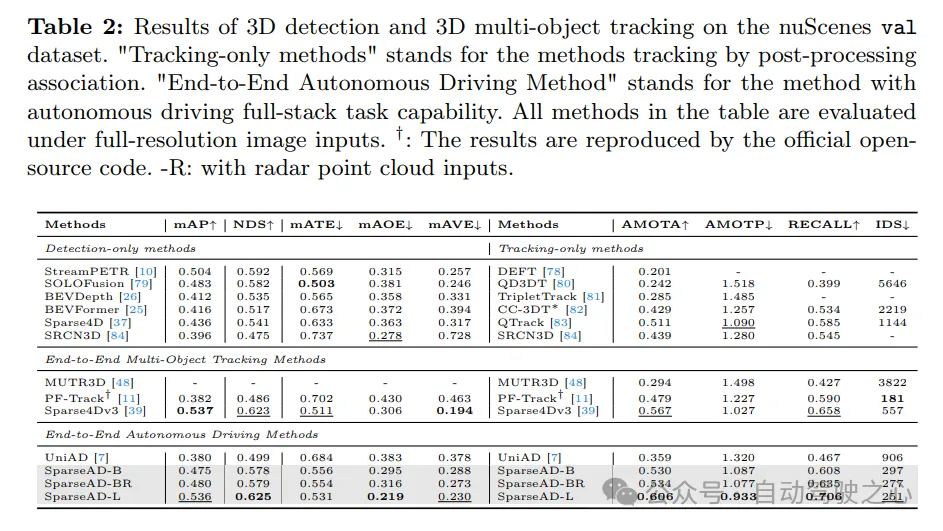

障害物の認識。 SparseAD の検出および追跡パフォーマンスは、表 2 の nuScenes 検証セットで他の方法と比較されます。明らかに、SparseAD-B は、最も一般的な検出のみ、追跡のみ、およびエンドツーエンドのマルチオブジェクト追跡手法で優れたパフォーマンスを発揮し、対応するタスクでは StreamPETR や QTrack などの SOTA 手法と同等のパフォーマンスを発揮します。より高度なバックボーン ネットワークでスケールアップすることにより、SparseAD-Large は全体的に優れたパフォーマンスを実現し、mAP が 53.6%、NDS が 62.5%、AMOTA が 60.6% となり、これまでの最良の方法である Sparse4Dv3 よりも全体的に優れています。
オンライン マッピング。表 3 は、nuScenes 検証セットでの SparseAD と他の以前の方法との間のオンライン マッピング パフォーマンスの比較結果を示しています。計画のニーズに応じて、境界を道路セグメントと車線に細分化し、それらを個別に評価すると同時に、障害物の認識と一致させるために範囲を通常の 60m × 30m から 102.4m × 102.4m に拡張したことを指摘しておく必要があります。 SparseAD は、公平性を失うことなく、高密度の BEV 表現を使用せずにスパースなエンドツーエンド方式で 34.2% の mAP を達成します。これは、パフォーマンスの点で、HDMapNet、VectorMapNet、MapTR などの以前に普及していた最も一般的な方法よりも優れています。トレーニング費用とコストの観点から。パフォーマンスは StreamMapNet よりわずかに劣りますが、私たちの方法は、高密度の BEV 表現を使用せずに均一な疎な方法でオンライン マッピングを実行できることを示しており、これは大幅に低コストでのエンドツーエンドの自動運転の実用的な展開に影響を及ぼします。確かに、他のモダリティ (レーダーなど) からの有用な情報を効果的に利用する方法は、さらに検討する価値のある課題です。まばらなやり方でもまだまだ模索の余地はあると考えています。
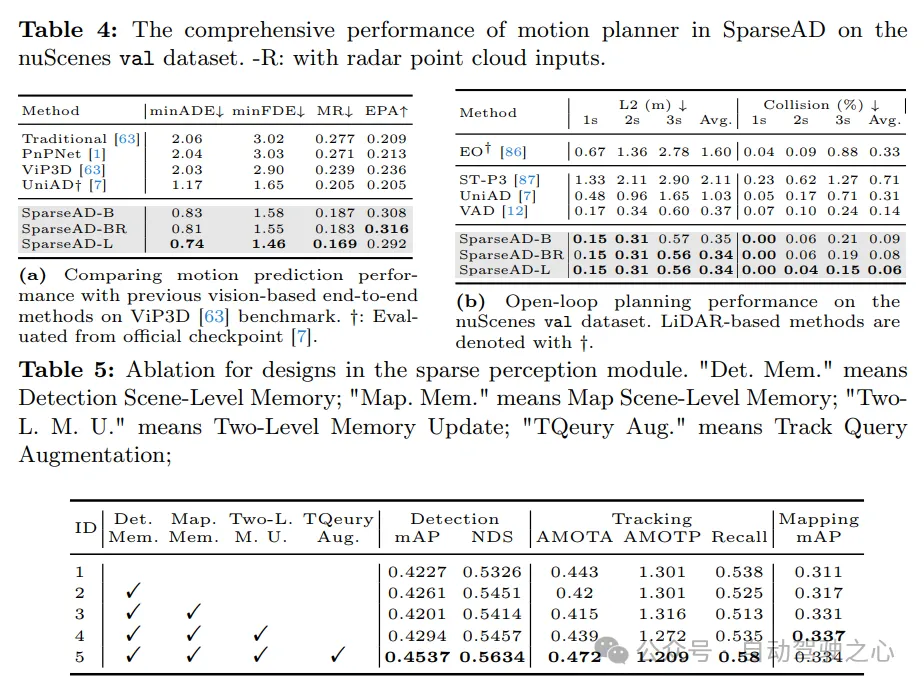
動き予測。動き予測の比較結果を表 4a に示します。指標は VIP3D と一致しています。 SparseAD は、すべてのエンドツーエンド方式の中で最高のパフォーマンスを達成し、最低 0.83 万 minADE、158 万 minFDE、18.7% のミス率、最高 0.308 EPA であり、これは大きな利点です。さらに、スパース クエリ センター パラダイムの効率性とスケーラビリティのおかげで、SparseAD はより多くのモダリティに効果的に拡張でき、高度なバックボーン ネットワークの恩恵を受けて、予測パフォーマンスをさらに大幅に向上させることができます。
計画。計画の結果を表 4b に示します。上流の認識モジュールとモーション プランナーの優れた設計のおかげで、SparseAD のすべてのバージョンは、nuScenes 検証データセットで最先端のパフォーマンスを実現します。具体的には、SparseAD-B は、UniAD や VAD を含む他のすべての方法と比較して、最低の平均 L2 エラーと衝突率を達成しており、これは私たちのアプローチとアーキテクチャの優位性を示しています。障害物の認識や動作予測などの上流のタスクと同様に、SparseAD はレーダーやより強力なバックボーン ネットワークを使用してパフォーマンスをさらに向上させます。

以上がnuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 Xiaohonshu でメモリをクリーニングする詳細な手順
Apr 26, 2024 am 10:43 AM
Xiaohonshu でメモリをクリーニングする詳細な手順
Apr 26, 2024 am 10:43 AM
1. 小紅書を開き、右下隅の「自分」をクリックします。 2. 設定アイコンをクリックし、「一般」をクリックします。 3. 「キャッシュのクリア」をクリックします。
 Huawei端末のメモリが足りない場合の対処法(メモリ不足の問題を解決する実践的な方法)
Apr 29, 2024 pm 06:34 PM
Huawei端末のメモリが足りない場合の対処法(メモリ不足の問題を解決する実践的な方法)
Apr 29, 2024 pm 06:34 PM
ファーウェイ携帯電話のメモリ不足は、モバイルアプリケーションやメディアファイルの増加に伴い、多くのユーザーが直面する一般的な問題となっています。ユーザーが携帯電話のストレージ容量を最大限に活用できるように、この記事では、Huawei 携帯電話のメモリ不足の問題を解決するためのいくつかの実用的な方法を紹介します。 1. キャッシュのクリーンアップ: 履歴レコードと無効なデータを削除してメモリ領域を解放し、アプリケーションによって生成された一時ファイルをクリアします。 Huawei携帯電話の設定で「ストレージ」を見つけ、「キャッシュのクリア」をクリックし、「キャッシュのクリア」ボタンを選択してアプリケーションのキャッシュファイルを削除します。 2. 使用頻度の低いアプリケーションをアンインストールする: メモリ領域を解放するには、使用頻度の低いアプリケーションをいくつか削除します。電話画面の上部にドラッグし、削除したいアプリケーションの「アンインストール」アイコンを長押しして、確認ボタンをクリックするとアンインストールが完了します。 3.モバイルアプリへ
 Deepseekをローカルで微調整する方法
Feb 19, 2025 pm 05:21 PM
Deepseekをローカルで微調整する方法
Feb 19, 2025 pm 05:21 PM
Deepseekクラスモデルのローカル微調整は、コンピューティングリソースと専門知識が不十分であるという課題に直面しています。これらの課題に対処するために、次の戦略を採用できます。モデルの量子化:モデルパラメーターを低精度の整数に変換し、メモリフットプリントを削減します。小さなモデルを使用してください。ローカルの微調整を容易にするために、より小さなパラメーターを備えた前提型モデルを選択します。データの選択と前処理:高品質のデータを選択し、適切な前処理を実行して、モデルの有効性に影響を与えるデータ品質の低下を回避します。バッチトレーニング:大規模なデータセットの場合、メモリオーバーフローを回避するためにトレーニングのためにバッチにデータをロードします。 GPUでの加速:独立したグラフィックカードを使用して、トレーニングプロセスを加速し、トレーニング時間を短縮します。
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 Edge ブラウザがメモリを大量に消費する場合の対処方法 Edge ブラウザがメモリを大量に消費する場合の対処方法
May 09, 2024 am 11:10 AM
Edge ブラウザがメモリを大量に消費する場合の対処方法 Edge ブラウザがメモリを大量に消費する場合の対処方法
May 09, 2024 am 11:10 AM
1. まず、Edge ブラウザに入り、右上隅にある 3 つの点をクリックします。 2. 次に、タスクバーの[拡張機能]を選択します。 3. 次に、不要なプラグインを閉じるかアンインストールします。
 わずか 250 ドルで、Hugging Face のテクニカル ディレクターが Llama 3 を段階的に微調整する方法を教えます
May 06, 2024 pm 03:52 PM
わずか 250 ドルで、Hugging Face のテクニカル ディレクターが Llama 3 を段階的に微調整する方法を教えます
May 06, 2024 pm 03:52 PM
Meta が立ち上げた Llama3、MistralAI が立ち上げた Mistral および Mixtral モデル、AI21 Lab が立ち上げた Jamba など、おなじみのオープンソースの大規模言語モデルは、OpenAI の競合相手となっています。ほとんどの場合、モデルの可能性を最大限に引き出すには、ユーザーが独自のデータに基づいてこれらのオープンソース モデルを微調整する必要があります。単一の GPU で Q-Learning を使用して、大規模な言語モデル (Mistral など) を小規模な言語モデルに比べて微調整することは難しくありませんが、Llama370b や Mixtral のような大規模なモデルを効率的に微調整することは、これまで課題として残されています。 。したがって、HuggingFace のテクニカル ディレクター、Philipp Sch 氏は次のように述べています。
