

変圧器を使用して、ライダー、ミリ波レーダー、視覚的特徴を効果的に関連付けるにはどうすればよいですか?

著者の個人的な理解
自動運転の基本的なタスクの 1 つは 3 次元のターゲット検出であり、多くの方法は現在マルチセンサー フュージョンに基づいています。では、なぜマルチセンサーフュージョンが必要なのでしょうか? それがライダーとカメラのフュージョンであっても、ミリ波レーダーとカメラのフュージョンであっても、主な目的は、点群と画像の間の補完的な接続を使用して、ターゲット検出の精度を向上させることです。コンピューター ビジョンの分野で Transformer アーキテクチャを継続的に適用することで、アテンション メカニズムに基づく手法により、複数のセンサー間の融合の精度が向上しました。共有された 2 つの論文は、このアーキテクチャに基づいており、それぞれのモダリティの有用な情報をさらに活用し、より優れた融合を達成するための新しい融合方法を提案しています。
TransFusion:
主な貢献
ライダーとカメラは自動運転における 2 つの重要な 3 次元目標検出センサーです。しかし、センサーフュージョンでは、主に画像の縞模様の状態が悪いために検出精度が低いという問題に直面しています。ポイントベースの融合手法は、ハード アソシエーションを通じて LIDAR とカメラを融合するものですが、これによりいくつかの問題が発生します。 a) 点群と画像の特徴を単純に接合すると、低品質の画像の特徴が存在すると、検出パフォーマンスが大幅に低下します。 ;b) まばらな点群と画像の間の厳密な相関関係を見つけると、高品質の画像特徴が無駄になり、位置合わせが困難になります。 この問題を解決するために、ソフトアソシエーション法が提案されている。この方法では、LIDAR とカメラを 2 つの独立した検出器として扱い、相互に連携して 2 つの検出器の利点を最大限に活用します。まず、従来のオブジェクト検出器を使用してオブジェクトを検出し、境界ボックスを生成します。次に、境界ボックスと点群を照合して、各点がどの境界ボックスに関連付けられているかのスコアを取得します。最後に、エッジ ボックスに対応する画像特徴が、点群によって生成された特徴と融合されます。この方法は、画像の縞模様の状態が悪いことに起因する検出精度の低下を効果的に回避できます。同時に、
この論文では、2 つのセンサー間の相関問題を解決するための、LIDAR とカメラの融合フレームワークである TransFusion を紹介します。 。主な貢献は次のとおりです。
- 変圧器ベースの LIDAR とカメラに基づく 3D 検出融合モデルを提案し、低画質やセンサーの位置ずれに対する優れた堅牢性を示しました。
- 導入オブジェクト クエリに対するいくつかのシンプルかつ効果的な調整により、画像融合の初期バウンディング ボックス予測の品質が向上しました。また、点群での検出が難しいオブジェクトを処理するための画像ガイド付きクエリ初期化モジュールも設計されました。
- Not nuScenes で高度な 3D 検出パフォーマンスを実現するだけでなく、モデルを 3D 追跡タスクに拡張し、良好な結果も達成します。
モジュールの詳細説明
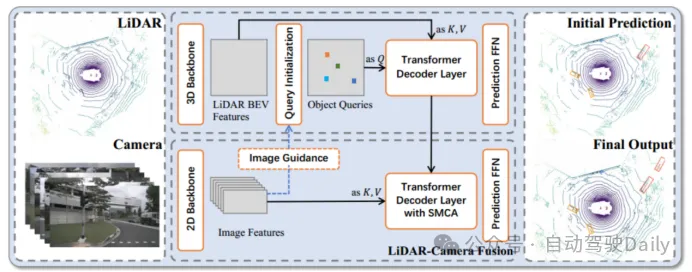
図 1 TransFusion の全体フレームワーク
解決するには上の画像エントリ 異なるセンサー間の差異と相関の問題を解決するために、Transformer ベースの融合フレームワークである TransFusion が提案されています。このモデルは、標準の 3D および 2D バックボーン ネットワークに依存して LiDAR BEV の特徴と画像の特徴を抽出し、2 つの Transformer デコーダ層で構成されます。最初の層のデコーダは疎な点群を使用して初期境界ボックスを生成し、2 番目の層のデコーダは最初の境界ボックスを変換します。レイヤー オブジェクト クエリは画像特徴クエリと組み合わされて、より良い検出結果が得られます。空間変調アテンション メカニズム (SMCA) と画像ガイド付きクエリ戦略も導入され、検出精度が向上します。このモデルを検出することで、より優れた画像特徴と検出精度を得ることができます。
クエリの初期化

##LiDAR-Camera Fusion
If オブジェクトに次のものが含まれる場合LIDAR ポイントの数が少ないと、同じ数の画像特徴しか取得できず、高品質の画像意味情報が無駄になります。したがって、この論文では、すべての画像特徴を保持し、Transformer のクロスアテンション メカニズムと適応手法を使用して特徴融合を実行し、ネットワークが画像から位置と情報を適応的に抽出できるようにします。 LiDAR BEV の特徴とさまざまなセンサーからの画像特徴の空間的不整合の問題を軽減するために、2 次元の中心の周りの 2 次元座標を渡す空間変調クロスアテンション モジュール (SMCA) が設計されています。各クエリ投影の次元円形ガウス マスクの重み付けはクロス アテンションです。
イメージガイドによるクエリの初期化
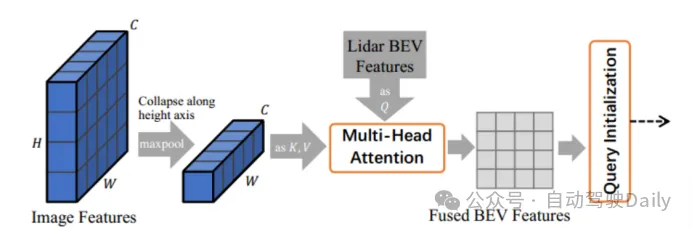
このモジュールは、画像特徴と LIDAR BEV 特徴をクロスアテンション メカニズム ネットワークに送信し、それらを BEV 平面に投影し、融合された BEV 特徴を生成することにより、LIDAR と画像情報をオブジェクト クエリとして同時に使用します。図 2 に示すように、まずマルチビュー画像の特徴がクロス アテンション メカニズム ネットワークのキー値として高さ軸に沿って折り畳まれ、LIDAR BEV 特徴がクエリとしてアテンション ネットワークに送信され、融合された BEV 特徴が取得されます。はヒート マップ予測に使用され、LIDAR のみのヒート マップ Ŝ で平均化されて、最終的なヒート マップ Ŝ を取得し、ターゲット クエリを選択して初期化します。このような操作により、モデルは LIDAR 点群では検出が困難なターゲットを検出できるようになります。
実験
データセットとメトリクス
nuScenes データセットは、3D 検出および追跡のための大規模な自動システムです。 700、150、150 のシーンを含む運転データセットは、それぞれトレーニング、検証、テストに使用されます。各フレームには、LIDAR 点群と 360 度の水平視野をカバーする 6 つのキャリブレーション画像が含まれています。 3D 検出の主な指標は、平均平均精度 (mAP) と nuScenes 検出スコア (NDS) です。 mAP は 3D IoU ではなく BEV 中心距離によって定義され、最終的な mAP は 10 のカテゴリの 0.5m、1m、2m、4m の距離しきい値を平均することによって計算されます。 NDS は、mAP と、移動、スケール、方向、速度、その他のボックス属性を含むその他の属性測定の包括的な測定です。 。
Waymo データセットには、トレーニング用の 798 シーンと検証用の 202 シーンが含まれています。公式指標は mAP と mAPH (方位精度によって重み付けされた mAP) です。 mAP と mAPH は、3D IoU しきい値 (車両の場合は 0.7、歩行者と自転車の場合は 0.5) に基づいて定義されます。これらのメトリクスはさらに 2 つの難易度レベルに分類されます。LEVEL1 は 5 つを超える LIDAR ポイントを持つ境界ボックス、LEVEL2 は少なくとも 1 つの LIDAR ポイントを持つ境界ボックスです。 nuScenes の 360 度カメラとは異なり、Waymo のカメラは水平約 250 度しかカバーしません。
トレーニング nuScenes データセットで、画像の 2D バックボーン ネットワークとして DLA34 を使用し、その重みをフリーズし、画像サイズを 448×800 に設定します。3D バックボーン ネットワークとして VoxelNet を選択します。ライダーの。トレーニング プロセスは 2 つのステージに分かれています。第 1 ステージでは、LiDAR データのみを入力として使用し、第 1 層デコーダと FFN フィードフォワード ネットワークを使用して 3D バックボーンを 20 回トレーニングして、初期の 3D バウンディング ボックス予測を生成します。第 2 ステージでは、LiDAR をトレーニングします。 -カメラ フュージョンおよび画像ガイド付きクエリ初期化モジュールは 6 回トレーニングされます。左の画像は、最初のバウンディング ボックス予測に使用されるトランスフォーマー デコーダー層のアーキテクチャであり、右の画像は、LiDAR とカメラの融合に使用されるトランスフォーマー デコーダー層のアーキテクチャです。
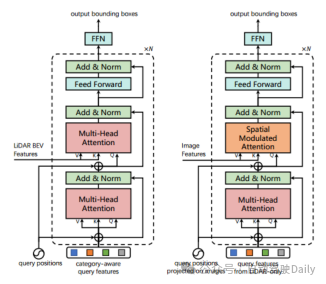
図 3 デコーダー層の設計
最先端の手法との比較
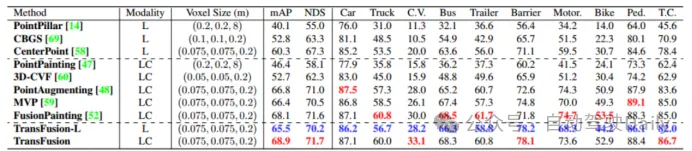
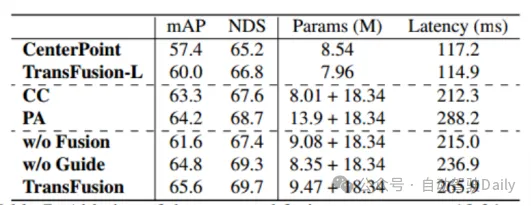
最初の比較TransFusion およびその他の SOTA 3D ターゲット検出タスクにおけるメソッドのパフォーマンスを以下の表 1 に示します。これは、nuScenes テスト セットでの結果です。このメソッドがその時点で最高のパフォーマンスに達していることがわかります (mAP は68.9%、NDSは71.7%)。 TransFusion-L は検出に LIDAR のみを使用し、その検出パフォーマンスは以前のシングルモーダル検出方法よりも大幅に優れており、これは主に新しい関連付けメカニズムとクエリ初期化によるものです。表 2 は、Waymo 検証セットでの LEVEL 2 mAPH の結果を示しています。
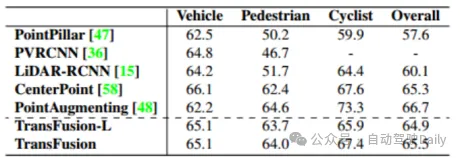
過酷な画像条件に対する堅牢性
TransFusion-L をベンチマークとして使用し、堅牢性を検証するためにさまざまな Fusion フレームワークが設計されています。 3 つのフュージョン フレームワークは、ポイントごとのスプライシングと LIDAR と画像フィーチャのフュージョン (CC)、ポイント エンハンスメント フュージョン ストラテジー (PA)、および TransFusion です。表 3 に示すように、nuScenes データ セットを昼と夜に分割することにより、TransFusion 手法により夜間のパフォーマンスが大幅に向上します。表 4 からわかるように、推論プロセス中に一部の画像が利用できない場合、検出パフォーマンスが低下します。 CC と PA の mAP はそれぞれ 23.8% と 17.2% 減少しましたが、TransFusion は 61.7% のままでした。キャリブレーションされていないセンサーは、3D ターゲット検出のパフォーマンスにも大きな影響を与えます。図 4 に示すように、実験設定では、カメラから LIDAR への変換行列に変換オフセットがランダムに追加されます。2 つのセンサーが 1m オフセットされている場合、mAP はTransFusion It の減少は 0.49% のみでしたが、PA と CC の mAP はそれぞれ 2.33% と 2.85% 減少しました。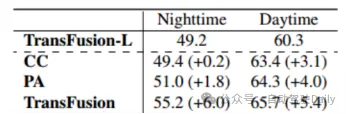
表 3 昼と夜の mAP

表 4 さまざまな数の画像での mAP
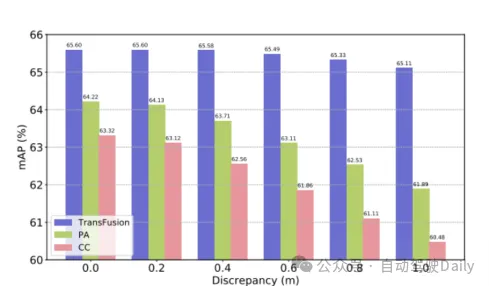
図4 mAP
センサーの位置ずれを伴うアブレーション実験
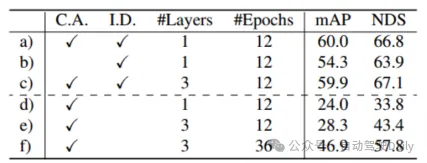
表 5 d)-f) の結果から、クエリの初期化がない場合に次のことがわかります。 、検出パフォーマンスは大幅に低下しますが、トレーニング ラウンドの数とデコーダ レイヤーの数を増やすとパフォーマンスは向上しますが、それでも理想的な効果を達成することはできません。これは、提案された初期化クエリ戦略が数を削減できることを側面から証明しています。ネットワーク層の。表 6 に示すように、画像特徴融合と画像ガイドによるクエリ初期化により、それぞれ 4.8% と 1.6% の mAP ゲインが得られます。表 7 では、さまざまな範囲での精度の比較を通じて、検出が困難な物体や遠隔地における TransFusion の検出パフォーマンスが、LIDAR のみの検出と比較して向上しています。

結論
効果的な効果と画像から取得すべき位置と情報を適応的に決定できるソフト相関メカニズムを備えた堅牢な Transformer ベースの LIDAR カメラ 3D 検出フレームワーク。 TransFusion は、nuScenes の検出および追跡リーダーボードで最先端の結果を達成し、Waymo 検出ベンチマークでも競争力のある結果を示しています。広範なアブレーション実験により、劣悪な画像条件に対するこの方法の堅牢性が実証されています。DeepInteraction:
主な貢献:
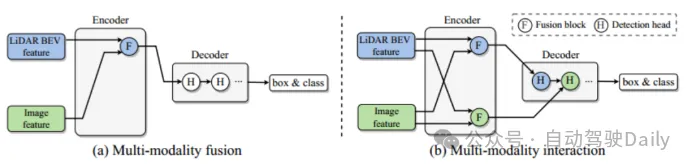
解決された主な問題は、既存のマルチモーダル融合戦略がモダリティを無視していることです。特定の有用な情報は、最終的にはモデルのパフォーマンスを妨げます。点群は低解像度で必要な位置情報と幾何学情報を提供し、画像は高解像度で豊富な外観情報を提供するため、クロスモーダル情報の融合は 3D ターゲット検出パフォーマンスを向上させるために特に重要です。図 1(a) に示すように、既存の融合モジュールは 2 つのモダリティの情報を統合されたネットワーク空間に統合しますが、そうすることで一部の情報が統合された表現に統合されなくなり、特定の情報の一部が減少します。モダリティの代表的な利点。上記の制限を克服するために、この記事では新しいモーダル相互作用モジュール (図 1(b)) を提案しています。重要なアイデアは、2 つのモダリティ固有の表現を学習して維持し、モダリティ間の相互作用を実現することです。主な貢献は次のとおりです。- マルチモーダル 3 次元ターゲット検出のための新しいモーダル インタラクション戦略を提案し、各モダリティで有用な情報が失われる以前のモーダル融合戦略の基本的な問題を解決することを目的としています。制限事項;
- マルチモーダル機能インタラクティブ エンコーダーとマルチモーダル機能予測インタラクティブ デコーダーを備えた DeepInteraction アーキテクチャを設計しました。
モジュールの詳細
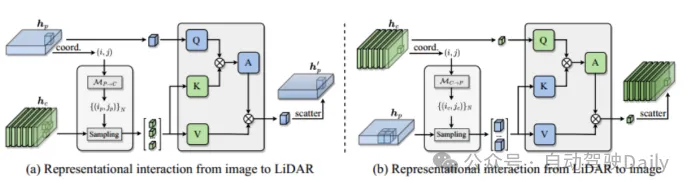
マルチモダリティ特性評価インタラクティブ エンコーダー エンコーダを多入力多出力 (MIMO) 構造にカスタマイズします。LIDAR とカメラ バックボーンによって個別に抽出された 2 つのモーダル固有のシーン情報を入力として受け取り、2 つの拡張機能情報を生成します。エンコーダの各層には、i) マルチモーダル特徴相互作用 (MMRI)、ii) イントラモーダル特徴学習、iii) 表現統合が含まれます。

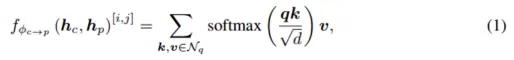
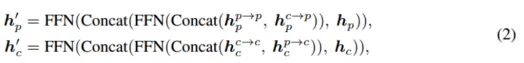

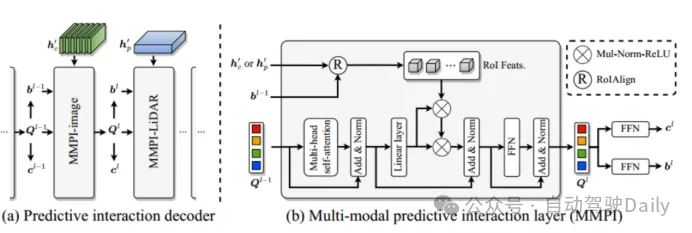
実験
データ セットとインジケーターは、TransFusion の nuScenes データ セット部分と同じです。実験の詳細 画像のバックボーン ネットワークは ResNet50 です。コンピューティング コストを節約するために、入力画像はネットワークに入る前に元のサイズの 1/2 に再スケールされます。画像ブランチはトレーニング中にフリーズします。ボクセルサイズは(0.075m、0.075m、0.2m)、検出範囲はX軸、Y軸が[-54m、54m]、Z軸が[-5m、3m]に設定されています。軸 2 つのエンコーダー層と 5 つのカスケード デコーダー層を設計します。さらに、テスト時間増加 (TTA) とモデル統合という 2 つのオンライン送信テスト モデルが設定されており、この 2 つの設定はそれぞれ DeepInteraction-large および DeepInteraction-e と呼ばれます。このうち、DeepInteraction-large は画像バックボーンネットワークとして Swin-Tiny を使用し、LIDAR バックボーンネットワーク内の畳み込みブロックのチャネル数を 2 倍にし、ボクセルサイズを [0.5m, 0.5m, 0.2m] に設定し、双方向を使用します。テスト時間を増やすには、ヨー角を反転および回転 [0°、±6.25°、±12.5°] します。 DeepInteraction-e は複数の DeepInteraction-large モデルを統合しており、入力 LIDAR BEV グリッド サイズは [0.5m、0.5m] および [1.5m、1.5m] です。
TransFusion の設定に従ってデータ拡張を実行します。範囲 [-π/4,π/4] のランダム回転、ランダム スケーリング係数 [0.9,1.1]、および標準の 3 軸ランダム移動を使用します。偏差 0.5 とランダムな水平反転、クラス バランス リサンプリングも CBGS で使用され、nuScenes のクラス分布のバランスをとります。 TransFusion と同じ 2 段階のトレーニング方法が使用され、TransFusion-L を LIDAR のみのトレーニングのベースラインとして使用します。 Adam オプティマイザーは、最大学習率 1×10−3、重み減衰 0.01、運動量 0.85 ~ 0.95 のシングルサイクル学習率戦略を使用し、CBGS に従います。 LIDAR ベースライン トレーニングは 20 ラウンド、LIDAR イメージ フュージョンは 6 ラウンド、バッチ サイズは 16、トレーニングには 8 つの NVIDIA V100 GPU が使用されます。最先端の手法との比較
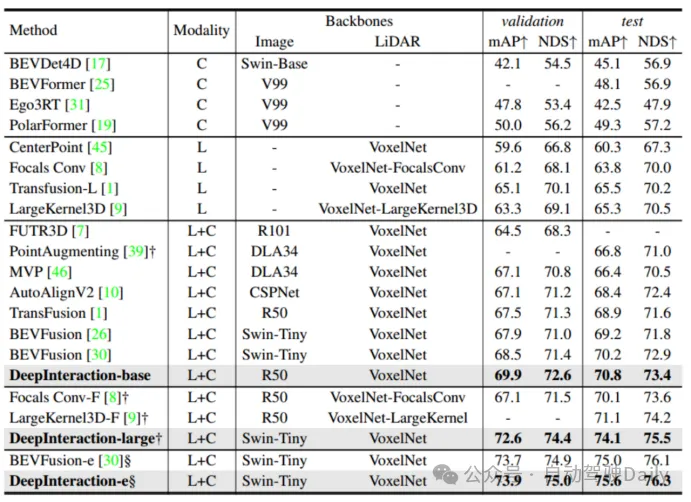
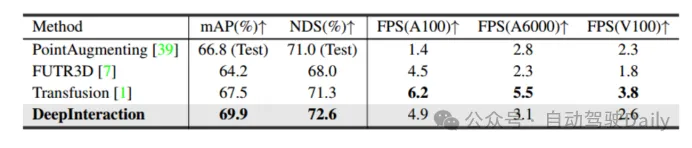 #表 2 推論速度の比較
#表 2 推論速度の比較
デコーダのアブレーション実験マルチモーダル対話型予測デコーダ層と DETR デコーダ層の設計を表 3(a) で比較します。ハイブリッド設計が使用されています。 通常の DETR デコーダ層を使用します。 LIDAR で特徴を集約するためです。表現では、インタラクション用マルチモーダル予測デコーダー (MMPI) を使用して、画像表現内の特徴を集約します (2 行目)。 MMPI は DETR よりも大幅に優れており、mAP が 1.3%、NDS が 1.0% 向上し、設計の組み合わせが柔軟です。表 3(c) では、さまざまなデコーダ層が検出パフォーマンスに及ぼす影響をさらに調査しています。5 層のデコーダを追加すると、パフォーマンスが向上し続けることがわかります。最後に、トレーニングとテストで使用したクエリ数のさまざまな組み合わせを比較しました。さまざまな選択の下でパフォーマンスは安定していましたが、トレーニング/テストの最適な設定として 200/300 が使用されました。
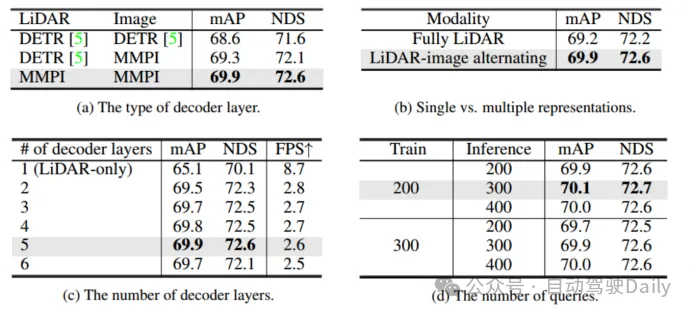 表 3 デコーダーのアブレーション実験
表 3 デコーダーのアブレーション実験
表 4(a) から、 (1) IML と比較して、マルチモーダル表現インタラクティブ エンコーダ (MMRI) はパフォーマンスを大幅に向上させることができます。(2) MMRI と IML はうまく連携してパフォーマンスをさらに向上させることができます。表 4(b) からわかるように、反復 MMRI ではエンコーダ層を積み重ねることが有益です。
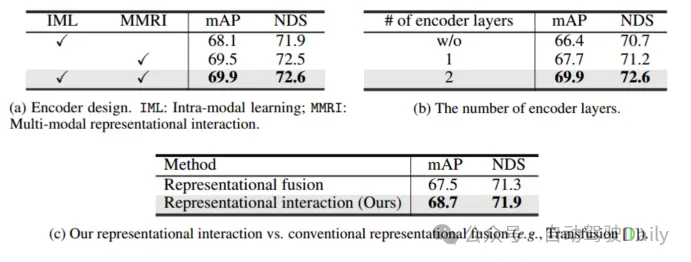
表 4 エンコーダのアブレーション実験
ライダー バックボーン ネットワークのアブレーション実験
2 つの異なるレーザーを使用したレーダー バックボーン ネットワーク: PointPillar と VoxelNet を使用してフレームワークの汎用性を確認します。 PointPillars の場合、ボクセル サイズを (0.2m, 0.2m) に設定し、残りの設定は DeepInteraction-base と同じにします。提案されたマルチモーダル インタラクション戦略により、DeepInteraction は、いずれかのバックボーンを使用した場合に LIDAR のみのベースラインと比較して一貫した改善を示しました (ボクセルベースのバックボーンでは 5.5% mAP、ピラーベースのバックボーンでは 4.4% mAP)。これは、さまざまな点群エンコーダ間の DeepInteraction の多用途性を反映しています。
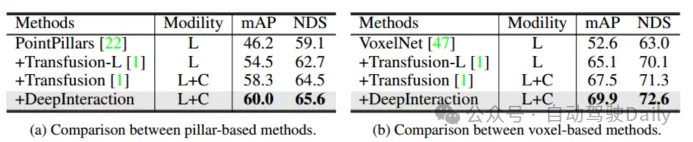
結論
この研究では、新しい3D ターゲット検出手法である DeepInteraction は、固有のマルチモーダル相補特性を調査するために開発されました。重要なアイデアは、2 つのモダリティ固有の表現を維持し、表現学習と予測デコードのためにそれらの間の相互作用を確立することです。この戦略は、既存の片側融合手法の基本的な制限、つまり、補助的なソース文字処理のために画像表現が十分に活用されていないという問題に対処するために特別に設計されています。2 つの論文の概要:
上記 2 つの論文は、LIDAR とカメラ フュージョンに基づく 3 次元ターゲット検出に基づいており、DeepInteraction からも確認できます。これは、TransFusion のさらなる研究に基づいています。これら 2 つの論文から、マルチセンサー フュージョンの 1 つの方向性は、さまざまなモダリティのより効果的な情報に焦点を当てるための、より効率的な動的フュージョン方法を探索することであると結論付けることができます。もちろん、これらはすべて、両方のモダリティにおける質の高い情報に基づいています。マルチモーダル融合は、自動運転や知能ロボットなどの将来の分野で非常に重要な応用が可能になるため、さまざまなモダリティから抽出される情報が徐々に豊富になるにつれて、より多くの情報を組み合わせてデータをより効率的に使用することができます。考える価値のある質問です。以上が変圧器を使用して、ライダー、ミリ波レーダー、視覚的特徴を効果的に関連付けるにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7486
7486
 15
1377
52
77
11
19
38
15
1377
52
77
11
19
38

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 i7-7700 が Windows 11 にアップグレードできない場合の解決策
Dec 26, 2023 pm 06:52 PM
i7-7700 が Windows 11 にアップグレードできない場合の解決策
Dec 26, 2023 pm 06:52 PM
i77700 のパフォーマンスは win11 を実行するのに完全に十分ですが、ユーザーは i77700 を win11 にアップグレードできないことがわかります。これは主に Microsoft によって課された制限が原因であるため、この制限をスキップする限りインストールできます。 i77700 は win11 にアップグレードできません: 1. Microsoft が CPU バージョンを制限しているためです。 2. win11 に直接アップグレードできるのは、Intel の第 8 世代以降のバージョンのみです 3. i77700 は第 7 世代として、win11 のアップグレードのニーズを満たすことができません。 4. ただし、i77700はパフォーマンス的にはwin11を快適に使用するのに完全に可能です。 5. したがって、このサイトの win11 直接インストール システムを使用できます。 6. ダウンロードが完了したら、ファイルを右クリックして「ロード」します。 7. ダブルクリックして「ワンクリック」を実行します。
 Microsoft Teams の 3D Fluent 絵文字について学ぶ
Apr 24, 2023 pm 10:28 PM
Microsoft Teams の 3D Fluent 絵文字について学ぶ
Apr 24, 2023 pm 10:28 PM
特に Teams ユーザーの場合は、Microsoft が仕事中心のビデオ会議アプリに 3DFluent 絵文字の新しいバッチを追加したことを覚えておく必要があります。 Microsoft が昨年 Teams と Windows 向けの 3D 絵文字を発表した後、その過程で実際に 1,800 を超える既存の絵文字がプラットフォーム用に更新されました。この大きなアイデアと Teams 用の 3DFluent 絵文字アップデートの開始は、公式ブログ投稿を通じて最初に宣伝されました。 Teams の最新アップデートでアプリに FluentEmojis が追加 Microsoft は、更新された 1,800 個の絵文字を毎日利用できるようになると発表
 転倒検知、骨格点人間動作認識に基づき、コードの一部はChatgptで完成
Apr 12, 2023 am 08:19 AM
転倒検知、骨格点人間動作認識に基づき、コードの一部はChatgptで完成
Apr 12, 2023 am 08:19 AM
こんにちは、みんな。今日は転倒検知プロジェクトについてお話ししたいと思います。正確に言うと、骨格点に基づく人間の動作認識です。大きく3つのステップに分かれています:人体認識、人体骨格点動作分類プロジェクトのソースコードがパッケージ化されています。入手方法については記事の最後を参照してください。 0. chatgpt まず、監視対象のビデオ ストリームを取得する必要があります。このコードは比較的固定されており、chatgpt で記述したコードを直接 chatgpt に完成させることができますが、問題なくそのまま使用できます。しかし、後のビジネス タスク (メディアパイプを使用して人間のスケルトン ポイントを特定するなど) になると、chatgpt によって指定されたコードは正しくありません。 chatgpt はビジネスロジックから独立したツールボックスとして使用できると思います。
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 Windows 11 のペイント 3D: ダウンロード、インストール、および使用ガイド
Apr 26, 2023 am 11:28 AM
Windows 11 のペイント 3D: ダウンロード、インストール、および使用ガイド
Apr 26, 2023 am 11:28 AM
新しい Windows 11 が開発中であるというゴシップが広まり始めたとき、すべての Microsoft ユーザーは、新しいオペレーティング システムがどのようなもので、何をもたらすのかに興味を持ちました。憶測を経て、Windows 11が登場しました。オペレーティング システムには新しい設計と機能の変更が加えられています。いくつかの追加に加えて、機能の非推奨と削除が行われます。 Windows 11 に存在しない機能の 1 つは Paint3D です。描画、落書き、落書きに適したクラシックなペイントは引き続き提供していますが、3D クリエイターに最適な追加機能を提供する Paint3D は廃止されています。追加機能をお探しの場合は、最高の 3D デザイン ソフトウェアとして Autodesk Maya をお勧めします。のように
 MIT の最新傑作: GPT-3.5 を使用して時系列異常検出の問題を解決する
Jun 08, 2024 pm 06:09 PM
MIT の最新傑作: GPT-3.5 を使用して時系列異常検出の問題を解決する
Jun 08, 2024 pm 06:09 PM
今日は、MIT が先週公開した記事を紹介します。GPT-3.5-turbo を使用して時系列異常検出の問題を解決し、時系列異常検出における LLM の有効性を最初に検証しました。プロセス全体に微調整はなく、GPT-3.5-turbo は異常検出に直接使用されます。この記事の核心は、時系列を GPT-3.5-turbo が認識できる入力に変換する方法とその設計方法です。 LLM が異常検出タスクを解決できるようにするためのプロンプトまたはパイプライン。この作品について詳しく紹介していきます。画像用紙タイトル:Large languagemodelscanbeゼロショタノマリデテ
