

GPT ストアはオープンすることさえできません。なぜこの国内プラットフォームがこのような道を歩むのでしょうか? ?

注目してください。この男性は 1,000 を超える大規模モデルを接続し、シームレスに接続して切り替えることができました。
最近、ビジュアル AI ワークフローが開始されました。
は、ドラッグ、プル、ドラッグして無限のキャンバス上に独自のワークフローを配置する直感的なインターフェイスを提供します。
よく言われるように、兵士は高価だが迅速です。Qubits は、この AI ワークフローがオンラインになってから 48 時間以内に、ユーザーがすでに 100 ノードを超える個人ワークフローを構成していたと聞きました。
# 内容を明かすことなく、今日私が話したいのは、LLMOps 会社である Dify とその CEO である Zhang Luyu についてです。
Zhang Luyu は Dify の創設者でもあります。
私はこの業界に入社する前、インターネット業界で 11 年間の経験がありました。私は製品設計に携わっており、プロジェクト管理を理解しており、SaaS について独自の洞察を持っています。
その後、Tencent Cloud CODING DevOps チームの製品および運用管理も担当し、100 万人を超える開発者ユーザーにプラットフォーム製品を提供しました。
Dify はビジネスを開始した後、すぐに彼と彼のチームと協力して、「オープンソース LLM アプリケーション開発プラットフォーム」の分野で絶対的なリーダーになり、これまでに GitHub に 22,000 個のスターを獲得しました。

今回は、新しい AI ワークフロー機能の助けを借りて、特に Zhang Luyu を見つけ、200,000 個の AI アプリケーションを大規模モデルに接続するのを支援した人物とチャットしました。
彼はこう言いました:
プログラミングの未来はフロー プログラミングになるかもしれません。
ドラッグ アンド ドロップでワークフロー設定を完了
つい最近、AI の第一人者である Andrew Ng 氏が、広範な議論を引き起こした見解を発表しました。同氏は、AIエージェントのワークフローが今年人工知能の大きな進歩を促進し、おそらく次世代の基本モデルをも超えるだろうと主張した。
Andrew Ng はワークフローを重要なトレンドと考えており、AI に携わるすべての人々にワークフローに注意を払うよう呼びかけています。
そこで、Dify は鉄が熱いうちに AI ワークフローを開始しました。 (しかし実際には、Dify は半年前にこの機会に気づきました。これについては後で説明します。)
正式にリリースされた後、それは江おばさんのものでした:
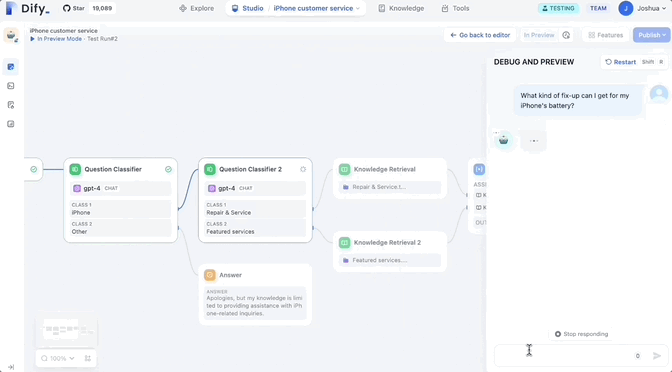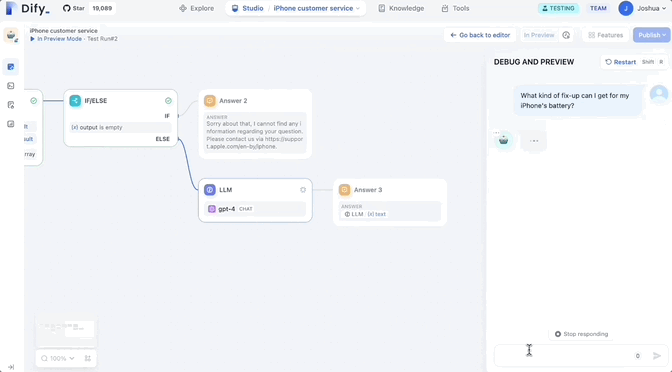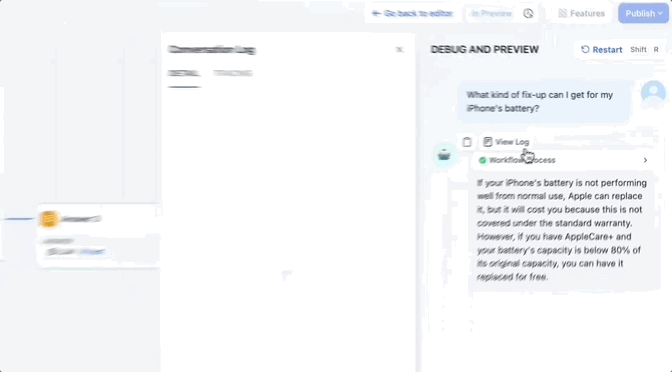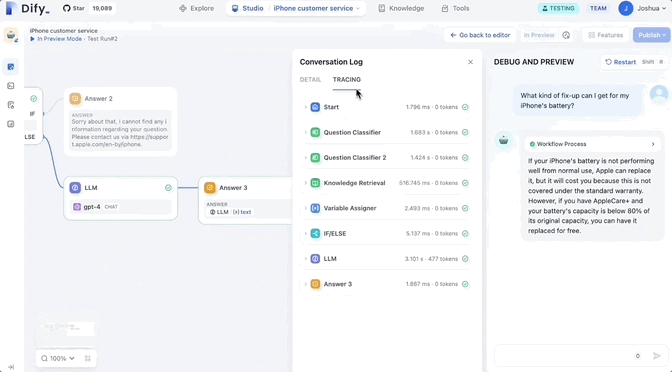
コアは直感的なものです。ドラッグアンドドロップインターフェイス。

ユーザーは、さまざまなノードを接続することで、無限のキャンバス上に独自のワークフローを構築できます。
はい、これは「無限のキャンバス」です。現在のバージョンでは、使用可能なノードの種類を継続的に拡張でき、ユーザーは各ノードの入力と出力を定義してロジックが動作することを確認できます。ワークフローとデータ フローは期待通りです。
つまり、ワークフローをエンドツーエンドでテストすることも、各ノードを個別にテストして問題を迅速に特定することもできます。
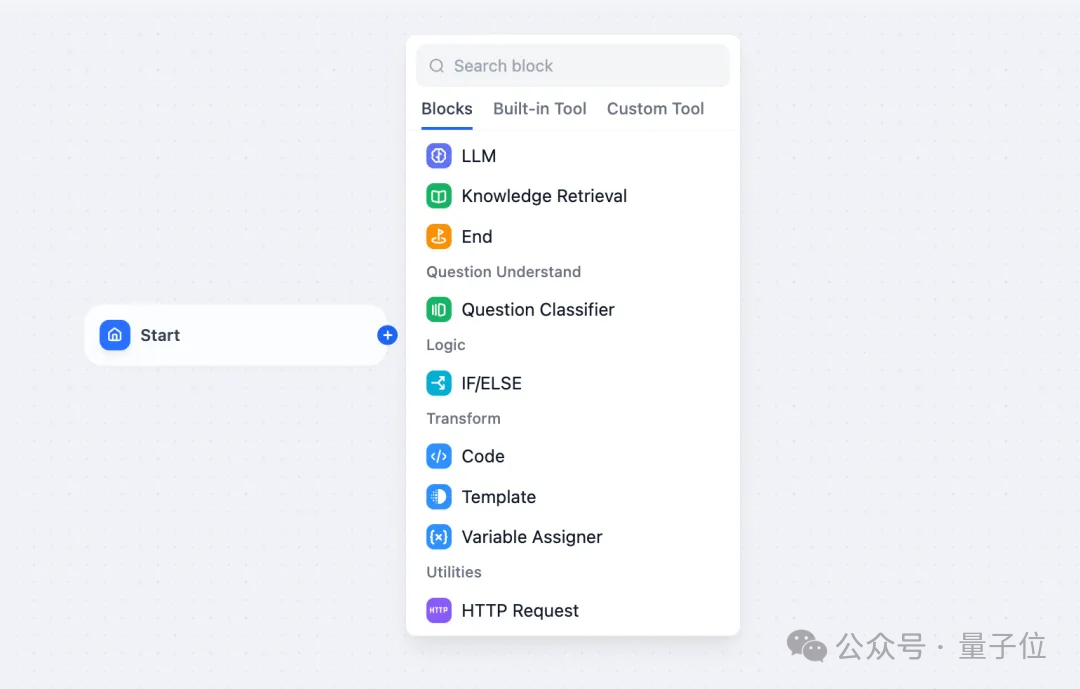
次のようないくつかのコア ノードが最初にサポートされることに注意してください。
- LLM: 主流の大規模言語モデルを選択し、その入力と出力
- ツール: 組み込みツールとカスタム ツールを使用して、ワークフローでできることを拡張します。
- Intent Classifier: LLM がユーザー入力を自動的に分類し、さまざまなカテゴリに従ってワークフローを実行できるようにします。
- ナレッジの取得: 既存のナレッジ ベースから LLM にコンテキスト データをマウントします。
- コード: カスタム Python または Node.js コードを実行します。
- If/Else ブロック : 分岐したワークフローを作成するための条件付きロジックを定義します。
さらに、AI ワークフローは、Zhang Luyu が「最も優れた機能の 1 つ」と呼んだ DSL のインポートとエクスポートをサポートしています。
簡単に言うと、ユーザーは自分のワークフローをエクスポートして他のワークスペースにインポートできるため、ワークフローを自由に行き来したり、必要に応じて再度カスタマイズしたりできます。
この機能は、コミュニティ内の他の人の作業を共同作業、共有、構築するための窓を開きます。
また、ワークフローでは、Dify プラットフォームのすべての機能を利用でき、ユーザーは、検索ソリューションのナレッジ ベース、つまり、Dify プラットフォームが提供するファーストパーティの豊富なツールをセットアップできます。プラットフォームやカスタマイズ ツールなどをノード機能の 1 つとして調整できます。
Dify エコシステムにシームレスに適応していると言えます。
しきい値が限りなく低いレベルに引き下げられることはありません
AI Workflow のリリース後、Dify には 2 つのアプリケーション モードがあります。
1 つはワークフロー、もう 1 つは従来のチャットフローです。
「大多数のユーザーは従来のチャットボット タイプを使用します。これには複雑なロジックはなく、基本的に接続されている大規模モデルの自己操作に依存しています。」と Zhang Luyu 氏は説明しました。対照的に、ワークフローははるかに強力になりますが、これはワークフローを使用してチャットボットを構築できないという意味ではありません。 「ワークフロー」はワークフローとして翻訳されていますが、実際には Dify の背後にある動作メカニズムを表していることが明らかになりました。
Difyがそのような方向に進化した理由は、チームが独自の「信念」を持っているからです。
私たちは、これからのプログラミングは(作業)フローになるかもしれないと信じています。
Dify の次の計画は、RAG のパイプラインとプロンプトの共同パラダイムを立ち上げることであると理解されています。
それでは、常にパッチを適用している Dify は、どのグループをユーザーおよび潜在的なユーザーとみなしているのでしょうか?
「中国には 1,000 万人の開発者がいると仮定します。現在、そのうちの 50 万人が、他の人に影響を与え、創造する能力を持っています。彼らにとって、大きなモデルには自然な魅力があります。残りの人々は、新しいものを理解し、受け入れるのに時間が必要です」 「
価値があり、継続力があり、完全に製品化でき、自分の業界やスキルで豊富なスキルを持っている人 - 張陸宇氏は、Dify サービスの主要なユーザー グループを「定義」し、彼を呼びました。私たちが考える真のプロの開発者、またはこの非常に創造的なイノベーターです。」
このグループは全人口の 10% にすぎません。
したがって、Zhang Luyu 氏も、DIfy が行ってきたことはツールの使用の敷居を下げることであると告白しましたが、その敷居は存在しないほど低くはならないでしょう。
Dify は使用量のしきい値をゼロに下げません。
関数をいつ起動するかの選択についても説明しました。
Dify が AI ワークフローを開始したのはそれほど早くなく、昨年後半以降、エージェントのコンセプトの人気を利用して、多くのスタートアップが同様の機能を開始しました。
しかし、Dify 氏は、GPT が開始される前に、チームはワークフローの可能性について洞察を持っていたと述べました。
私たちは、モデル側と製品側のダイナミクスを観察しながら、完全な機能を提供したいと考えており、準備ができていない戦いを戦うことは避けたいと考えています。「実際、私たちは意図的にペースを落としています##。
# 「大企業出身だが、私は反逆者だ」Dify には独自のリズムがあり、それはおそらくチームの自身に対する評価と関係があるでしょう。テクノロジー。
市場スペースを圧迫する大手メーカーの運命を心配しているかと問われたとき、彼が得た答えは 3 つの前向きな言葉でした。「恐れていません」。 その理由は次のとおりです。 第一に、市場競争はそれほど緊急かつ激しいものではないようです。 Dify が昨年 5 月に設立されたとき、中核となる創業チームは市場への参入が遅すぎて、どこかのチームが優位に立つのではないかと心配していました。それ。"第二に、大手メーカーは供給によって市場にそのような機会があると考えて賭けを選択することが多いですが、Dify は実際の需要が研究開発を促進すると考えているため、賭けを選択します。
Dify は大企業を恐れていないだけでなく、同様のスタートアップの力も恐れていません。 Zhang Luyu氏は、現在の波には多くの起業家がいるが、そのほとんどはまだ10年前の起業家の波であると述べました。このグループの人々には、大昌で修行したというラベルが貼られています。「大規模な工場での経験があるというレッテルが貼られる一方で、大規模な工場内の部門間での文書作成プロセスの複雑さは、こうした人々にとって固有の思考テンプレートにもなっています。」張陸宇も大工場に滞在しており、自らを「大工場の反逆者」と称し、その逸脱を誇示している - 私は
(思考に束縛される)カテゴリに属していません。私の最初の仕事は、21 歳のとき、大手ゲーム会社のエンジニアでした。当時は、自分がやっていることが価値があり、製品が非常に良いものであると判断した場合は、すべてのプロセスを無視してオンラインで製品を入手することを密航立ち上げと呼びました。
これは多くの企業で違法ですが、私はやらなければなりません。なぜ?プロセスに従ってもうまくいかないかもしれませんが、それをオンラインにすると、ユーザー エクスペリエンスによってもたらされる価値は大きくなります。これは起業と同じで、リスクを受け入れる必要があります。
起業家精神にはリスクが伴い、結果については慎重になる必要があります。幸いなことに、Zhang Luyu さんには嬉しいことがいくつかあります。
彼は、この 1 年間で最もエキサイティングなことは、非常に多くの若者がこの業界に流入しており、トップ校からの無数の新卒者が喜んでこの業界に参加しようとしていることだと述べました。「以前は、そのような人材を採用するのは困難でした。入社するように説得することはおろか、そのような履歴書をどこで見つけられるかさえ知りませんでした。」このグループの人々は卒業後、フォーチュン 500 企業や大規模工場で高いレベルのポジションを簡単に獲得できますが、現在は関連することにほとんどお金を費やしません。大型モデルまで。
「弊社にはそのような人がたくさんいますか?」 「少なくとも 1/3 はいますか? でも、この割合は十分ではないと思います。この人たちが主力になるはずです。」
以上がGPT ストアはオープンすることさえできません。なぜこの国内プラットフォームがこのような道を歩むのでしょうか? ?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
54
15
1378
52
78
11
19
54

 Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Readdirによるファイルソートを実装する方法
Apr 13, 2025 am 09:06 AM
Debian Systemsでは、Readdir関数はディレクトリコンテンツを読み取るために使用されますが、それが戻る順序は事前に定義されていません。ディレクトリ内のファイルを並べ替えるには、最初にすべてのファイルを読み取り、QSORT関数を使用してソートする必要があります。次のコードは、debianシステムにreaddirとqsortを使用してディレクトリファイルを並べ替える方法を示しています。
 PHPとPython:2つの一般的なプログラミング言語を比較します
Apr 14, 2025 am 12:13 AM
PHPとPython:2つの一般的なプログラミング言語を比較します
Apr 14, 2025 am 12:13 AM
PHPとPythonにはそれぞれ独自の利点があり、プロジェクトの要件に従って選択します。 1.PHPは、特にWebサイトの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンス、機械学習、人工知能に適しており、簡潔な構文を備えており、初心者に適しています。
 Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Readdirのパフォーマンスを最適化する方法
Apr 13, 2025 am 08:48 AM
Debian Systemsでは、Directoryコンテンツを読み取るためにReadDirシステム呼び出しが使用されます。パフォーマンスが良くない場合は、次の最適化戦略を試してください。ディレクトリファイルの数を簡素化します。大きなディレクトリをできる限り複数の小さなディレクトリに分割し、Readdirコールごとに処理されたアイテムの数を減らします。ディレクトリコンテンツのキャッシュを有効にする:キャッシュメカニズムを構築し、定期的にキャッシュを更新するか、ディレクトリコンテンツが変更されたときに、頻繁な呼び出しをreaddirに削減します。メモリキャッシュ(memcachedやredisなど)またはローカルキャッシュ(ファイルやデータベースなど)を考慮することができます。効率的なデータ構造を採用する:ディレクトリトラバーサルを自分で実装する場合、より効率的なデータ構造(線形検索の代わりにハッシュテーブルなど)を選択してディレクトリ情報を保存およびアクセスする
 Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
Debian Readdirが他のツールと統合する方法
Apr 13, 2025 am 09:42 AM
DebianシステムのReadDir関数は、ディレクトリコンテンツの読み取りに使用されるシステムコールであり、Cプログラミングでよく使用されます。この記事では、ReadDirを他のツールと統合して機能を強化する方法について説明します。方法1:C言語プログラムを最初にパイプラインと組み合わせて、cプログラムを作成してreaddir関数を呼び出して結果をinclude#include#include inctargc、char*argv []){dir*dir; structdireant*entry; if(argc!= 2){(argc!= 2){
 Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法
Apr 13, 2025 am 11:51 AM
このガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud
 Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverファイアウォールの構成のヒント
Apr 13, 2025 am 11:42 AM
Debian Mail Serverのファイアウォールの構成は、サーバーのセキュリティを確保するための重要なステップです。以下は、iPtablesやFirewalldの使用を含む、一般的に使用されるファイアウォール構成方法です。 iPtablesを使用してファイアウォールを構成してIPTablesをインストールします(まだインストールされていない場合):sudoapt-getupdatesudoapt-getinstalliptablesview現在のiptablesルール:sudoiptables-l configuration
 Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL証明書のインストール方法
Apr 13, 2025 am 11:39 AM
Debian Mail ServerにSSL証明書をインストールする手順は次のとおりです。1。最初にOpenSSL Toolkitをインストールすると、OpenSSLツールキットがシステムに既にインストールされていることを確認してください。インストールされていない場合は、次のコマンドを使用してインストールできます。sudoapt-getUpdatesudoapt-getInstalopenssl2。秘密キーと証明書のリクエストを生成次に、OpenSSLを使用して2048ビットRSA秘密キーと証明書リクエスト(CSR)を生成します:Openss
 Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian OpenSSLがどのように中間の攻撃を防ぐか
Apr 13, 2025 am 10:30 AM
Debian Systemsでは、OpenSSLは暗号化、復号化、証明書管理のための重要なライブラリです。中間の攻撃(MITM)を防ぐために、以下の測定値をとることができます。HTTPSを使用する:すべてのネットワーク要求がHTTPの代わりにHTTPSプロトコルを使用していることを確認してください。 HTTPSは、TLS(Transport Layer Security Protocol)を使用して通信データを暗号化し、送信中にデータが盗まれたり改ざんされたりしないようにします。サーバー証明書の確認:クライアントのサーバー証明書を手動で確認して、信頼できることを確認します。サーバーは、urlsessionのデリゲート方法を介して手動で検証できます
