

BEVFusionを超えて! DifFUSER: 普及モデルが自動運転マルチタスクに参入 (BEV セグメンテーション + 検出デュアル SOTA)

文前&筆者の個人的理解
現在、自動運転技術が成熟し、自動運転認知タスクの需要が高まる中、産業界や学界はBEV 空間に基づく 3 次元ターゲット検出とセマンティック セグメンテーション タスクを同時に完了できる理想的な知覚アルゴリズム モデルが非常に期待されています。自動運転可能な車両には、通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーが搭載されており、さまざまなモダリティでデータを収集します。これにより、異なるモーダル データ間の補完的な利点が最大限に活用され、たとえば、3D 点群データは 3D ターゲット検出タスクに情報を提供でき、カラー画像データはセマンティック セグメンテーション タスクに多くの情報を提供できます。 。 正確な情報。 異なるモーダルデータ間の補完的な利点を考慮すると、異なるモーダルデータの有効な情報を同じ座標系に変換することで、その後の共同処理や意思決定が容易になります。例えば、3D点群データをBEV空間に基づく点群データに変換したり、サラウンドビューカメラの画像データをカメラの内部パラメータと外部パラメータのキャリブレーションを通じて3D空間に投影したりすることで、一元的な処理を実現します。異なるモーダルデータ。異なるモーダル データを利用することで、単一モーダル データよりも正確な知覚結果を取得できます。 現在では、マルチモーダル知覚アルゴリズム モデルをすでに車両に展開して、より堅牢で正確な空間知覚結果を出力することができ、正確な空間知覚結果を通じて、自動運転機能の実現に対してより信頼性が高く安全な保証を提供できます。
最近、Transformer ネットワーク フレームワークに基づく多感覚およびマルチモーダル データ融合のための多くの 3D 認識アルゴリズムが学術界や産業界で提案されていますが、それらはすべて Transformer のクロスアテンション メカニズムを使用して、多機能を実現します。感覚データとマルチモーダル データの融合。モーダル データを融合して、理想的な 3D ターゲット検出結果を実現します。ただし、このタイプのマルチモーダル特徴融合方法は、BEV 空間に基づくセマンティック セグメンテーション タスクには完全に適しているわけではありません。さらに、クロスアテンション メカニズムを使用して異なるモダリティ間の情報融合を完了することに加えて、多くのアルゴリズムは LSA で順方向ベクトル変換を使用して融合された特徴を構築しますが、次のようないくつかの問題もあります。 (制限ワード数、詳細な説明は以下にあります) )。
- 現在提案されているマルチモーダル融合に関する3Dセンシングアルゴリズムでは、異なるモーダルデータ特徴の融合手法の設計が不十分であり、その結果、知覚アルゴリズムモデルが正確に捉えることができません。センサーデータ間の関係は複雑な接続関係にあり、それによってモデルの最終的な知覚パフォーマンスに影響を与えます。
- 異なるセンサーからデータを収集するプロセスでは、無関係なノイズ情報が必然的に導入されます。異なるモダリティ間のこの固有のノイズにより、異なるモダリティの特徴を融合するプロセスにもノイズが混入し、結果として複数のノイズが発生します。不正確なモーダル特徴融合は、その後の知覚タスクに影響を与えます。
最終モデルの知覚能力に影響を与える可能性があるマルチモーダル融合プロセスにおける上記の多くの問題を考慮し、生成モデルによって最近実証された強力なパフォーマンスを考慮して、このモデルは、複数のセンサー間のマルチモーダル融合およびノイズ除去タスクのために調査されています。これに基づいて、マルチモーダル知覚タスクを実装するための条件付き拡散に基づく生成モデル知覚アルゴリズム DifFUSER を提案します。下の図からわかるように、私たちが提案したDifFUSERマルチモーダルデータ融合アルゴリズムは、より効果的なマルチモーダル融合プロセスを実現できます。  DifFUSER マルチモーダル データ融合アルゴリズムは、より効果的なマルチモーダル フュージョン プロセスを実現できます。この方法には主に 2 つの段階が含まれます。まず、生成モデルを使用して入力データのノイズを除去および強化し、クリーンでリッチなマルチモーダル データを生成します。次に、生成モデルによって生成されたデータは、より良い知覚効果を達成するためにマルチモーダル融合に使用されます。 DifFUSER アルゴリズムの実験結果は、私たちが提案したマルチモーダル データ融合アルゴリズムがより効果的なマルチモーダル融合プロセスを達成できることを示しています。マルチモーダル知覚タスクを実装する場合、このアルゴリズムはより効果的なマルチモーダル融合プロセスを実現し、モデルの知覚能力を向上させることができます。さらに、アルゴリズムのマルチモーダル データ融合アルゴリズムにより、より効率的なマルチモーダル融合プロセスを実現できます。要約
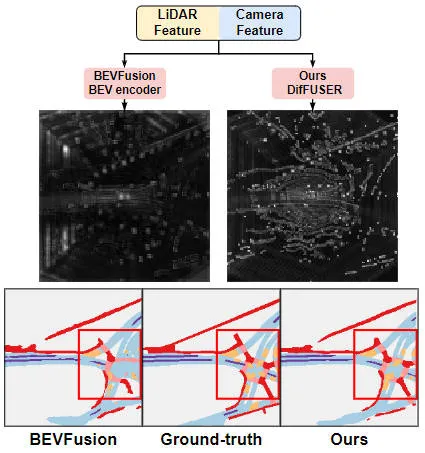
提案されたアルゴリズム モデルと他のアルゴリズム モデルの結果の視覚的な比較表
論文リンク: https://arxiv.org/pdf /2404.04629. pdf
ネットワーク モデルの全体的なアーキテクチャと詳細
「条件付き拡散モデルに基づくマルチタスク認識アルゴリズムである DifFUSER アルゴリズムのモジュールの詳細」 」は、タスクを意識した問題のアルゴリズムを解決するために使用される手法です。以下の図は、私たちが提案する DifFUSER アルゴリズムの全体的なネットワーク構造を示しています。 このモジュールでは、タスク認識問題を解決するための条件付き拡散モデルに基づくマルチタスク認識アルゴリズムを提案します。このアルゴリズムの目標は、ネットワーク内でタスク固有の情報を分散および集約することにより、マルチタスク学習のパフォーマンスを向上させることです。 DifFUSER アルゴリズムの整数
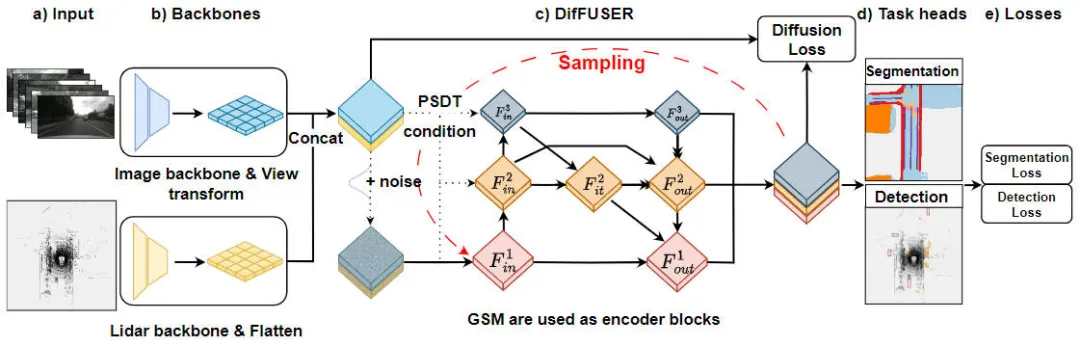 提案された DifFUSER 知覚アルゴリズム モデルのネットワーク構造図
提案された DifFUSER 知覚アルゴリズム モデルのネットワーク構造図
上図からわかるように、私たちが提案した DifFUSER ネットワーク構造には、主に 3 つのサブネットワーク、つまりバックボーン ネットワーク部分と DifFUSER のマルチ ネットワークが含まれています。 -mode 状態データ融合部分と最終的な BEV セマンティック セグメンテーション タスクのヘッド部分。 3D オブジェクト検出認識タスクの先頭部分。 バックボーン ネットワーク部分では、ResNet や VGG などの既存の深層学習ネットワーク アーキテクチャを使用して、入力データの高レベルの特徴を抽出します。 DifFUSER のマルチモーダル データ フュージョン部分は複数の並列ブランチを使用し、各ブランチはさまざまなセンサー データ タイプ (画像、LIDAR、レーダーなど) を処理するために使用されます。各ブランチには独自のバックボーン ネットワーク パーツがあり、
- #: このパーツは主に、ネットワーク モデルへの 2D 画像データ入力と、出力用の対応する BEV セマンティック フィーチャの 3D LIDAR 点群データから特徴を抽出します。 。画像特徴を抽出するバックボーンネットワークとしては、主に2D画像バックボーンネットワークと透視変換モジュールから構成されます。 3D LIDAR 点群フィーチャを抽出するバックボーン ネットワークには、主に 3D 点群バックボーン ネットワークとフィーチャ Flatten モジュールが含まれます。 DifFUSER マルチモーダル データ融合部分
- : 私たちが提案した DifFUSER モジュールは、階層的な双方向機能ピラミッド ネットワークの形式で相互にリンクされています。この構造を cMini-BiFPN と呼びます。この構造は、潜在的な拡散に代わる構造を提供し、さまざまなセンサー データからのマルチスケールおよび幅高さの詳細な特徴情報をより適切に処理できます。 BEV セマンティック セグメンテーション、3D ターゲット検出知覚タスク ヘッダー部分
- : 私たちのアルゴリズム モデルは 3D ターゲット検出結果とセマンティック セグメンテーション結果を BEV 空間に同時に出力できるため、3D 知覚タスク ヘッダーには 3D が含まれます。検出ヘッドとセマンティック セグメンテーション ヘッド。さらに、私たちが提案したアルゴリズム モデルに含まれる損失には、拡散損失、検出損失、セマンティック セグメンテーション損失が含まれており、すべての損失を合計することで、ネットワーク モデルのパラメータがバックプロパゲーションによって更新されます。 次に、モデルの各主要なサブ部分の実装の詳細を注意深く紹介します。
自動運転システムの認識タスクの場合、アルゴリズム モデルは現在の外部信号を分析できます。環境をリアルタイムで認識することが重要であるため、拡散モジュールのパフォーマンスと効率を確保することが非常に重要です。したがって、私たちは双方向機能ピラミッド ネットワークからインスピレーションを得て、同様の条件を持つ BiFPN 拡散アーキテクチャを導入しました。これを Conditional-Mini-BiFPN と呼びます。その具体的なネットワーク構造を上の図に示します。


自動運転車の場合自動運転取得センサーの性能は非常に重要であり、自動運転車両の日常運転中に、カメラセンサーやライダーセンサーがブロックされたり、誤動作したりする可能性が非常に高く、最終的な自動運転システムの性能に影響を与えます。そして業務効率化。この考慮に基づいて、センサーがブロックされる可能性がある状況で提案されたアルゴリズム モデルの堅牢性と適応性を強化するための、漸進的なセンサー ドロップアウト トレーニング パラダイムを提案しました。
私たちが提案した漸進的センサー ドロップアウト トレーニング パラダイムを通じて、アルゴリズム モデルは、カメラ センサーと LIDAR センサーによって収集された 2 つのモーダル データの分布を使用して欠落している特徴を再構築し、それによって過酷な条件で最高のパフォーマンスを達成できます。優れた適応性と堅牢性。具体的には、画像データと LIDAR 点群データの特徴を 3 つの異なる方法で利用します。トレーニング ターゲットとして、拡散モジュールへのノイズ入力として、センサーの紛失または誤動作の状況をシミュレートします。トレーニング中に、カメラ センサーまたは LIDAR センサー入力の損失率を 0 から事前定義された最大値 a = 25 まで徐々に増加させます。プロセス全体は次の式で表すことができます:
このうち、 は現在のモデルが含まれるトレーニング ラウンドの数を表し、特徴内の各特徴がドロップされる確率を表すドロップアウトの確率を定義します。この漸進的なトレーニング プロセスを通じて、モデルは効果的にノイズを除去し、より表現力豊かな特徴を生成するようにトレーニングされるだけでなく、単一のセンサーへの依存を最小限に抑え、それによって不完全なセンサーの処理を強化し、データの復元力を高めます。
ゲート自己調整変調拡散モジュール (GSM 拡散モジュール)

具体的には、ゲート自己調整変調拡散モジュール ネットワーク構造は以下の図に示されています。
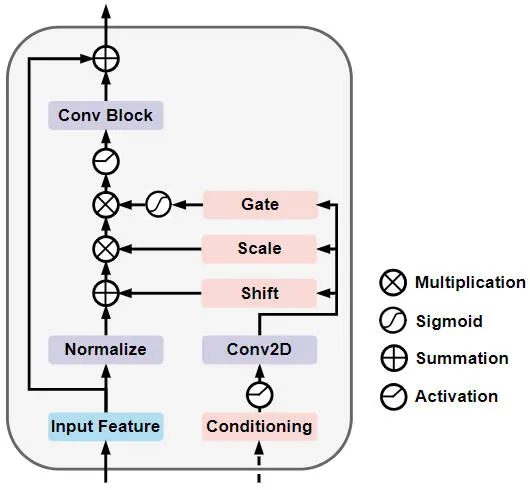
ゲート自己条件付き変調拡散モジュールのネットワーク構造の概略図

## 実験結果と評価指標
##定量分析部分 ##提案したアルゴリズム モデル DifFUSER の知覚結果を複数の環境で検証するために、タスクでは、主に nuScenes データを使用しました。3D ターゲット検出と BEV 空間に基づくセマンティック セグメンテーションの実験がセットで行われました。
まず、提案されたアルゴリズム モデル DifFUSER のパフォーマンスを、セマンティック セグメンテーション タスクにおける他のマルチモーダル フュージョン アルゴリズムと比較しました。具体的な実験結果を次の表に示します。
nuScenes データセット上の BEV 空間ベースのセマンティック セグメンテーション タスクにおけるさまざまなアルゴリズム モデルの実験結果の比較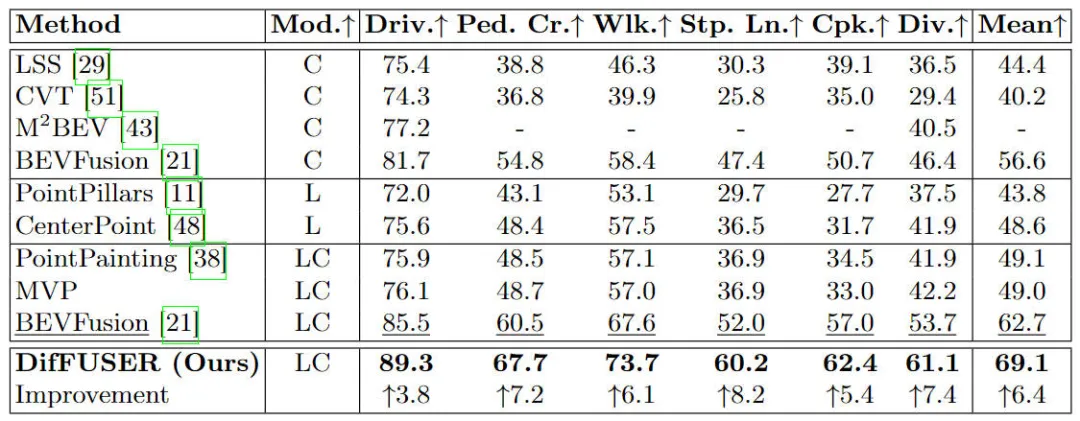 実験結果から、私たちが提案したアルゴリズム モデルのパフォーマンスがベースライン モデルよりも優れていることがわかります。大幅な改善が見られました。具体的には、BEVFusion モデルの mIoU 値はわずか 62.7% ですが、私たちが提案したアルゴリズム モデルは 69.1% に達し、6.4% ポイント改善しました。これは、私たちが提案したアルゴリズムがさまざまなカテゴリでより多くの利点があることを示しています。さらに、下の図は、私たちが提案したアルゴリズム モデルの利点をより直感的に示しています。具体的には、BEVFusion アルゴリズムは、特にセンサーの位置ずれがより明らかな長距離シナリオでは、不十分なセグメンテーション結果を出力します。比較すると、私たちのアルゴリズム モデルはより正確なセグメンテーション結果を持ち、詳細がより明白でノイズが少なくなります。
実験結果から、私たちが提案したアルゴリズム モデルのパフォーマンスがベースライン モデルよりも優れていることがわかります。大幅な改善が見られました。具体的には、BEVFusion モデルの mIoU 値はわずか 62.7% ですが、私たちが提案したアルゴリズム モデルは 69.1% に達し、6.4% ポイント改善しました。これは、私たちが提案したアルゴリズムがさまざまなカテゴリでより多くの利点があることを示しています。さらに、下の図は、私たちが提案したアルゴリズム モデルの利点をより直感的に示しています。具体的には、BEVFusion アルゴリズムは、特にセンサーの位置ずれがより明らかな長距離シナリオでは、不十分なセグメンテーション結果を出力します。比較すると、私たちのアルゴリズム モデルはより正確なセグメンテーション結果を持ち、詳細がより明白でノイズが少なくなります。
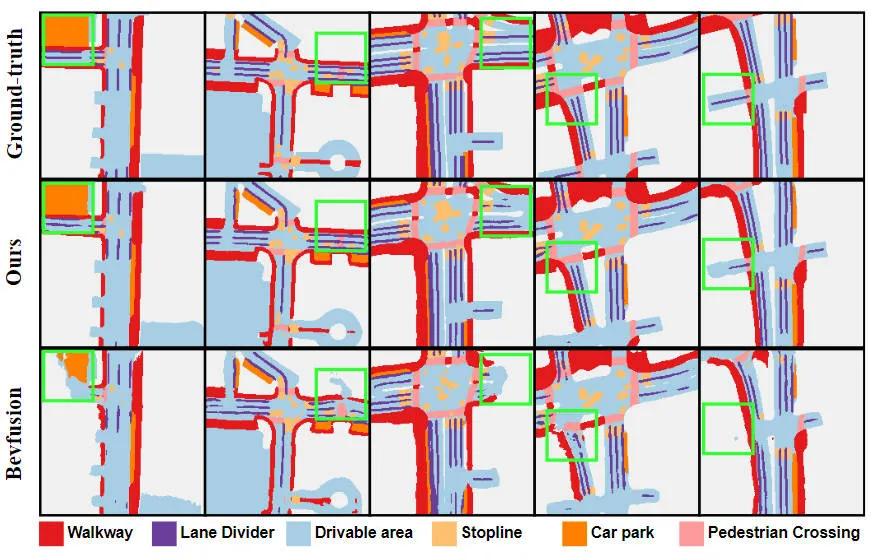 提案されたアルゴリズム モデルとベースライン モデルのセグメンテーション視覚化結果の比較
提案されたアルゴリズム モデルとベースライン モデルのセグメンテーション視覚化結果の比較
さらに、提案されたアルゴリズム モデルを他の 3D ターゲットと比較します。検出アルゴリズム モデル 比較のために、特定の実験結果を以下の表に示します
##nuScenes データ セットの 3D ターゲット検出タスクにおけるさまざまなアルゴリズム モデルの実験結果の比較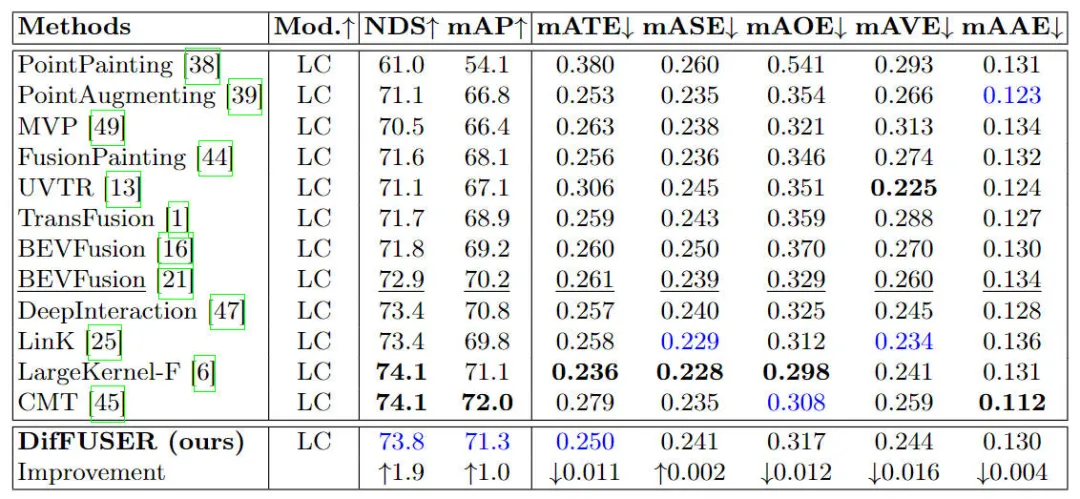
さまざまな状況下でのアルゴリズムのパフォーマンスの比較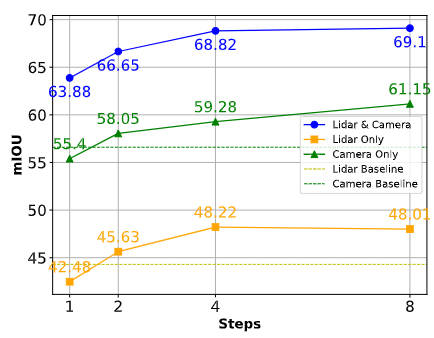
定性分析部分
次の図は、提案した DifFUSER アルゴリズム モデルの BEV 空間の 3D ターゲット検出とセマンティック セグメンテーションの結果を視覚化したものです。提案されたアルゴリズム モデルには、優れた検出効果とセグメンテーション効果があります。

結論
本稿では、拡散モデルに基づいて、ネットワーク モデル アーキテクチャを構築し、拡散モデルのノイズ除去特性を利用してネットワーク モデルの融合品質を向上させます。 Nuscenes データセットの実験結果は、私たちが提案したアルゴリズム モデルが BEV 空間のセマンティック セグメンテーション タスクにおいて SOTA セグメンテーション パフォーマンスを達成し、3D ターゲット検出タスクにおいて現在の SOTA アルゴリズム モデルと同様の検出パフォーマンスを達成できることを示しています。
以上がBEVFusionを超えて! DifFUSER: 普及モデルが自動運転マルチタスクに参入 (BEV セグメンテーション + 検出デュアル SOTA)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
20
15
1376
52
77
11
19
20

 パデュー大学による、時間をかける価値のある拡散モデルのチュートリアル
Apr 07, 2024 am 09:01 AM
パデュー大学による、時間をかける価値のある拡散モデルのチュートリアル
Apr 07, 2024 am 09:01 AM
拡散はより良いものを模倣するだけでなく、「創造」することもできます。拡散モデル(DiffusionModel)は、画像生成モデルである。 AI 分野でよく知られている GAN や VAE などのアルゴリズムと比較すると、拡散モデルは異なるアプローチを採用しており、その主な考え方は、最初に画像にノイズを追加し、その後徐々にノイズを除去するプロセスです。ノイズを除去して元の画像を復元する方法は、アルゴリズムの中核部分です。最後のアルゴリズムは、ランダムなノイズを含む画像から画像を生成できます。近年、生成 AI の驚異的な成長により、テキストから画像への生成、ビデオ生成など、多くのエキサイティングなアプリケーションが可能になりました。これらの生成ツールの背後にある基本原理は、以前の方法の制限を克服する特別なサンプリング メカニズムである拡散の概念です。
 拡散モデルの適用を時系列にまとめた記事
Mar 07, 2024 am 10:30 AM
拡散モデルの適用を時系列にまとめた記事
Mar 07, 2024 am 10:30 AM
拡散モデルは現在、生成 AI のコア モジュールであり、Sora、DALL-E、Imagen などの大規模な生成 AI モデルで広く使用されています。同時に、拡散モデルは時系列にますます適用されています。この記事では、時系列での拡散モデルの適用原理を理解するのに役立つように、拡散モデルの基本的な考え方と、時系列で使用される拡散モデルの代表的な作品をいくつか紹介します。 1. 拡散モデルのモデリングのアイデア 生成モデルの核心は、ランダムな単純分布から点をサンプリングし、一連の変換を通じてこの点をターゲット空間内の画像またはサンプルにマッピングできることです。拡散モデルの手法では、サンプリングされたサンプル点上のノイズを継続的に除去し、複数のノイズ除去ステップを経て、最終データが生成されます。
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 BitGenie を高速化する方法_BitGenie のダウンロード速度を高速化する方法
Apr 29, 2024 pm 02:58 PM
BitGenie を高速化する方法_BitGenie のダウンロード速度を高速化する方法
Apr 29, 2024 pm 02:58 PM
1. まず、BT シードが健全で、十分なシードがあり、十分な人気があることを確認して、BT ダウンロードの前提条件を満たし、速度が速いことを確認します。自分の BitComet の「選択」列を開き、最初の列の「ネットワーク接続」をクリックして、グローバル最大ダウンロード速度を制限なく 1000 に調整します (200 万未満のユーザーの 1000 は到達不可能な数ですが、調整しなくても問題ありません)ダウンロードしたくない人はこれをダウンロードしてください)非常に高速です)。最大アップロード速度は制限なく 40 まで調整できます (個人の状況に基づいて適切に選択してください。速度が速すぎるとコンピューターがフリーズします)。 3. 「タスク設定」をクリックします。内部のデフォルトのダウンロード ディレクトリを調整できます。 4. 「インターフェースの外観」をクリックします。表示されるピアの最大数を 1000 に変更します。これは、安心して接続しているユーザーの詳細を表示するためです。 5. をクリックします。
 win7でnetshコマンドを使う方法
Apr 09, 2024 am 10:03 AM
win7でnetshコマンドを使う方法
Apr 09, 2024 am 10:03 AM
netsh コマンドは Windows 7 でネットワークを管理するために使用され、次のことを実行できます。 ネットワーク情報の表示 TCP/IP 設定の構成 ワイヤレス ネットワークの管理 ネットワーク プロキシのセットアップ
 nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
nuScenes の最新 SOTA | SparseAD: スパース クエリは効率的なエンドツーエンドの自動運転に役立ちます。
Apr 17, 2024 pm 06:22 PM
先頭と開始点に書かれている エンドツーエンドのパラダイムでは、統一されたフレームワークを使用して自動運転システムのマルチタスクを実現します。このパラダイムの単純さと明確さにも関わらず、サブタスクにおけるエンドツーエンドの自動運転手法のパフォーマンスは、依然としてシングルタスク手法に比べてはるかに遅れています。同時に、以前のエンドツーエンド手法で広く使用されていた高密度鳥瞰図 (BEV) 機能により、より多くのモダリティやタスクに拡張することが困難になります。ここでは、スパース検索中心のエンドツーエンド自動運転パラダイム (SparseAD) が提案されています。このパラダイムでは、スパース検索は、高密度の BEV 表現を使用せずに、空間、時間、タスクを含む運転シナリオ全体を完全に表します。具体的には、統合されたスパース アーキテクチャが、検出、追跡、オンライン マッピングなどのタスク認識のために設計されています。さらに、重い
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
