

Wenxin 4.0 は SuperBench の評価で優れたパフォーマンスを示し、多くの指標でリードしました

2024年3月、清華大学基礎モデル研究センターが最近発表した「SuperBench大型モデル総合能力評価報告書」では、国内外の影響力のある14モデルを総合的に評価した。
このレポートでは、Wenian 4.0 の優れたパフォーマンスが広く注目を集めています。総合性能は海外トップモデルに肉薄しており、徐々に世界トップモデルとの差を縮め、国内トップモデルとしての地位を確立している。
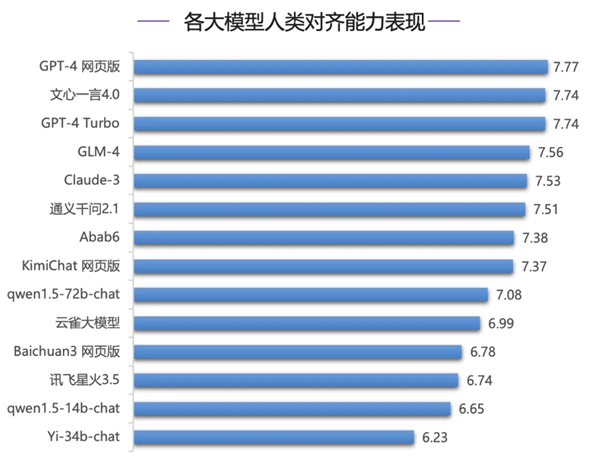
人間のアライメント能力の評価では、Text 4.0が突出した強さを示し、間違いなく国内1位となりました。同時に、中国語の推論と中国語能力の評価においても、Text 4.0 は他のモデルと比較して最高であり、その利点は非常に明白です。特に中国語理解力の評価では、Text 4.0のスコアが2位のGLM-4を0.41ポイント上回り、中国語処理のスキルの高さを示しています。
意味理解のための数学的能力の評価では、Text 4.0 モデルと Claude-3 モデルが同率で世界 1 位となり、有名な GPT-4 シリーズ モデルがそれに僅差で続き、4 位と 5 位にランクされました。他機種のスコアは55点前後に集中しており、上位グループとの間には大きな差が開いている。
読解力の評価では、Wenxin 4.0も輝いています。 GPT-4 TurboやClaude-3を上回るだけでなく、GLM-4をも上回る最高スコアを達成しました。
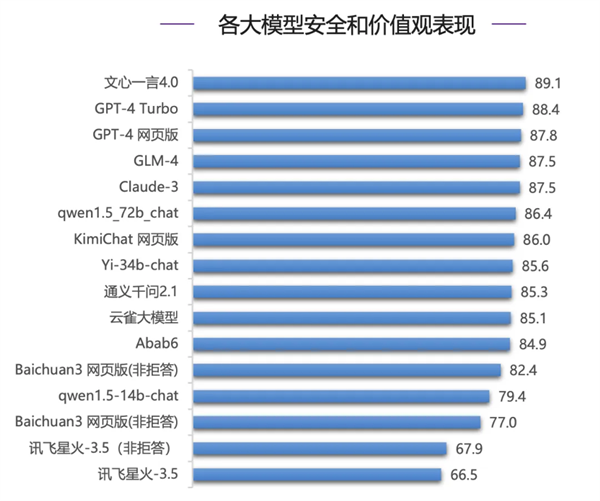
企業が最も懸念するセキュリティ評価でも、Text GPT 4.0は優れたパフォーマンスを示しました。世界トップクラスのGPT-4シリーズやClaude-3を上回る89.1点という高得点を記録した。このレビューでは、Claude-3 は 4 位にランクされましたが、1 位にランクされました。
レポートでは、Wenxinyiyan が昨年 3 月 16 日に一般公開されて以来、短期間でユーザー数の飛躍的な進歩を遂げ、現在 2 億人を超えるユーザーがいると述べています。同時に、1 日あたりの API 呼び出し数も非常に活発で、2 億回を超えています。
以上がWenxin 4.0 は SuperBench の評価で優れたパフォーマンスを示し、多くの指標でリードしましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

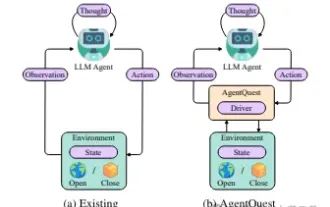 エージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuest
Apr 11, 2024 pm 08:52 PM
エージェントの境界の探索: 大規模な言語モデル エージェントのパフォーマンスを包括的に測定および改善するためのモジュール式ベンチマーク フレームワークである AgentQuest
Apr 11, 2024 pm 08:52 PM
大規模モデルの継続的な最適化に基づいて、LLM エージェント - これらの強力なアルゴリズム エンティティは、複雑な複数ステップの推論タスクを解決する可能性を示しています。自然言語処理から深層学習に至るまで、LLM エージェントは徐々に研究や業界の焦点になりつつあります。LLM エージェントは、人間の言語を理解して生成するだけでなく、戦略を策定し、多様な環境でタスクを実行し、API 呼び出しやコーディングを使用して構築することもできます。ソリューション。この文脈において、AgentQuest フレームワークの導入はマイルストーンであり、LLM エージェントの評価と進歩のためのモジュール式ベンチマーク プラットフォームを提供するだけでなく、研究者にこれらのエージェントのパフォーマンスを追跡および改善するための強力なツールも提供します。より細かいレベル
 Minw でコンパイルしたソフトウェアは Linux 環境でも使用できますか?
Mar 20, 2024 pm 05:06 PM
Minw でコンパイルしたソフトウェアは Linux 環境でも使用できますか?
Mar 20, 2024 pm 05:06 PM
Minw でコンパイルしたソフトウェアは Linux 環境でも使用できますか? Mingw は、Windows 上で実行できるプログラムをコンパイルおよび生成するために Windows プラットフォームで使用されるツール チェーンです。では、MingwでコンパイルしたソフトウェアはLinux環境でも利用できるのでしょうか?答えは「はい」ですが、追加の作業と手順が必要になります。 Windows でコンパイルされたプログラムを Linux 上で実行する最も一般的な方法は、Wine を使用することです。 Wine は、Linux や他の同様の国連で使用されるツールです。
 PHP を使用して Web サービスと API を呼び出すにはどうすればよいですか?
Jun 30, 2023 pm 03:03 PM
PHP を使用して Web サービスと API を呼び出すにはどうすればよいですか?
Jun 30, 2023 pm 03:03 PM
PHP の Web サービスと API 呼び出しの使用方法 インターネット テクノロジーの継続的な発展に伴い、Web サービスと API 呼び出しは開発者にとって不可欠な部分になりました。 Web サービスと API 呼び出しを使用すると、他のアプリケーションと簡単に対話してデータを取得したり、特定の機能を実装したりできます。人気のあるサーバー側スクリプト言語として、PHP は Web サービスと API 呼び出しの開発をサポートする豊富な機能とツールも提供します。この記事では、PHP を使用して、
 ライトコインウォレットのアドレスを表示する
Apr 07, 2024 pm 05:12 PM
ライトコインウォレットのアドレスを表示する
Apr 07, 2024 pm 05:12 PM
Litecoin ウォレットのアドレスを表示するには、Litecoin ウォレットにアクセスし、[受信] タブでアドレスを探します。ブロックチェーン ブラウザまたは API 呼び出しを使用することもできます。
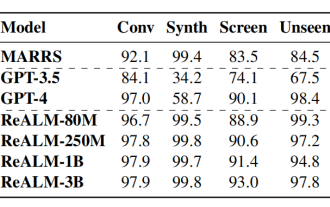 Siri をもう精神薄弱にさせません! Apple は、「GPT-4 よりもはるかに優れた新しいデバイス側モデルを定義しています。テキストを取り除き、画面情報を視覚的にシミュレートします。最小パラメータ モデルは、ベースライン システムよりも 5% 優れています。」
Apr 02, 2024 pm 09:20 PM
Siri をもう精神薄弱にさせません! Apple は、「GPT-4 よりもはるかに優れた新しいデバイス側モデルを定義しています。テキストを取り除き、画面情報を視覚的にシミュレートします。最小パラメータ モデルは、ベースライン システムよりも 5% 優れています。」
Apr 02, 2024 pm 09:20 PM
文:Noah | 51CTO Technology Stack (WeChat ID: blog51cto) 「精神薄弱気味」と常にユーザーから批判されるSiriは救われる! Siri は誕生以来、インテリジェント音声アシスタントの分野を代表するものの 1 つですが、そのパフォーマンスは長い間満足のいくものではありませんでした。しかし、Appleの人工知能チームが発表した最新の研究結果は、現状を大きく変えると予想されている。これらの結果は刺激的であり、この分野の将来に大きな期待を抱かせます。関連する研究論文の中で、Apple の AI 専門家は、Siri が画像内のコンテンツを識別するだけでなく、よりスマートで便利になるシステムについて説明しています。この機能モデルは ReALM と呼ばれ、GPT4.0 標準に基づいており、
 DeepSeek使用のためのFAQの概要
Feb 19, 2025 pm 03:45 PM
DeepSeek使用のためのFAQの概要
Feb 19, 2025 pm 03:45 PM
Deepseekai ToolユーザーガイドとFAQ Deepseekは、強力なAIインテリジェントツールです。 FAQ:異なるアクセス方法の違い:Webバージョン、アプリバージョン、API呼び出しの間に機能に違いはありません。アプリは、Webバージョンのラッパーにすぎません。ローカル展開は蒸留モデルを使用します。これは、DeepSeek-R1のフルバージョンよりもわずかに劣っていますが、32ビットモデルには理論的には90%のフルバージョン機能があります。居酒屋とは何ですか? Sillytavernは、APIまたはOllamaを介してAIモデルを呼び出す必要があるフロントエンドインターフェイスです。壊れた制限とは何ですか
 Bing Chat のベンチマーク: Wenxin Yiyan 言語モデルに基づく、Baidu Search の小規模パブリック ベータ版「会話」機能
May 13, 2023 am 09:31 AM
Bing Chat のベンチマーク: Wenxin Yiyan 言語モデルに基づく、Baidu Search の小規模パブリック ベータ版「会話」機能
May 13, 2023 am 09:31 AM
5月9日のニュースによると、ITハウスのネットユーザーらの寄稿によると、百度検索は最近、百度の文心宜燕ビッグ言語モデルに基づく生成AI「会話」機能の小規模な公開テストを開始したという。この製品は、Baidu の知識強化大規模言語モデル Wen Xinyiyan に基づいて構築されており、OpenAI の ChatGPT サービスを統合した後、Microsoft の検索エンジン Bing の NewBing をベンチマークします。ブランド広報研究所によると、百度AI対話の現在のテストチャネルは百度メインウェブサイトと百度アプリ、独立ウェブサイトはChat.Baidu.comで、このサービスを利用するユーザーは百度アカウントを持っていてログインする必要がある。現在、テスト対象外のユーザーは正常にURLにアクセスできず、ページに入った後は「404NotFound」が表示され、ページにアクセスすると「404NotFound」が表示されます。
 GPT-4 が新たな AI の嵐を引き起こしました。包囲されたウェン シンイーヤンは戦うことができるでしょうか?
Apr 11, 2023 pm 05:43 PM
GPT-4 が新たな AI の嵐を引き起こしました。包囲されたウェン シンイーヤンは戦うことができるでしょうか?
Apr 11, 2023 pm 05:43 PM
Wen Xinyiyan のリリース日を 3 月 16 日に設定した Baidu は、OpenAI、Google、Microsoft の攻撃を受けるとは予想していませんでした。まず、3 月 15 日の早朝、OpenAI は大規模なマルチモーダル Transformer モデル GPT をリリースしました。 - 4; その直後、大規模言語モデル PaLM の API インターフェースがオープンされ、開発者向けツール MakerSuite が開始されることが発表され、Wen Xinyiyan のリリース後も巨人たちは休むことはありませんでした。 Microsoft は 3 月 16 日、Word、PPT、Excel、OutLook、共同オフィス ソフトウェアの生産性を向上させると主張する AI 主導のオフィス アーティファクト Microsoft 365 Copilot をリリースしました。ターゲットCへのウェン・シンの言葉
