

大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクイン

Llama 3 に関して、新しいテスト結果があります -
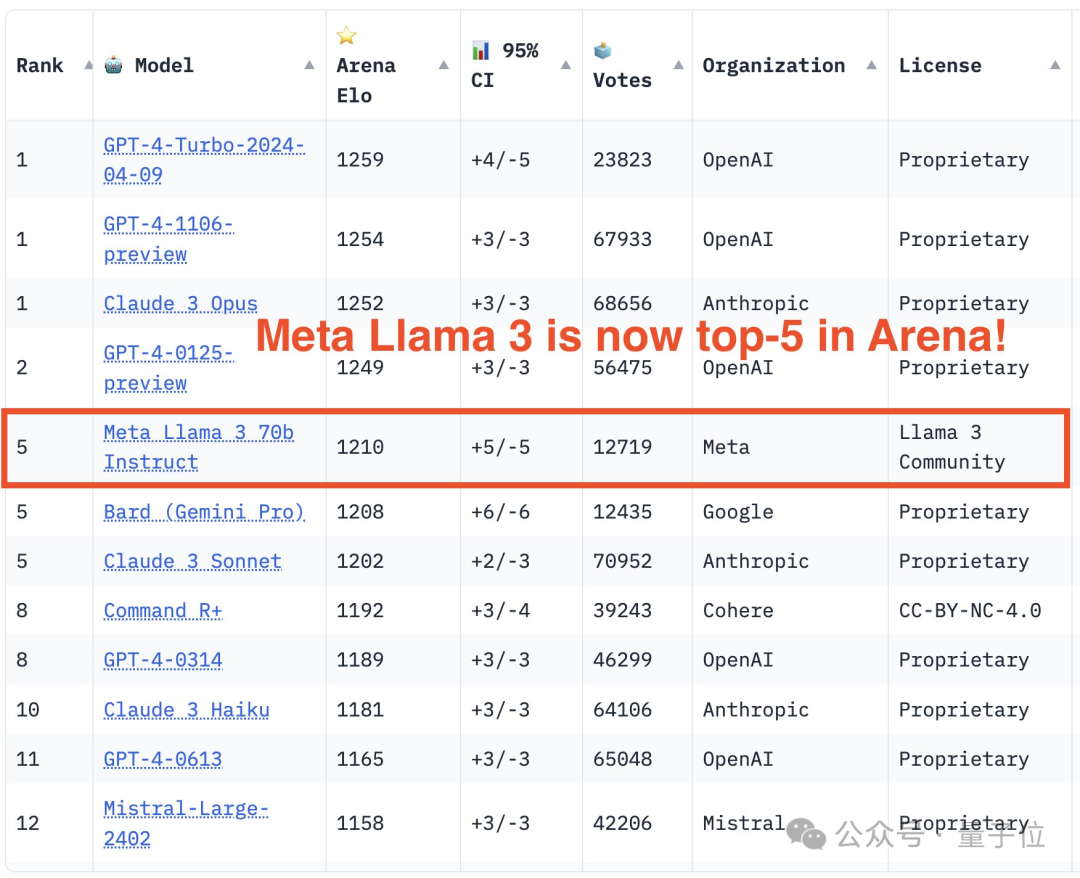
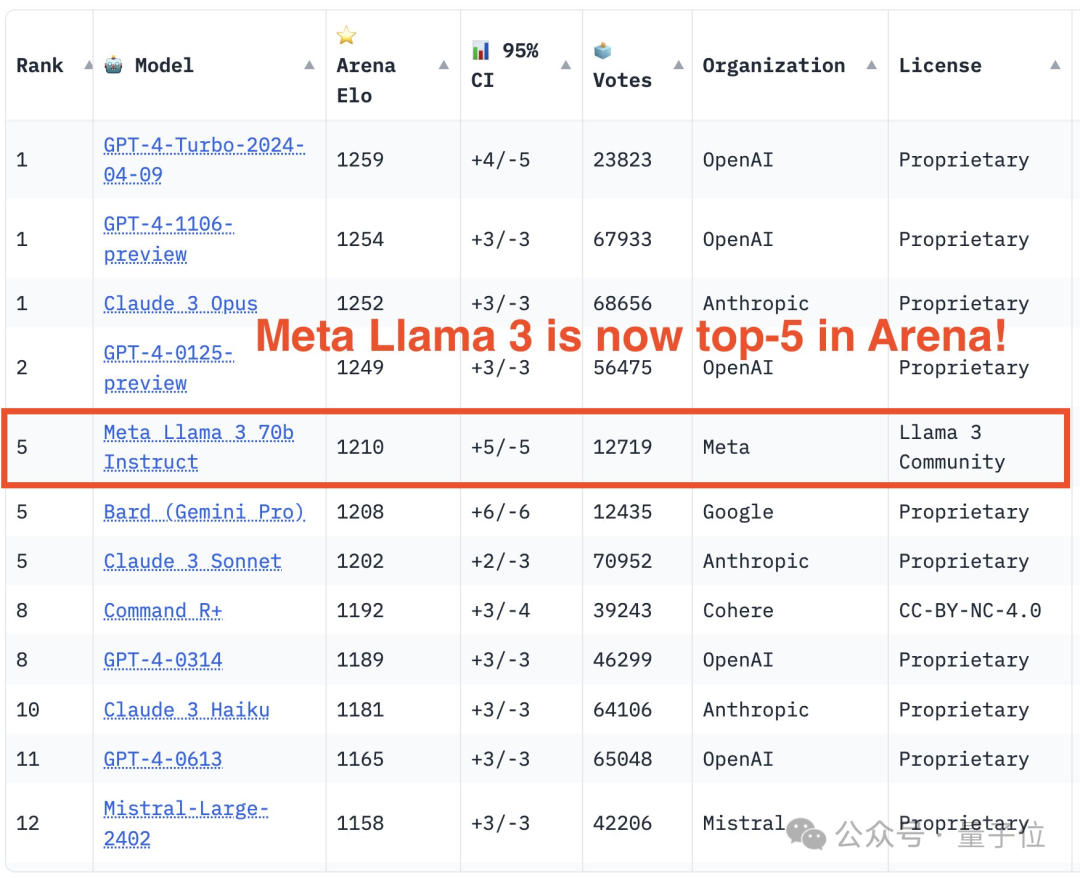
大規模なモデル評価コミュニティ LMSYS は大規模なモデルのランキング リストを発表し、Llama 3 は 5 位にランクされ、英語カテゴリでは GPT-4 と同率 1 位になりました。
 写真
写真
他のベンチマークとは異なり、このリストは 1 対 1 の戦いのモデルに基づいており、ネットワーク全体の評価者が独自の提案とスコアを作成します。
最終的に、Llama 3 がリストの 5 位にランクされ、GPT-4 と Claude 3 Super Cup Opus の 3 つの異なるバージョンが続きました。
イギリスのシングルリストでは、ラマ 3 がクロードを追い抜き、GPT-4 と並びました。
Meta の主任科学者である LeCun はこの結果に非常に満足し、ツイートをリツイートして「いいね」を残しました。
 写真
写真
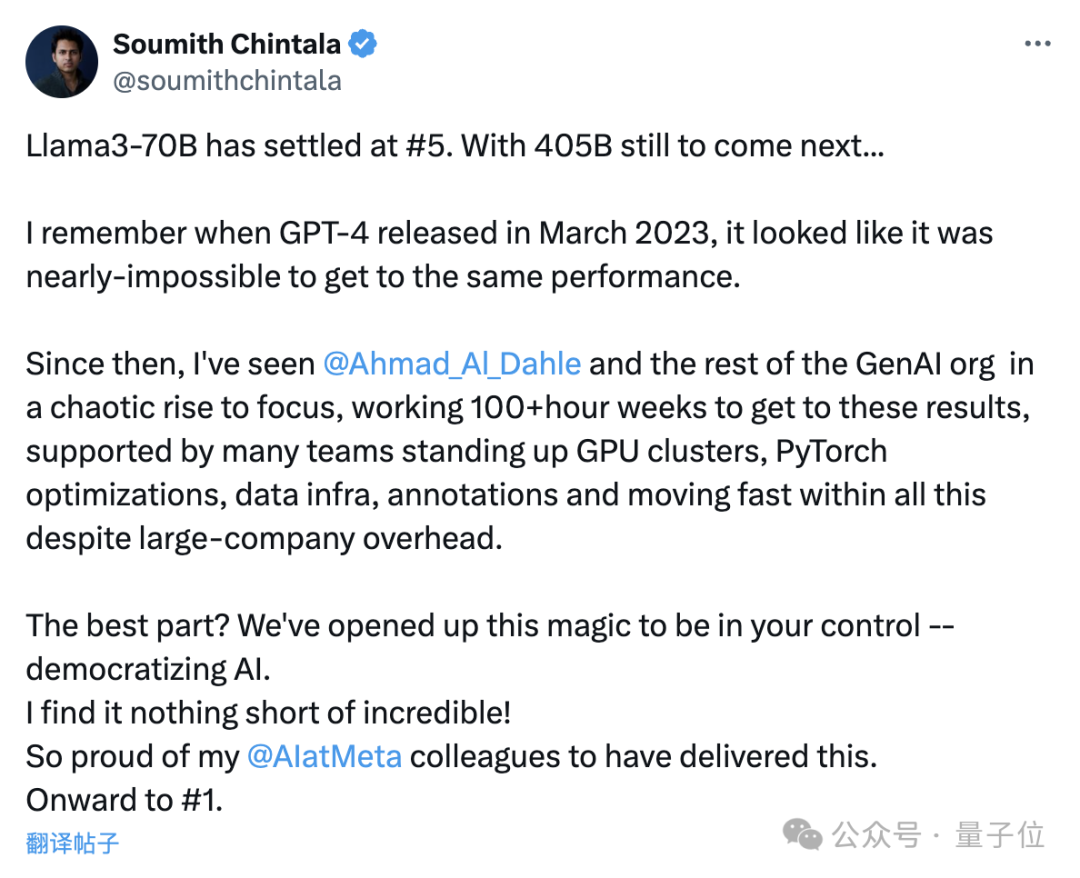
PyTorch の父である Soumith Chintala 氏も、このような結果は信じられないほど素晴らしく、Meta を誇りに思っていると興奮気味に述べました。
Llama 3の400Bバージョンはまだ出ていませんが、70Bパラメータだけで5位を獲得しました...
昨年3月にGPT-4がリリースされたとき、同じ性能のもの。
…
現在の AI の普及は本当に驚異的であり、このような成功を収めた Meta AI の同僚を非常に誇りに思っています。
 写真
写真
では、このリストは具体的にどのような結果を示しているのでしょうか?
90 近くのモデルが 750,000 ラウンドで競い合いました
最新のリストのリリースの時点で、LMSYS は 89 のモデルを含む 750,000 近くの大型モデルの単独戦闘結果を収集しました。
その中で、Llama 3 は 12,700 回参加し、GPT-4 には複数の異なるバージョンがあり、最も多く参加したのは 68,000 回です。
 写真
写真
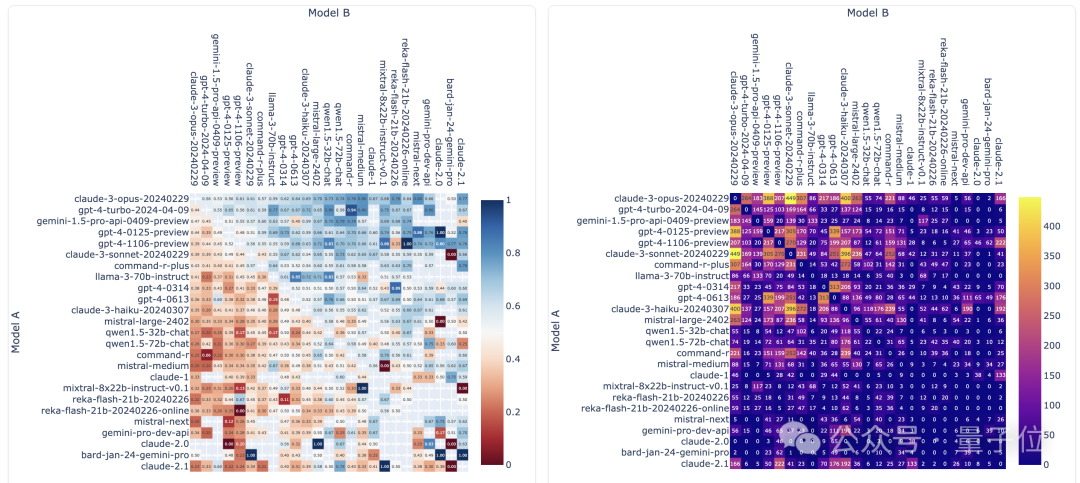
下の写真は、いくつかの人気モデルの競技数と勝率を示しています。写真内の 2 つの指標はいずれもドロー数をカウントしません。
 写真
写真
リストに関しては、LMSYS は一般リストと複数のサブリストに分かれており、GPT-4-Turbo が初期の 1106 バージョンと同率で 1 位、Claude 3 Super Large Cup Opus にランクされています。
GPT-4 の別のバージョン (0125) が 2 位にランクされ、僅差で Llama 3 が続きます。
しかし、さらに興味深いのは、新しいバージョン 0125 のパフォーマンスが古いバージョン 1106 ほどではないことです。
 写真
写真
英語のシングルリストでは、Llama 3 の結果は 2 つの GPT-4 と直接並び、0125 バージョンをも上回りました。
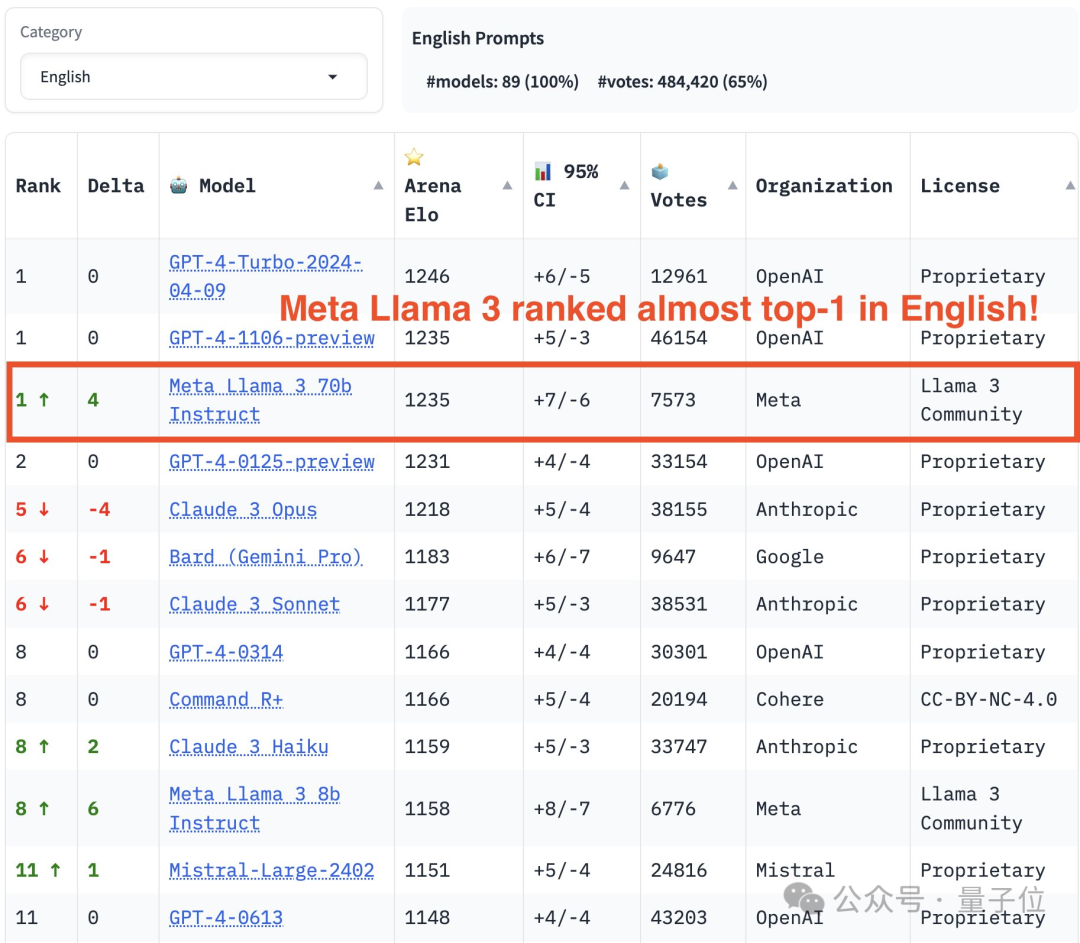 写真
写真
中国語能力ランキングの1位はClaude 3 OpusとGPT-4-1106が同率ですが、Llama 3は20位圏外にランクインしています。
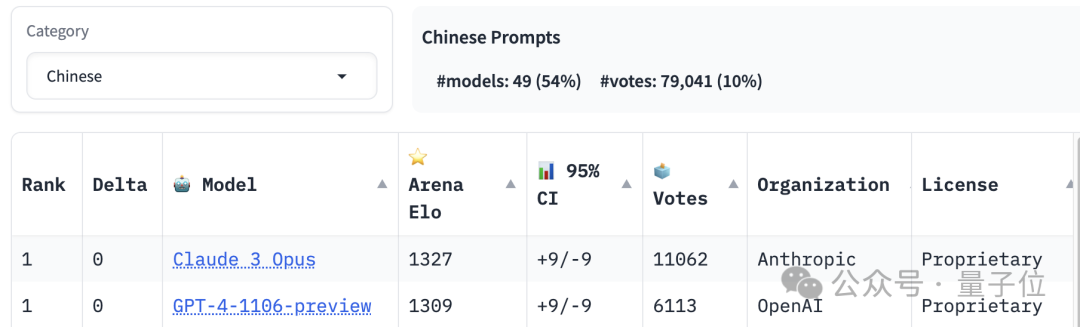 写真
写真
このリストでは、言語能力に加えて、長文テキストとコーディング能力についてもランキングが設定されており、Llama 3 も最高クラスにランクされています。
ところで、LMSYSの具体的な「ゲームルール」とは何なのでしょうか?
誰でも参加できる大規模な模型テスト
誰でも参加できる大規模な模型テストです。出題内容や評価基準は参加者自らが決定します。
具体的な「競争」プロセスは、バトルとサイド・バイ・サイドの2つのモードに分かれています。
 写真
写真
戦闘モードでは、テストインターフェイスに質問を入力した後、システムはライブラリ内の2つのモデルをランダムに呼び出します。テスターはシステムが誰を選択したかを知らず、「モデル」のみが選択されます。インターフェースA」と「モデルB」に表示されます。
モデルが答えを出力した後、評価者はどちらが優れているか、または同点であるかを選択する必要があります。もちろん、モデルのパフォーマンスが期待を満たさない場合は、対応するオプションがあります。
選択が行われた後にのみ、モデルのアイデンティティが明らかになります。
サイド・バイ・サイドでは、ユーザーがPKする指定されたモデルを選択します。残りのテストプロセスはバトルモードと同じです。
ただし、バトルの匿名モードでの投票結果のみがカウントされます。会話中にモデルが注意を払わない場合、あなたの身元を暴露すると結果が無効になる可能性があります。
 写真
写真
各モデルの他のモデルに対する勝率に応じて、次のようなイメージを描くことができます:
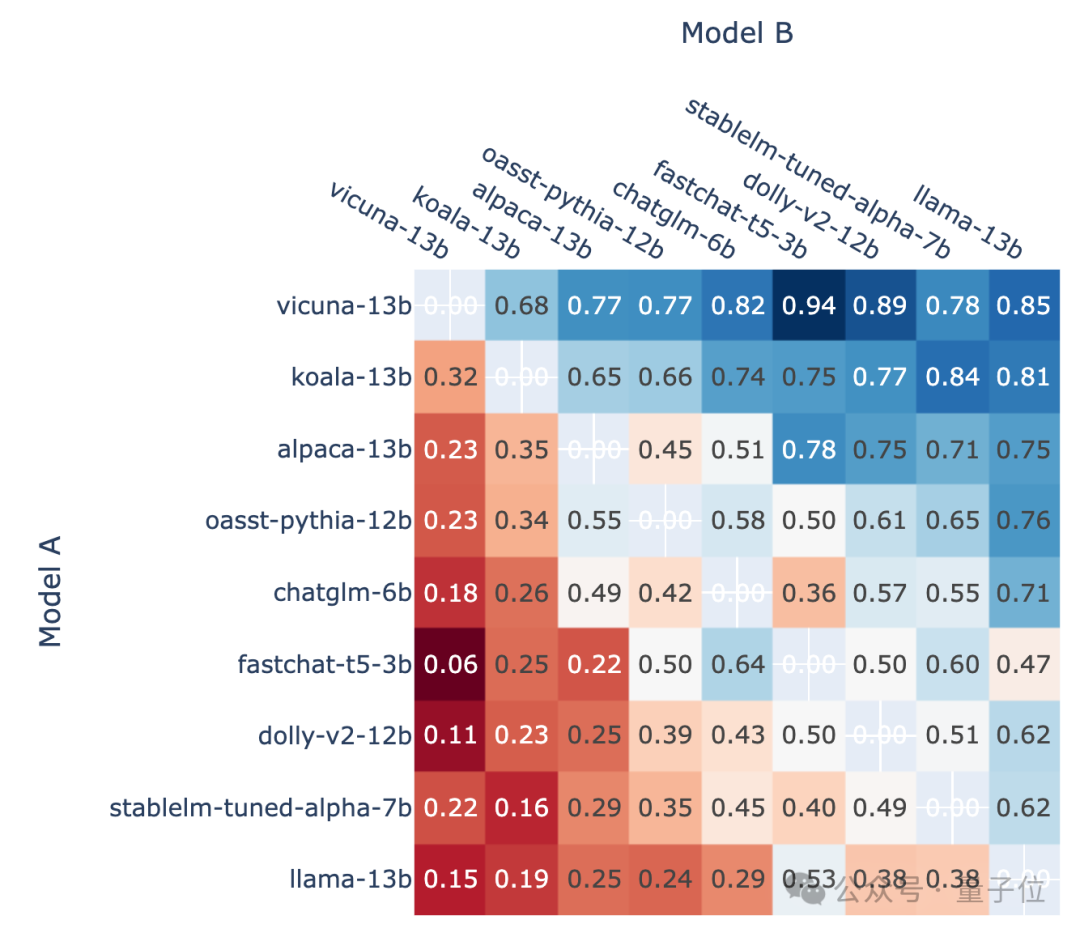 写真
写真
△概略図、以前のバージョン
そして、最終的なランキングはWinを使用していますレート データは Elo 評価システムを通じてスコアに変換されます。
Elo レーティング システムは、アメリカの物理学教授 Arpad Elo によって設計された、プレイヤーの相対的なスキル レベルを計算する方法です。
特にLMSYSでは、初期条件で全機種のレーティング(R)を1000とし、このような計算式に基づいて期待勝率(E)を計算します。
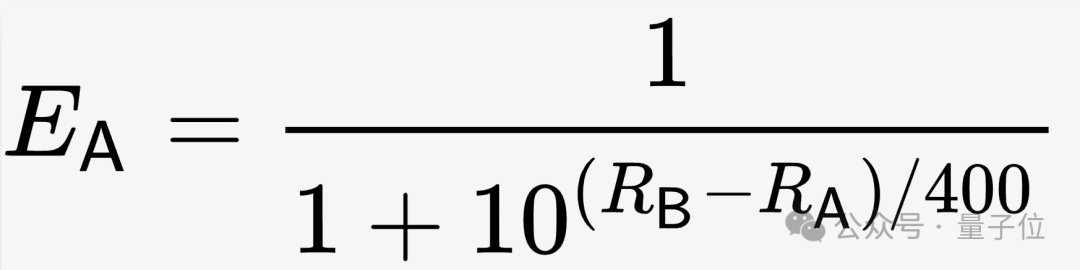 写真
写真
テストが進むにつれて、スコアは実際のスコア (S) に応じて修正されます。S には、勝ち、負けの 3 つの状況に対応する 1、0、0.5 の 3 つの値があります。と描画をそれぞれ行います。
補正アルゴリズムは次の式に示されています。K は係数であり、実際の状況に応じてテスターが調整する必要があります。
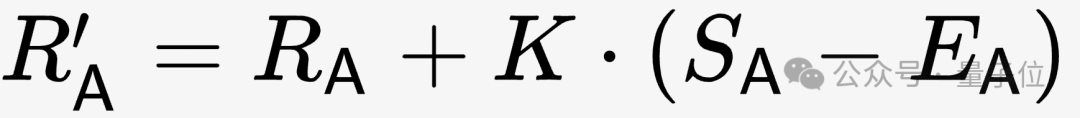 Pictures
Pictures
最後に、すべての有効なデータが計算に含まれた後、モデルの Elo スコアが取得されます。
しかし、実際の運用中に、LMSYSチームはこのアルゴリズムの安定性が不十分であることに気づき、統計的手法を使用して修正しました。
彼らはブートストラップ法を使用してサンプリングを繰り返し、より安定した結果を得て、信頼区間を推定しました。
最終的に改訂された Elo スコアが、リストのランキングの基礎になりました。
One More Thing
Llama 3 はすでに大規模モデル推論プラットフォーム Groq (Musk の Grok ではありません) 上で実行できます。
このプラットフォームの最大のハイライトはその「速度」です。以前は、Mixtral モデルを使用して 1 秒あたり 500 トークン近い速度を達成していました。
Llama 3 の実行も非常に高速です。実際のテストによると、70B バージョンは 1 秒あたり約 300 トークンを実行でき、8B バージョンは 800 近くです。
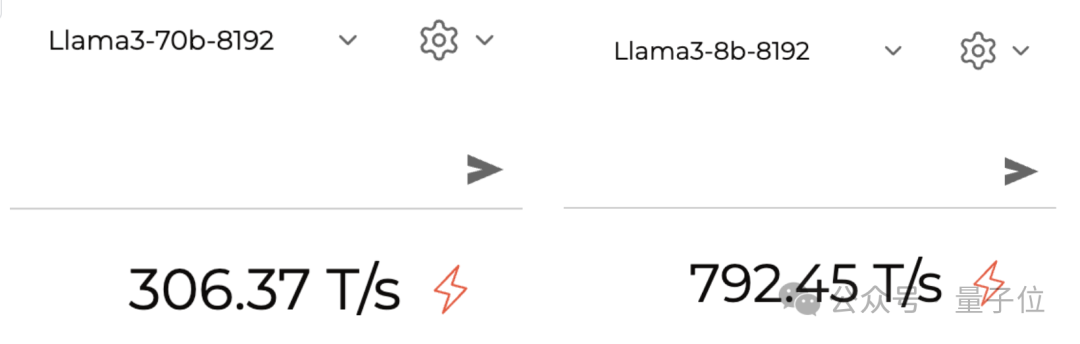 写真
写真
参考リンク:
[1]https://lmsys.org/blog/2023-05-03-arena/
[2]https://chat.lmsys.org/?leaderboard
[3]https://twitter.com/lmsysorg/status/1782483699449332144
以上が大型モデル間の1対1バトル75万ラウンド、GPT-4が優勝、Llama 3が5位にランクインの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7492
7492
 15
1377
52
77
11
19
41
15
1377
52
77
11
19
41

 ブートストラップ検索バーを取得する方法
Apr 07, 2025 pm 03:33 PM
ブートストラップ検索バーを取得する方法
Apr 07, 2025 pm 03:33 PM
ブートストラップを使用して検索バーの値を取得する方法:検索バーのIDまたは名前を決定します。 JavaScriptを使用してDOM要素を取得します。要素の値を取得します。必要なアクションを実行します。
 ブートストラップの垂直センタリングを行う方法
Apr 07, 2025 pm 03:21 PM
ブートストラップの垂直センタリングを行う方法
Apr 07, 2025 pm 03:21 PM
ブートストラップを使用して垂直センタリングを実装します。FlexBoxメソッド:D-Flex、Justify-Content-Center、Align-Items-Centerクラスを使用して、FlexBoxコンテナに要素を配置します。 ALIGN-ITEMS-CENTERクラス方法:FlexBoxをサポートしていないブラウザの場合、親要素の高さが定義されている場合、Align-Items-Centerクラスを使用します。
 ブートストラップに写真を挿入する方法
Apr 07, 2025 pm 03:30 PM
ブートストラップに写真を挿入する方法
Apr 07, 2025 pm 03:30 PM
ブートストラップに画像を挿入する方法はいくつかあります。HTMLIMGタグを使用して、画像を直接挿入します。ブートストラップ画像コンポーネントを使用すると、レスポンシブ画像とより多くのスタイルを提供できます。画像サイズを設定し、IMG-Fluidクラスを使用して画像を適応可能にします。 IMGボーダークラスを使用して、境界線を設定します。丸い角を設定し、IMGラウンドクラスを使用します。影を設定し、影のクラスを使用します。 CSSスタイルを使用して、画像をサイズ変更して配置します。背景画像を使用して、背景イメージCSSプロパティを使用します。
 ブートストラップのフレームワークをセットアップする方法
Apr 07, 2025 pm 03:27 PM
ブートストラップのフレームワークをセットアップする方法
Apr 07, 2025 pm 03:27 PM
Bootstrapフレームワークをセットアップするには、次の手順に従う必要があります。1。CDNを介してブートストラップファイルを参照してください。 2。独自のサーバーでファイルをダウンロードしてホストします。 3。HTMLにブートストラップファイルを含めます。 4.必要に応じてSASS/LESSをコンパイルします。 5。カスタムファイルをインポートします(オプション)。セットアップが完了したら、Bootstrapのグリッドシステム、コンポーネント、スタイルを使用して、レスポンシブWebサイトとアプリケーションを作成できます。
 ブートストラップボタンの使用方法
Apr 07, 2025 pm 03:09 PM
ブートストラップボタンの使用方法
Apr 07, 2025 pm 03:09 PM
ブートストラップボタンの使用方法は?ブートストラップCSSを導入してボタン要素を作成し、ブートストラップボタンクラスを追加してボタンテキストを追加します
 ブートストラップにスプリットラインを書く方法
Apr 07, 2025 pm 03:12 PM
ブートストラップにスプリットラインを書く方法
Apr 07, 2025 pm 03:12 PM
ブートストラップスプリットラインを作成するには2つの方法があります。タグを使用して、水平方向のスプリットラインを作成します。 CSS Borderプロパティを使用して、カスタムスタイルのスプリットラインを作成します。

 ブートストラップの日付を表示する方法
Apr 07, 2025 pm 03:03 PM
ブートストラップの日付を表示する方法
Apr 07, 2025 pm 03:03 PM
回答:ブートストラップの日付ピッカーコンポーネントを使用して、ページで日付を表示できます。手順:ブートストラップフレームワークを紹介します。 HTMLで日付セレクター入力ボックスを作成します。ブートストラップは、セレクターにスタイルを自動的に追加します。 JavaScriptを使用して、選択した日付を取得します。
