

リリースから数時間以内に、Microsoft は GPT-4 に匹敵する大規模なオープン ソース モデルを数秒で削除しました。毒物検査を受けるのを忘れた

先週、MicrosoftはGPT-4レベルともいえるWizardLM-2と呼ばれるオープンソースモデルを空輸しました。
意外なことに、投稿されてから数時間後にはすぐに削除されました。
一部のネチズンは、WizardLM のモデルの重みと発表の投稿がすべて削除され、Microsoft のコレクションになくなったことを突然発見しました。このサイトへの言及を除けば、この公式の Microsoft プロジェクトを証明する証拠は見つかりませんでした。
GitHub プロジェクトのホームページが 404 になりました。
プロジェクトアドレス: https://wizardlm.github.io/
HF上のモデルの重みも含めて全て消えました…
ネットワーク全体顔は混乱に満ちていますが、なぜ WizardLM はなくなったのですか?

しかし、Microsoft がこれを行ったのは、チームがモデルを「テスト」するのを忘れたからです。
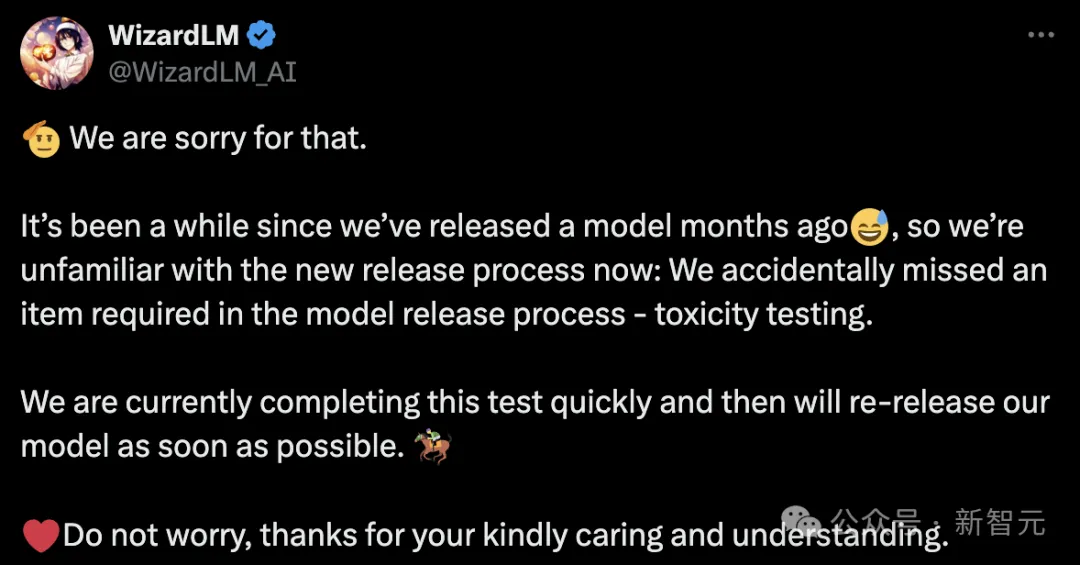
その後、Microsoft チームが現れて謝罪し、数か月前に WizardLM がリリースされてからしばらく時間が経っていたため、新しいリリースのプロセスにまだ慣れていなかった、と説明しました。
モデルのリリースプロセスで必要な項目の 1 つを誤って見逃してしまいました:中毒テスト
Microsoft WizardLM が第 2 世代にアップグレードされました
昨年 6 月に微調整されましたLlaMA ベース 第一世代の WizardLM がリリースされると、オープンソース コミュニティから大きな注目を集めました。

論文アドレス: https://arxiv.org/pdf/2304.12244.pdf
その後、WizardCoder のコード版が誕生しました - Code Llama をベースにし、Evol を使用して微調整されたモデルです -指示する。
テスト結果は、HumanEval での WizardCoder の pass@1 が驚くべき 73.2% に達し、オリジナルの GPT-4 を上回ったことを示しています。
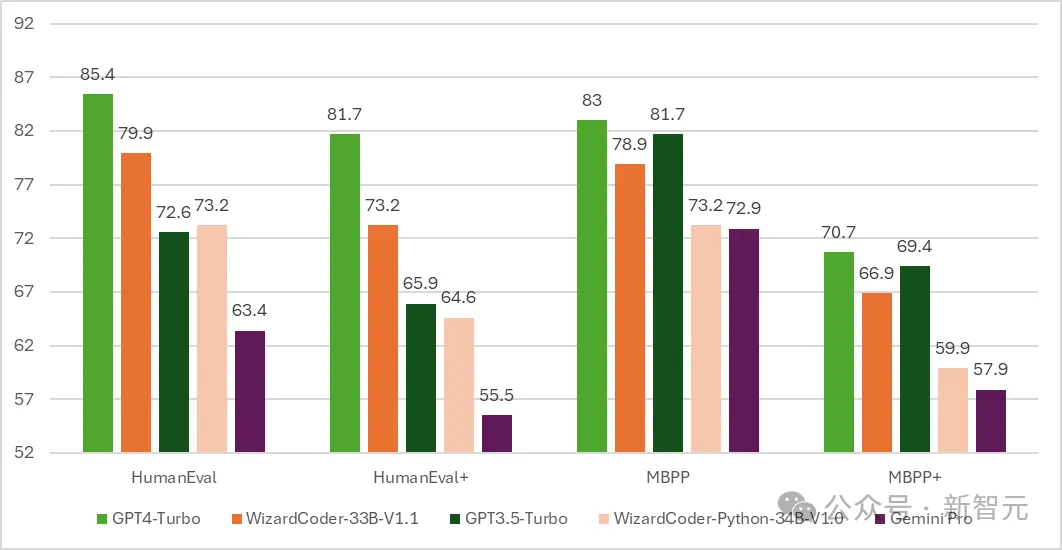
時間が4月15日に進むにつれ、Microsoftの開発者は新世代のWizardLMを正式に発表しました。今回はMixtral 8x22Bから微調整されています。
これには、8x22B、70B、および 7B という 3 つのパラメーター バージョンが含まれています。

最も注目に値するのは、MT-Bench ベンチマーク テストにおいて、新モデルが圧倒的な優位性を達成したことです。
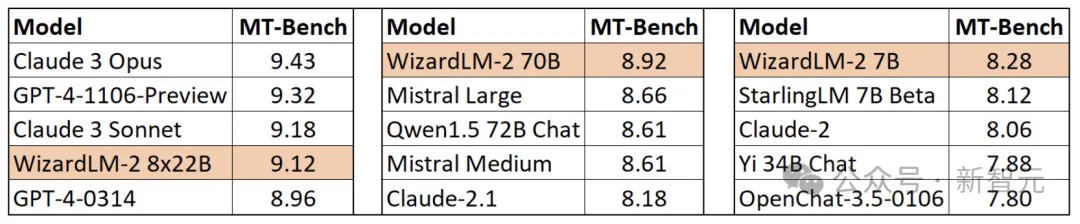
具体的には、WizardLM 8x22B モデルの最大パラメーター バージョンのパフォーマンスは、GPT-4 および Claude 3 にほぼ近いです。
同じパラメータスケールでは、70B バージョンが 1 位にランクされます。
7Bバージョンは最も高速で、10倍のパラメータスケールで上位モデルと同等のパフォーマンスを実現することもできます。
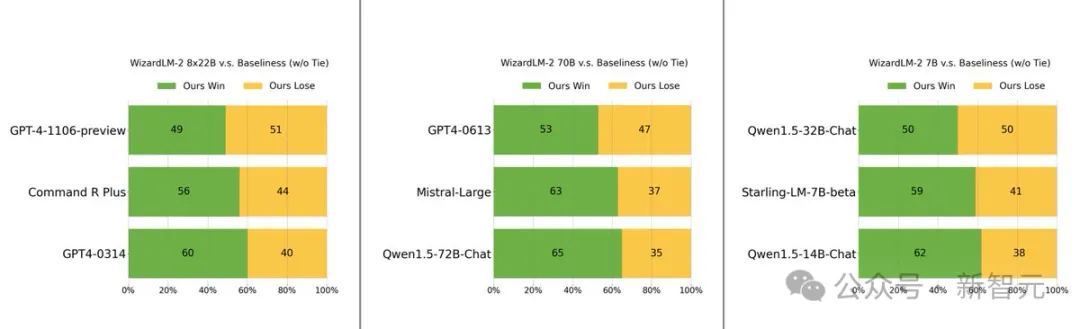
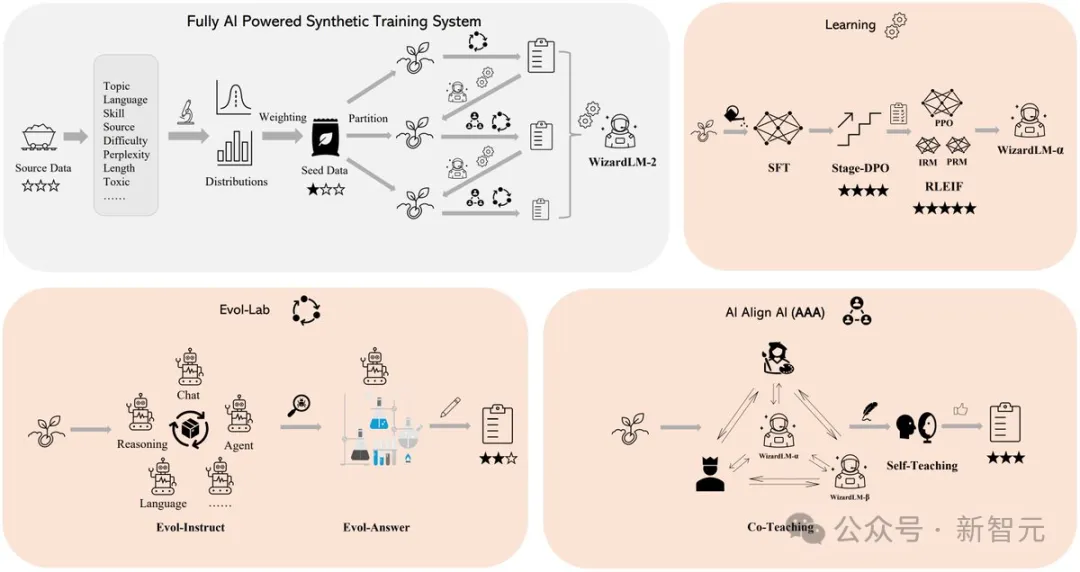
WizardLM 2 の優れたパフォーマンスの秘密は、Microsoft が開発した革新的なトレーニング方法論 Evol-Instruct にあります。
Evol-Instruct は、大規模な言語モデルを活用して、最初の命令セットをますます複雑なバリアントに繰り返し書き換えます。これらの進化した命令データは基本モデルを微調整するために使用され、複雑なタスクを処理する能力が大幅に向上します。
もう 1 つは、WizardLM 2 の開発プロセスでも重要な役割を果たした強化学習フレームワーク RLEIF です。
WizardLM 2のトレーニングでは、AI Align AI (AAA)手法も採用されており、複数の主要な大規模モデルが相互に指導し、改善することができます。
AAAのフレームワークは、「共指導」と「自習」という2つの主要な要素で構成されています。
この段階では、WizardLM と、ライセンスを取得したさまざまなオープンソースおよび独自の高度なモデルが、シミュレーション チャット、品質判断、改善提案、スキル ギャップの解消を共同指導します。

モデルは互いに通信し、フィードバックを提供することで、仲間から学び、能力を向上させることができます。
自己学習の場合、WizardLM は、積極的な自己学習を通じて、教師あり学習用の新しい進化的トレーニング データと強化学習用の優先データを生成できます。
この自己学習メカニズムにより、モデルは独自に生成されたデータとフィードバック情報から学習することで、パフォーマンスを継続的に向上させることができます。
さらに、WizardLM 2 モデルは、生成された合成データを使用してトレーニングされました。
研究者の見解では、大規模モデルのトレーニング データはますます枯渇しており、AI によって慎重に作成されたデータと、AI によって徐々に監視されるモデルが、より強力な人工知能を実現する唯一の方法になると考えられています。
そこで彼らは、WizardLM-2 を改善するために、完全に AI 主導の合成トレーニング システムを作成しました。
速いネチズンはすでにウェイトをダウンロードしています
しかし、データベースが削除される前に、多くの人がすでにモデルのウェイトをダウンロードしていました。
モデルが削除される前に、数人のユーザーがいくつかの追加のベンチマークでもテストしました。
幸いなことに、それをテストしたネチズンは7Bモデルに感銘を受け、ローカルアシスタントタスクを実行するための最初の選択肢になるだろうと述べました。

誰かが毒物検査も行ったところ、WizardLM-8x22Bのスコアは98.33、ベースのMixtral-8x22Bのスコアは89.46、Mixtral 8x7B-Indictのスコアは92.93であることがわかりました。
スコアが高いほど優れており、WizardLM-8x22B が依然として非常に強力であることを意味します。

中毒検査が無い場合はモデルの発送は絶対に不可能です。
大きなモデルは幻覚を起こしやすいことは誰もが知っています。
WizardLM 2 が回答に「有害で偏った不正確な」コンテンツを出力する場合、大規模なモデルには適していません。
特に、これらのエラーはネットワーク全体の注目を集めており、マイクロソフト自体への批判も引き起こし、当局による調査を受ける可能性もあります。
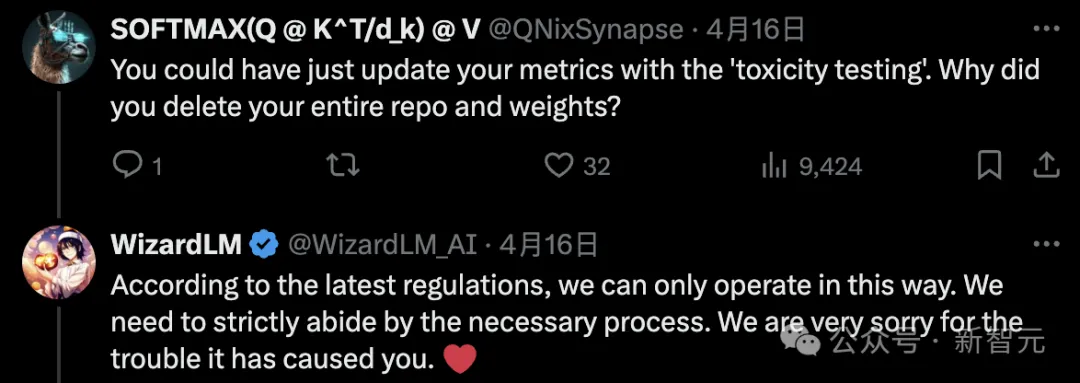
一部のネチズンは混乱し、「中毒テスト」を通じて指標を更新できると言いました。なぜリポジトリとウェイト全体を削除するのでしょうか?
Microsoft の作成者は、最新の社内規定によれば、これはのみ実行できると述べています。
「ロボトミー手術」のないモデルが欲しいと言う人もいます。

ただし、開発者はまだ辛抱強く待つ必要があり、Microsoft チームはテストが完了したらオンラインに戻ることを約束しています。
以上がリリースから数時間以内に、Microsoft は GPT-4 に匹敵する大規模なオープン ソース モデルを数秒で削除しました。毒物検査を受けるのを忘れたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7514
7514
 15
1378
52
79
11
19
64
15
1378
52
79
11
19
64

 H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトを実行するには、次の手順が必要です。Webサーバー、node.js、開発ツールなどの必要なツールのインストール。開発環境の構築、プロジェクトフォルダーの作成、プロジェクトの初期化、コードの書き込み。開発サーバーを起動し、コマンドラインを使用してコマンドを実行します。ブラウザでプロジェクトをプレビューし、開発サーバーURLを入力します。プロジェクトの公開、コードの最適化、プロジェクトの展開、Webサーバーの構成のセットアップ。
 Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
GiteEpages静的Webサイトの展開が失敗しました:404エラーのトラブルシューティングと解像度Giteeを使用する
 H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページは、コードの脆弱性、ブラウザー互換性、パフォーマンスの最適化、セキュリティの更新、ユーザーエクスペリエンスの改善などの要因のため、継続的に維持する必要があります。効果的なメンテナンス方法には、完全なテストシステムの確立、バージョン制御ツールの使用、定期的にページのパフォーマンスの監視、ユーザーフィードバックの収集、メンテナンス計画の策定が含まれます。
 XMLをExcelに変換する方法
Apr 03, 2025 am 08:54 AM
XMLをExcelに変換する方法
Apr 03, 2025 am 08:54 AM
XMLをExcelに変換するには、組み込みのExcel機能またはサードパーティツールを使用する方法は2つあります。サードパーティツールには、XML To Excel Converter、XML2Excel、XML Candyが含まれます。
 GOプログラミングでは、MySQLとRedisの間で接続を正しく管理し、リソースをリリースする方法は?
Apr 02, 2025 pm 05:03 PM
GOプログラミングでは、MySQLとRedisの間で接続を正しく管理し、リソースをリリースする方法は?
Apr 02, 2025 pm 05:03 PM
GOプログラミングのリソース管理:MySQLとRedisは、特にデータベースとキャッシュを使用して、リソースを正しく管理する方法を学習するために接続およびリリースします...
 AIツールを使用して、React Viteプロジェクトでフォアグラウンドページをすばやく構築するにはどうすればよいですか?
Apr 04, 2025 pm 01:45 PM
AIツールを使用して、React Viteプロジェクトでフォアグラウンドページをすばやく構築するにはどうすればよいですか?
Apr 04, 2025 pm 01:45 PM
バックエンド開発でフロントエンドページをすばやく構築する方法は? 3年または4年の経験を持つバックエンド開発者として、彼は基本的なJavaScript、CSS、HTMLを習得しました...
 自分でH5ページを作成する方法を学ぶことができますか?
Apr 06, 2025 am 06:36 AM
自分でH5ページを作成する方法を学ぶことができますか?
Apr 06, 2025 am 06:36 AM
自習H5ページの生産が可能ですが、迅速な成功ではありません。設計、フロントエンド開発、バックエンド相互作用ロジックを含むHTML、CSS、およびJavaScriptをマスターする必要があります。練習が鍵であり、チュートリアルを完成させ、資料のレビューを行い、オープンソースプロジェクトに参加することで学びます。パフォーマンスの最適化も重要であり、画像の最適化、HTTP要求の削減、適切なフレームワークの使用が必要です。自習への道は長く、継続的な学習とコミュニケーションが必要です。
 ブートストラップが変更された後の結果を表示する方法
Apr 07, 2025 am 10:03 AM
ブートストラップが変更された後の結果を表示する方法
Apr 07, 2025 am 10:03 AM
変更されたブートストラップの結果を表示する手順:ブラウザでHTMLファイルを直接開き、ブートストラップファイルが正しく参照されることを確認します。ブラウザキャッシュ(Ctrl Shift R)をクリアします。 CDNを使用する場合、開発者ツールでCSSを直接変更して、エフェクトをリアルタイムで表示できます。 Bootstrapソースコードを変更する場合は、ローカルファイルをダウンロードして交換するか、Webpackなどのビルドツールを使用してビルドコマンドを再実行します。
