

CVPR 2024 | フォトリアルなシーン生成のための LiDAR 拡散モデル

元のタイトル: Towards Realistic Scene Generation with LiDAR Diffusion Models
ペーパーリンク: https://hancyran.github.io/assets/paper/lidar_diffusion.pdf
コードリンク: https://lidar-diffusion.github. io
著者の所属: CMU Toyota Research Institute 南カリフォルニア大学

論文のアイデア:
拡散モデル (DM) はフォトリアリスティックな画像合成に優れていますが、LIDAR シーンの生成に適応させます 存在は大きな課題に直面しています。これは主に、点空間で動作する DM が LIDAR シーンの曲線パターンと 3 次元特性を維持することが難しく、表現能力のほとんどが消費されるためです。この論文では、学習プロセスに幾何学的圧縮を組み込むことで現実世界の LiDAR シナリオをシミュレートする LiDAR 拡散モデル (LiDM) を提案します。このペーパーでは、現実世界の LIDAR パターンをシミュレートするための曲線圧縮と、完全な 3D オブジェクト コンテキストを取得するためのパッチごとのエンコーディングを紹介します。この論文では、これら 3 つのコア設計を使用して、ポイントベースの DM と比較して高い効率 (最大 107 倍高速) を維持しながら、無条件 LIDAR 生成シナリオで新しい SOTA を確立します。さらに、この論文では、LIDAR シーンを潜在空間に圧縮することで、DM がセマンティック マップ、カメラ ビュー、テキスト キューなどのさまざまな条件下で制御できるようにします。
主な貢献:
この論文は、任意の入力条件に基づいて現実的な LIDAR シーンを生成できる生成モデルである、新しい Laser Dart Diffusion Model (LiDM) を提案します。私たちの知る限り、これはマルチモーダルな条件から LIDAR シーンを生成できる最初の方法です。
この論文では、現実的なレーザー パターンを維持するためのカーブ レベルの圧縮、シーン レベルのジオメトリのモデルを標準化するためのポイント レベルの座標監視、および 3D オブジェクトのコンテキストを完全にキャプチャするためのブロック レベルのエンコーディングを紹介します。
この論文では、距離画像、疎ボリューム、点群などのさまざまな表現を比較しながら、知覚空間で生成されたレーザーシーンの品質を包括的かつ定量的に評価するための 3 つの指標を紹介します。
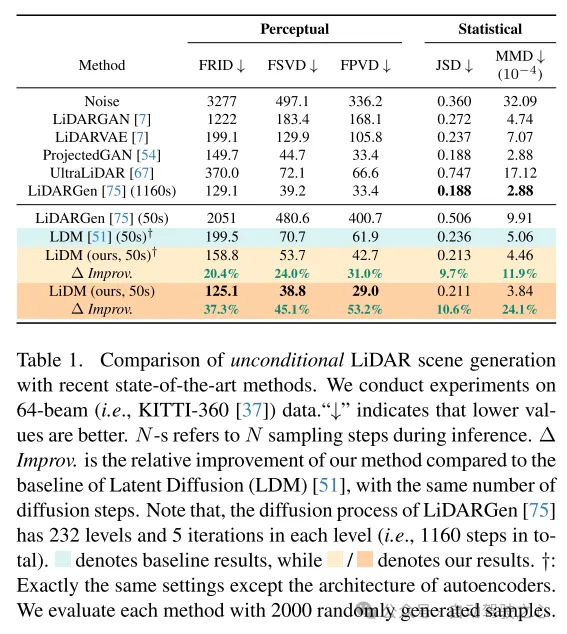
この記事の手法は、64 ラインの LIDAR シーンを使用した無条件シーン合成の最新レベルを達成し、ポイントベースの拡散モデルと比較して最大 107 倍の高速化を達成しました。
Web デザイン:
近年、視覚的に魅力的で非常に現実的な画像を生成できる条件付き生成モデルが急速に開発されています。これらのモデルの中でも、拡散モデル (DM) は、その非の打ちどころのないパフォーマンスにより、最も人気のある手法の 1 つとなっています。任意の条件下で生成を実現するために、潜在拡散モデル (LDM) [51] はクロスアテンション メカニズムと畳み込みオートエンコーダーを組み合わせて高解像度画像を生成します。その後の拡張機能 (Stable Diffusion [2]、Midjourney [1]、ControlNet [72] など) により、条件付き画像合成の可能性がさらに強化されました。
この成功は、この記事の考えを引き起こしました: 制御可能な拡散モデル (DM) を自動運転とロボット工学における LIDAR シーン生成に適用できるか?たとえば、一連の境界ボックスが与えられた場合、これらのモデルは対応する LIDAR シーンを合成し、それによってこれらの境界ボックスを高品質で高価なアノテーション データに変換できますか?あるいは、一連の画像だけから 3D シーンを生成することは可能ですか?さらに野心的なのは、制御されたシミュレーション用の言語駆動型 LIDAR ジェネレーターを設計できないか?これらの絡み合った質問に答えるために、このペーパーの目標は、複数の条件 (レイアウト、カメラ ビュー、テキストなど) を組み合わせて現実的な LIDAR シーンを生成できる拡散モデルを設計することです。
この目的を達成するために、この記事では、自動運転分野における普及モデル (DM) に関する最近の研究からいくつかの洞察を引き出します。 [75] では、無条件 LIDAR シーン生成のためにポイントベースの拡散モデル (つまり、LiDARGen) が導入されています。ただし、このモデルでは、多くの場合、ノイズの多い背景 (道路、壁など) やぼやけたオブジェクト (車など) が生成され、現実からかけ離れた LIDAR シーンが生成されます (図 1 を参照)。さらに、圧縮を行わずにポイントを拡散すると、推論プロセスの計算が遅くなります。さらに、パッチベースの拡散モデル (すなわち、潜在拡散 [51]) を LIDAR シーンの生成に直接適用すると、定性的および定量的に満足のいくパフォーマンスを達成できません (図 1 を参照)。
条件付きの現実的な LIDAR シーン生成を実現するために、この論文では、上記の質問に答え、最近の研究の欠点に対処する LIDAR 拡散モデル (LiDM) と呼ばれる曲線ベースのジェネレーターを提案します。 LiDM は、境界ボックス、カメラ画像、セマンティック マップなどの任意の条件を処理できます。 LiDM は、LiDAR シーン表現として距離画像を利用します。これは、検出 [34、43]、セマンティック セグメンテーション [44、66]、生成 [75] などのさまざまな下流タスクで非常に一般的です。この選択は、距離画像と点群間の可逆的かつロスレス変換と、高度に最適化された 2D 畳み込み演算から得られる重要な利点に基づいています。拡散プロセス中に LIDAR シーンの意味的および概念的な本質を把握するために、私たちの方法では、拡散プロセスの前に LIDAR シーンのエンコード点を知覚的に等価な潜在空間に変換します。
現実世界の LIDAR データの現実的なシミュレーションをさらに改善するために、この記事では、パターンの信頼性、幾何学的信頼性、オブジェクトの信頼性という 3 つの主要なコンポーネントに焦点を当てます。まず、この論文では、自動エンコード中に点の曲線パターンを維持するために曲線圧縮を利用していますが、これは [59] からインスピレーションを得ています。次に、幾何学的信頼性を達成するために、この論文ではポイントレベルの座標監視を導入して、オートエンコーダにシーンレベルの幾何学的構造を理解するよう教えます。最後に、ブロックレベルのダウンサンプリング戦略を追加して受容野を拡張し、視覚的により大きなオブジェクトの完全なコンテキストをキャプチャします。これらの提案されたモジュールによって強化された結果の知覚空間により、拡散モデルは高品質の LIDAR シーンを効率的に合成できるようになり (図 1 を参照)、ポイントベースの拡散モデル (NVIDIA 107x で評価) と比較して速度の点でも優れたパフォーマンスを発揮します。 RTX 3090) をサポートし、あらゆるタイプのイメージベースおよびトークンベースの条件をサポートします。
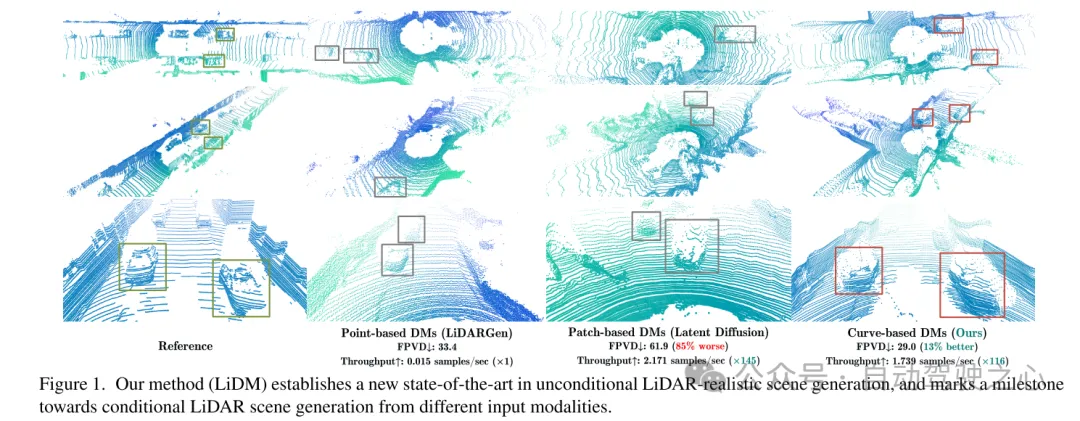
図 1. 私たちの方法 (LiDM) は、無条件 LiDAR リアル シーン生成における新しい SOTA を確立し、さまざまな入力モダリティから条件付き LiDAR シーンを生成する方向へのマイルストーンをマークします。
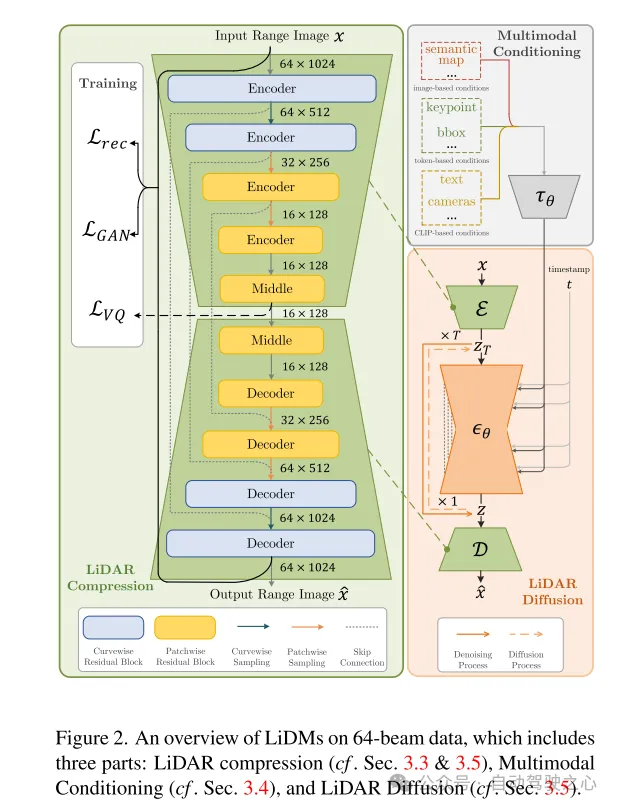
図 2. LiDAR 圧縮 (セクション 3.3 および 3.5 を参照)、マルチモーダル条件付け (セクション 3.4 を参照)、および LiDAR 拡散 (セクション 3.5 を参照) の 3 つの部分を含む 64 ライン データの LiDM の概要。
実験結果:

図 3. 64 行シナリオにおける LiDARGen [75]、Latent Diffusion [51]、およびこの論文による LiDM の例。

図 4. この記事の 32 行シナリオにおける LiDM の例。
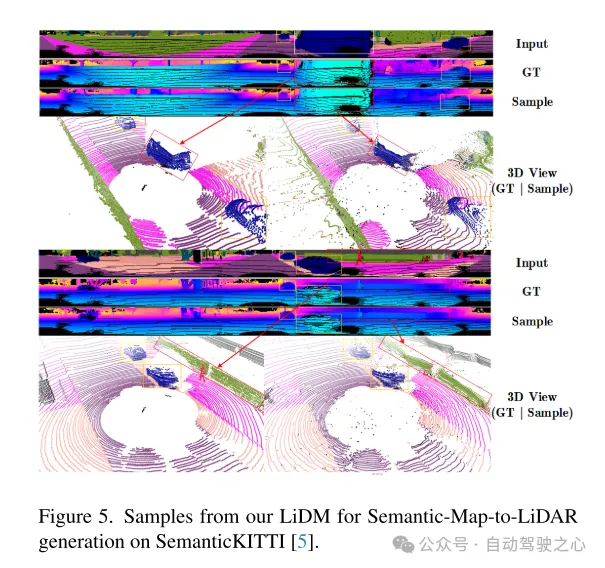
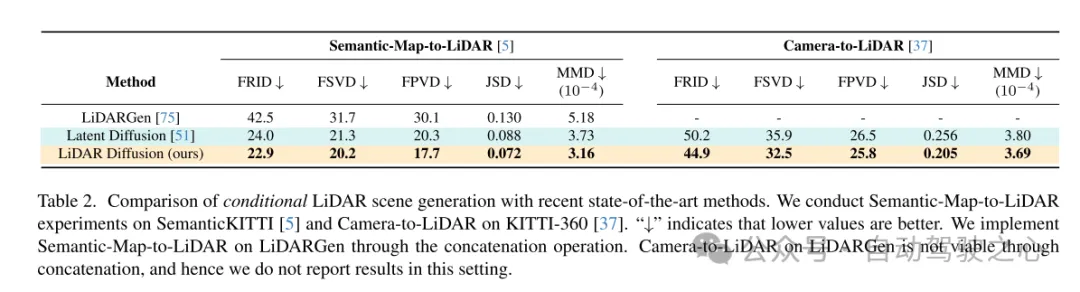
図 5. SemanticKITTI [5] データセットでのセマンティック マップからライダーへの生成のためのこの記事の LiDM の例。
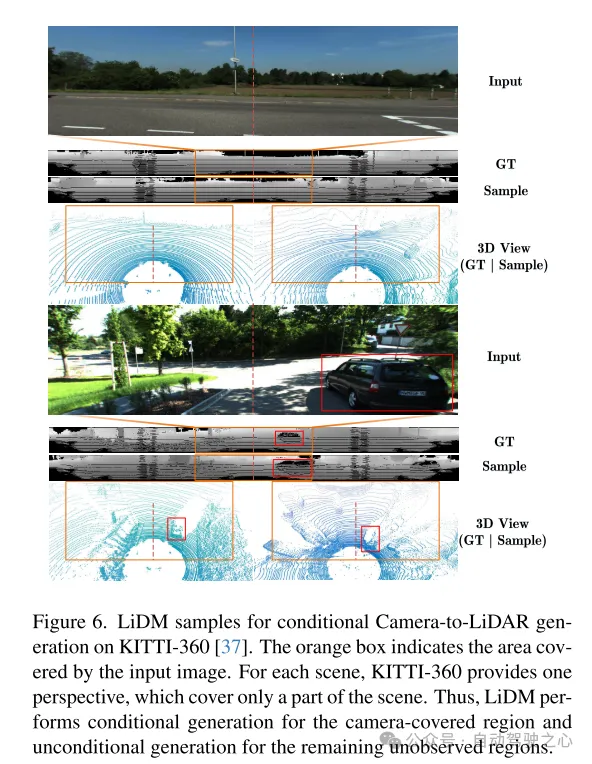
図 6. KITTI-360 [37] データセットでの条件付きカメラからライダーへの生成のための LiDM の例。オレンジ色のボックスは、入力画像によってカバーされる領域を示します。 KITTI-360 は、シーンごとに、シーンの一部のみをカバーする視点を提供します。したがって、LiDM は、カメラでカバーされる領域に対して条件付き生成を実行し、残りの未観察領域に対して無条件生成を実行します。
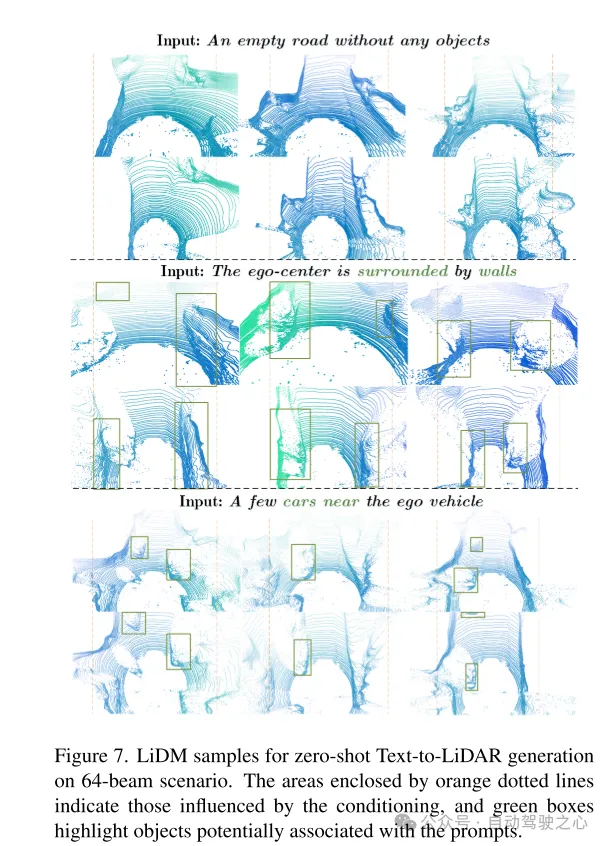
図 7. 64 ライン シナリオでのゼロショット テキストからライダーへの生成のための LiDM の例。オレンジ色の破線で囲まれた領域は条件の影響を受ける領域を表し、緑色のボックスはキュー ワードに関連付けられている可能性のあるオブジェクトを強調表示します。
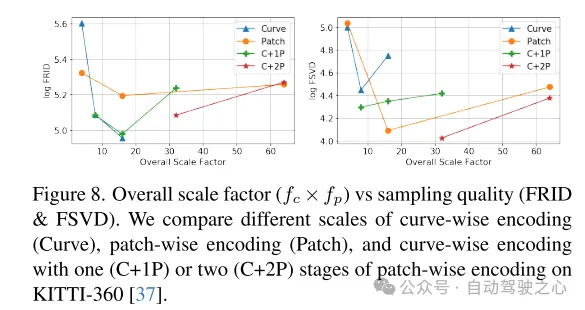
図 8. 全体的なスケーリング係数 ( ) とサンプリング品質 (FRID および FSVD) の関係。このペーパーでは、KITTI-360 のさまざまなスケールで、カーブ レベル コーディング (Curve)、ブロック レベル コーディング (Patch)、およびブロック レベル コーディングの 1 (C+1P) ステージまたは 2 (C+2P) ステージのカーブを比較します [ 37] レベルのエンコード。
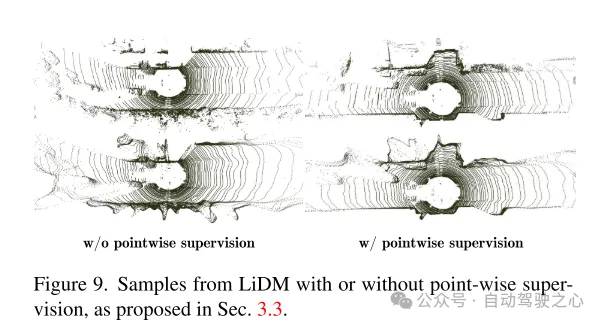
図 9. セクション 3.3 で提案されている、ポイントレベルの監視がある場合とない場合の LiDM の例。

概要:
このペーパーでは、LiDAR シーン生成のための一般的な条件付きフレームワークである LiDAR 拡散モデル (LiDM) を提案します。この記事の設計は、シーン レベルとオブジェクト レベルの曲線パターンと幾何学的構造を保持することに重点を置き、拡散モデルの効率的な潜在空間を設計して、現実的な LIDAR の生成を実現します。この設計により、この論文の LiDM は 64 ライン シナリオでの無条件生成で競争力のあるパフォーマンスを達成し、セマンティック マップを含むさまざまな条件を使用して条件付き生成で最先端のレベルに達することができます。 、カメラビューとテキストプロンプト。私たちの知る限り、私たちの方法は LIDAR 生成に条件を導入することに成功した最初のものです。
引用:
@inproceedings{ran2024towards,
title={LiDAR 拡散モデルによるリアルなシーン生成に向けて},
author={Ran、Haoxi と Guizilini、Vitor と Wang、Yue}、
booktitle={Proceedingsコンピューター ビジョンとパターン認識に関する IEEE/CVF 会議の
以上がCVPR 2024 | フォトリアルなシーン生成のための LiDAR 拡散モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7505
7505
 15
1378
52
78
11
19
55
15
1378
52
78
11
19
55

 H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトを実行するには、次の手順が必要です。Webサーバー、node.js、開発ツールなどの必要なツールのインストール。開発環境の構築、プロジェクトフォルダーの作成、プロジェクトの初期化、コードの書き込み。開発サーバーを起動し、コマンドラインを使用してコマンドを実行します。ブラウザでプロジェクトをプレビューし、開発サーバーURLを入力します。プロジェクトの公開、コードの最適化、プロジェクトの展開、Webサーバーの構成のセットアップ。
 Beego ormのモデルに関連付けられているデータベースを指定する方法は?
Apr 02, 2025 pm 03:54 PM
Beego ormのモデルに関連付けられているデータベースを指定する方法は?
Apr 02, 2025 pm 03:54 PM
Beegoormフレームワークでは、モデルに関連付けられているデータベースを指定する方法は?多くのBEEGOプロジェクトでは、複数のデータベースを同時に操作する必要があります。 Beegoを使用する場合...
 Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
GiteEpages静的Webサイトの展開が失敗しました:404エラーのトラブルシューティングと解像度Giteeを使用する
 GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
大企業または有名なオープンソースプロジェクトによって開発されたGOのどのライブラリが開発されていますか? GOでプログラミングするとき、開発者はしばしばいくつかの一般的なニーズに遭遇します...
 Redisストリームを使用してGO言語でメッセージキューを実装する場合、user_idタイプの変換の問題を解決する方法は?
Apr 02, 2025 pm 04:54 PM
Redisストリームを使用してGO言語でメッセージキューを実装する場合、user_idタイプの変換の問題を解決する方法は?
Apr 02, 2025 pm 04:54 PM
redisstreamを使用してGo言語でメッセージキューを実装する問題は、GO言語とRedisを使用することです...
 H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページは、コードの脆弱性、ブラウザー互換性、パフォーマンスの最適化、セキュリティの更新、ユーザーエクスペリエンスの改善などの要因のため、継続的に維持する必要があります。効果的なメンテナンス方法には、完全なテストシステムの確立、バージョン制御ツールの使用、定期的にページのパフォーマンスの監視、ユーザーフィードバックの収集、メンテナンス計画の策定が含まれます。
 XMLをExcelに変換する方法
Apr 03, 2025 am 08:54 AM
XMLをExcelに変換する方法
Apr 03, 2025 am 08:54 AM
XMLをExcelに変換するには、組み込みのExcel機能またはサードパーティツールを使用する方法は2つあります。サードパーティツールには、XML To Excel Converter、XML2Excel、XML Candyが含まれます。
 GOプログラミングでは、MySQLとRedisの間で接続を正しく管理し、リソースをリリースする方法は?
Apr 02, 2025 pm 05:03 PM
GOプログラミングでは、MySQLとRedisの間で接続を正しく管理し、リソースをリリースする方法は?
Apr 02, 2025 pm 05:03 PM
GOプログラミングのリソース管理:MySQLとRedisは、特にデータベースとキャッシュを使用して、リソースを正しく管理する方法を学習するために接続およびリリースします...
