

Llama3 のトレーニング コストがわずか 1/17 の Snowflake オープンソース 128x3B MoE モデル

Snowflake が LLM の乱闘に参加します。
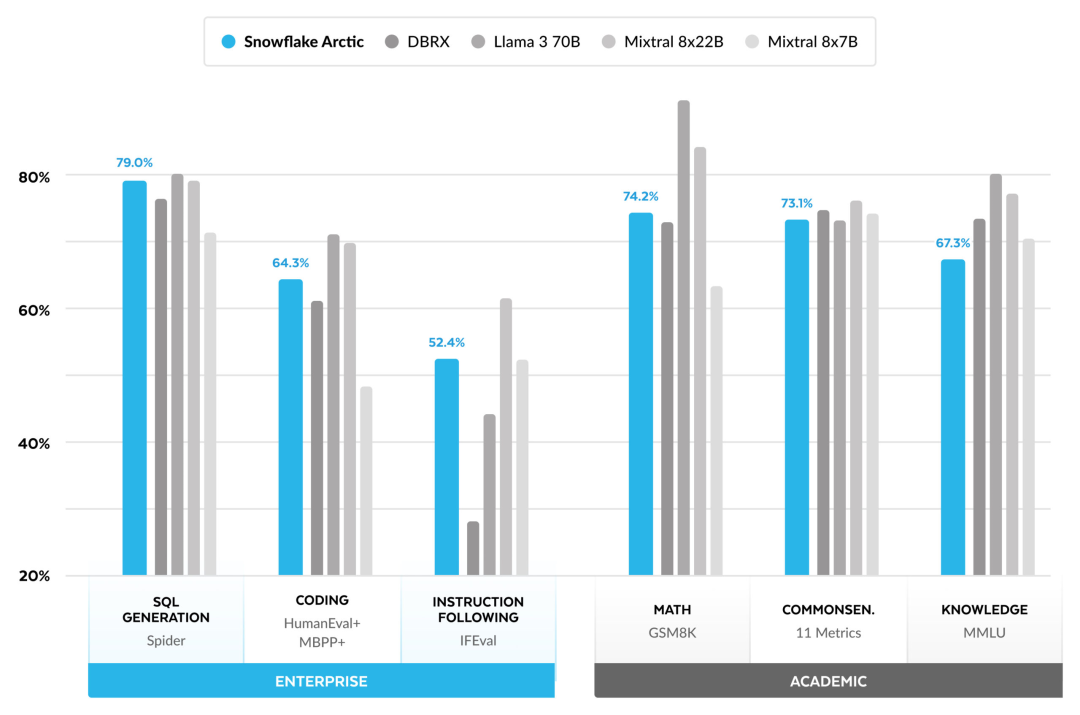
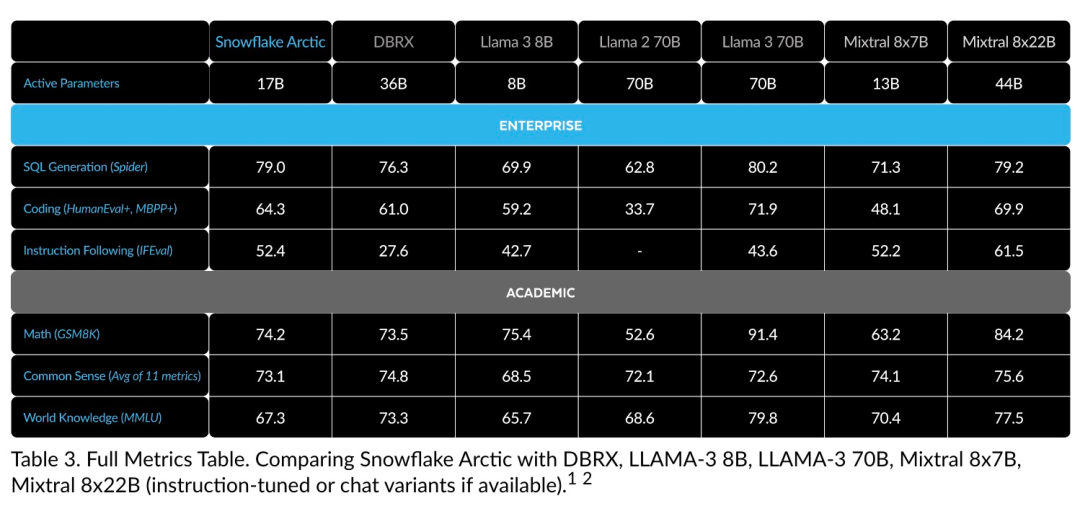
効率的なインテリジェンス: Arctic は、SQL 生成、プログラミング、命令追従などのエンタープライズ タスクに優れており、より高い計算コストでトレーニングされたオープン ソース モデルとさえ競合します。 Arctic は、費用対効果の高いトレーニングのための新しいベースラインを設定し、Snowflake の顧客が企業のニーズに合わせた高品質のカスタム モデルを低コストで作成できるようにします。 オープンソース: Arctic は Apache 2.0 ライセンスを採用し、重みとコードへのオープン アクセスを提供します。また、Snowflake もすべてのデータ ソリューションと研究結果をオープンソースにします。
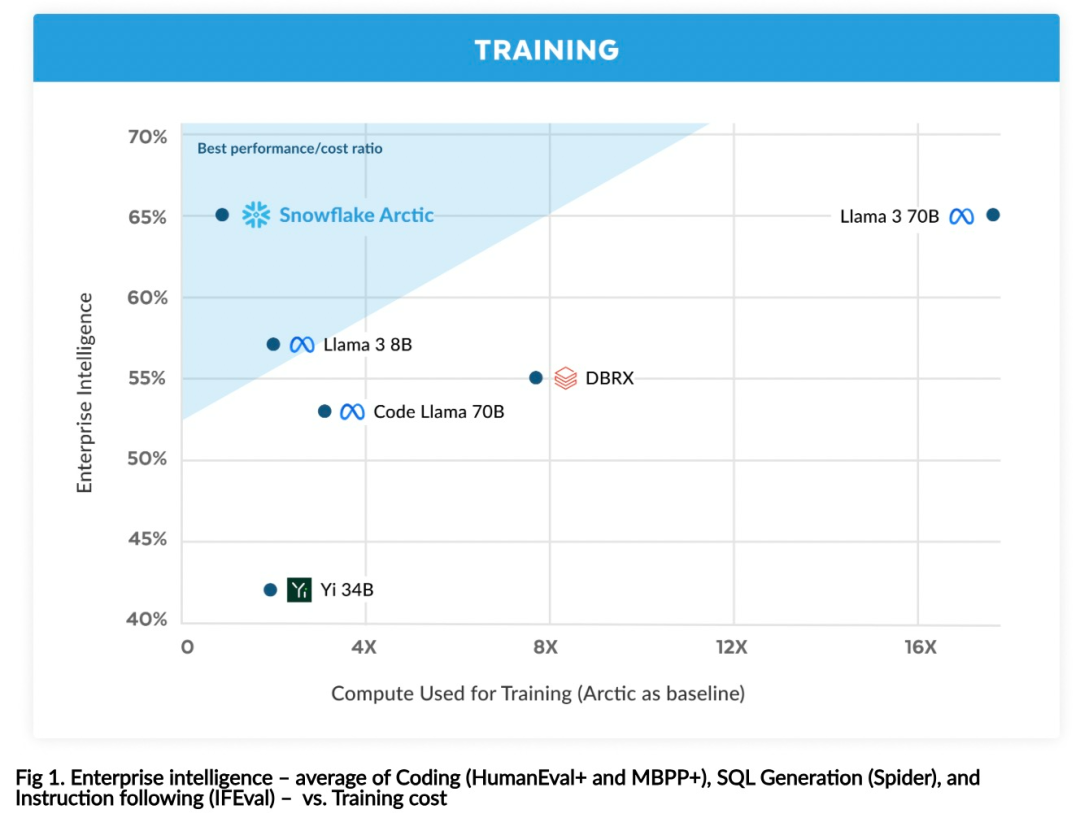
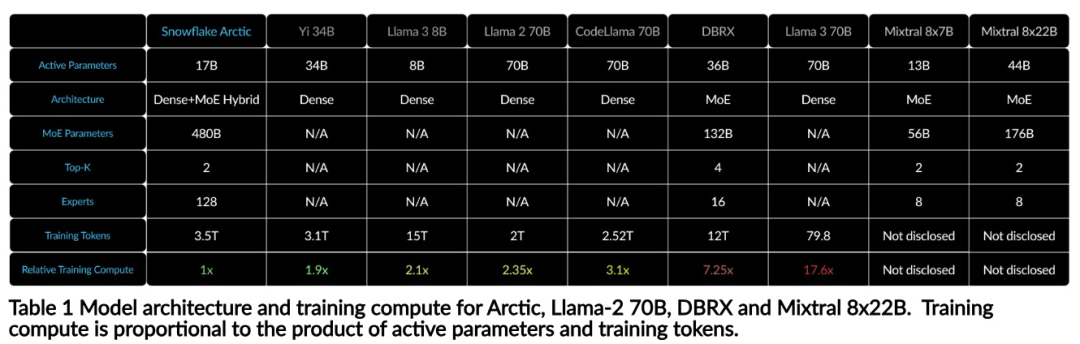
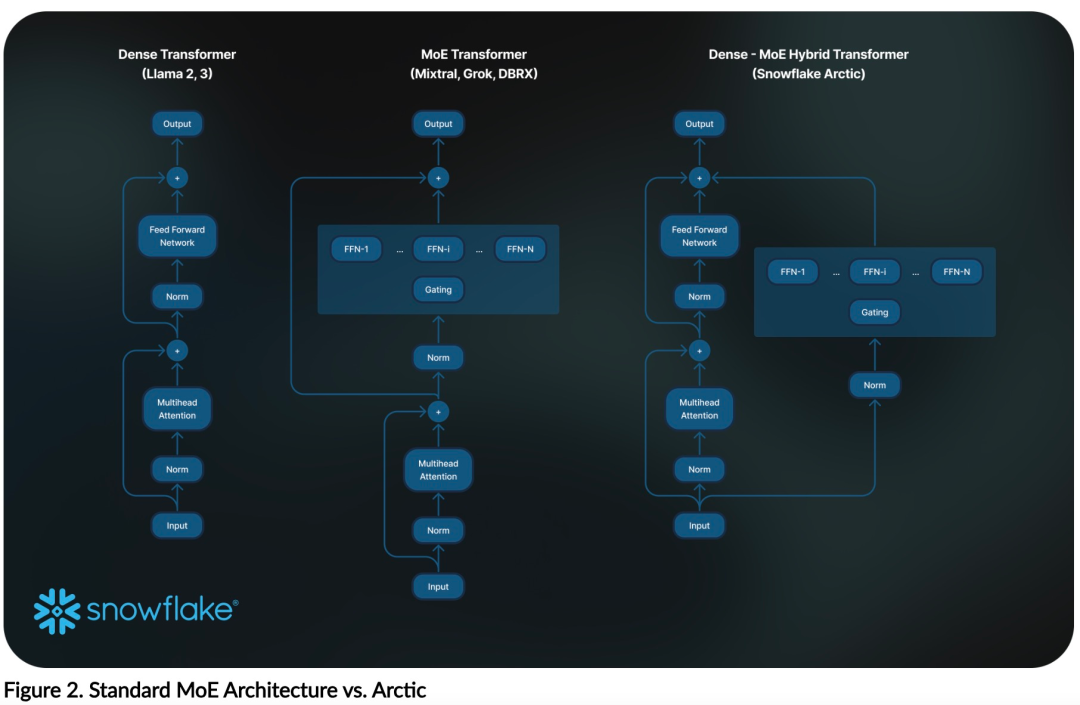
上記のトレーニング効率を達成するために、Arctic は独自の Dense-MoE ハイブリッド変圧器アーキテクチャを使用しています。これは、10B の高密度トランス モデルと 128×3.66B の残留 MoE MLP を組み合わせ、合計 480B のパラメータと 17B のアクティブ パラメータを備え、選択にトップ 2 ゲートを使用します。
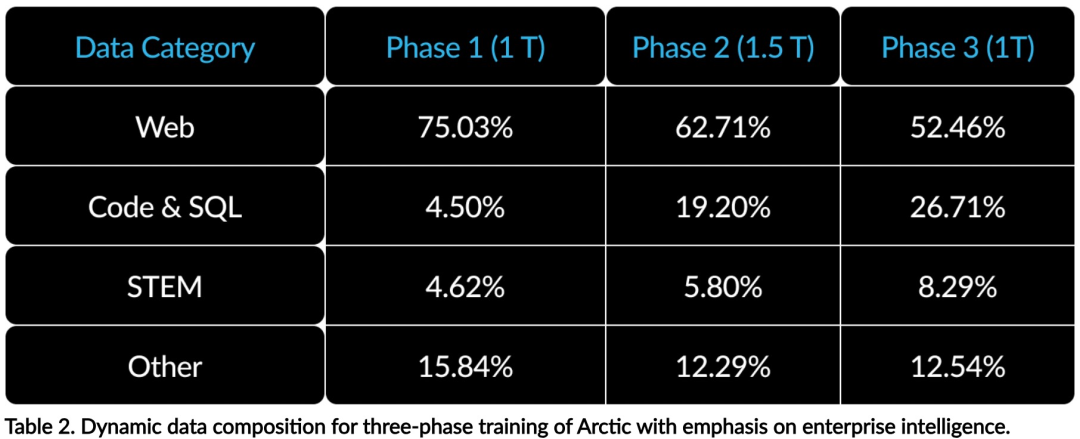
#これは、簡単なものから難しいものまで徐々に能力を身につけていく、人間の人生教育にたとえることができます。そのため、Arctic では 3 段階のカリキュラムを採用しており、各段階でデータ構成が異なり、最初の段階では一般スキル (1T トークン) に重点を置き、最後の 2 段階ではエンタープライズ スキル (1.5T および 1T トークン) に重点を置いています。
 #推論効率
#推論効率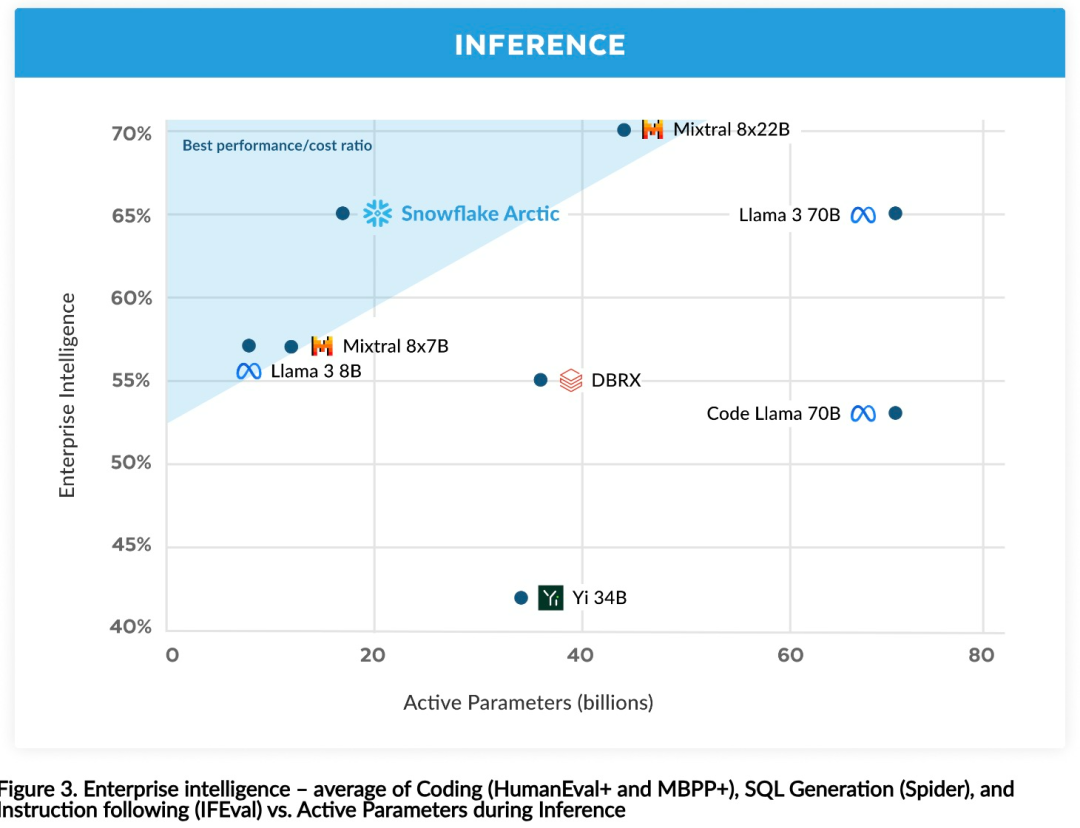
以上がLlama3 のトレーニング コストがわずか 1/17 の Snowflake オープンソース 128x3B MoE モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1384
52
83
11
28
96
15
1384
52
83
11
28
96

 ApacheでCGIディレクトリを設定する方法
Apr 13, 2025 pm 01:18 PM
ApacheでCGIディレクトリを設定する方法
Apr 13, 2025 pm 01:18 PM
ApacheでCGIディレクトリを設定するには、次の手順を実行する必要があります。「CGI-Bin」などのCGIディレクトリを作成し、Apacheの書き込み許可を付与します。 Apache構成ファイルに「Scriptalias」ディレクティブブロックを追加して、CGIディレクトリを「/cgi-bin」URLにマッピングします。 Apacheを再起動します。
 Apacheを始める方法
Apr 13, 2025 pm 01:06 PM
Apacheを始める方法
Apr 13, 2025 pm 01:06 PM
Apacheを開始する手順は次のとおりです。Apache(コマンド:sudo apt-get install apache2または公式Webサイトからダウンロード)をインストールします(linux:linux:sudo systemctl start apache2; windows:apache2.4 "serviceを右クリックして「開始」を右クリック) (オプション、Linux:Sudo SystemCtl
 Debian OpenSSL構成を確認する方法
Apr 12, 2025 pm 11:57 PM
Debian OpenSSL構成を確認する方法
Apr 12, 2025 pm 11:57 PM
この記事では、DebianシステムのOpenSSL構成を確認して、システムのセキュリティステータスをすばやく把握できるように、いくつかの方法を紹介します。 1.最初にOpenSSLバージョンを確認し、OpenSSLがインストールされているかどうかを確認し、バージョン情報を確認します。端末に次のコマンドを入力します。OpenSSlversionがインストールされていない場合、システムはエラーを促します。 2。構成ファイルを表示します。 OpenSSLのメイン構成ファイルは、通常/etc/ssl/openssl.cnfにあります。テキストエディター(Nanoなど)を使用して、次のように表示できます。sudonano/etc/ssl/openssl.cnfこのファイルには、キー、証明書、暗号化アルゴリズムなどの重要な構成情報が含まれています。 3。OPEを利用します
 Debian Apacheログを使用してWebサイトのパフォーマンスを向上させる方法
Apr 12, 2025 pm 11:36 PM
Debian Apacheログを使用してWebサイトのパフォーマンスを向上させる方法
Apr 12, 2025 pm 11:36 PM
この記事では、Debianシステムの下でApacheログを分析することにより、Webサイトのパフォーマンスを改善する方法について説明します。 1.ログ分析の基本Apacheログは、IPアドレス、タイムスタンプ、リクエストURL、HTTPメソッド、応答コードなど、すべてのHTTP要求の詳細情報を記録します。 Debian Systemsでは、これらのログは通常、/var/log/apache2/access.logおよび/var/log/apache2/error.logディレクトリにあります。ログ構造を理解することは、効果的な分析の最初のステップです。 2。ログ分析ツールさまざまなツールを使用してApacheログを分析できます。コマンドラインツール:GREP、AWK、SED、およびその他のコマンドラインツール。
 Apacheのサーバー名以上の削除方法
Apr 13, 2025 pm 01:09 PM
Apacheのサーバー名以上の削除方法
Apr 13, 2025 pm 01:09 PM
Apacheから追加のservernameディレクティブを削除するには、次の手順を実行できます。追加のservernameディレクティブを識別して削除します。 Apacheを再起動して変更を有効にします。構成ファイルを確認して、変更を確認します。サーバーをテストして、問題が解決されていることを確認します。
 Apacheバージョンを表示する方法
Apr 13, 2025 pm 01:15 PM
Apacheバージョンを表示する方法
Apr 13, 2025 pm 01:15 PM
Apacheサーバーでバージョンを表示するには3つの方法があります。コマンドライン(Apachectl -vまたはapache2ctl -v)を介して、サーバーステータスページ(http://< server ipまたはdomain name>/server -status)を確認します。
 CentOS HDFS構成を最適化する方法
Apr 14, 2025 pm 07:15 PM
CentOS HDFS構成を最適化する方法
Apr 14, 2025 pm 07:15 PM
CENTOSのHDFSパフォーマンスの向上:CENTOSのHDFS(Hadoop分散ファイルシステム)を最適化するための包括的な最適化ガイドには、ハードウェア、システム構成、ネットワーク設定を包括的に検討する必要があります。この記事では、HDFSパフォーマンスを改善するのに役立つ一連の最適化戦略を提供します。 1.ハードウェアのアップグレードと選択リソースの拡張:サーバーのCPU、メモリ、ストレージ容量を可能な限り増やします。高性能ハードウェア:高性能ネットワークカードとスイッチを採用して、ネットワークスループットを改善します。 2。システム構成微調整カーネルパラメーター調整:/etc/sysctl.confファイルを変更して、TCP接続番号、ファイルハンドル番号、メモリ管理などのカーネルパラメーターを最適化します。たとえば、TCP接続ステータスとバッファサイズを調整します
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
