

定量化、枝刈り、蒸留、これらの大きなモデルのスラングは正確には何を言っているのでしょうか?

定量化、枝刈り、蒸留など、大きな言語モデルによく注意を払うと、これらの単語を目にすることになるでしょう。これらの単語が何をするのかを理解するのは難しいですが、これらの単語は特に重要です。この段階では大規模な言語モデルの開発に使用されます。この記事は、それらを知り、その原則を理解するのに役立ちます。
モデル圧縮
量子化、枝刈り、抽出は、実際には一般的なニューラル ネットワーク モデルの圧縮テクノロジであり、大規模な言語モデルに限定されるものではありません。
モデル圧縮の重要性
圧縮後、モデルファイルは小さくなり、使用されるハードディスク容量も小さくなり、メモリにロードまたは表示するときに使用されるキャッシュ容量も小さくなり、モデルの実行速度も小さくなる可能性があります。
圧縮により、モデルを使用するとコンピューティング リソースの消費が減り、モデルのアプリケーション シナリオ、特に携帯電話、組み込みデバイスなど、モデル サイズとコンピューティング効率がより重要視される場所を大幅に拡張できます。
圧縮とは何ですか?
圧縮されるのはモデルのパラメータです モデルのパラメータとは何ですか?
現在の機械学習ではニューラル ネットワーク モデルが使用されていると聞いたことがあるかもしれません。ニューラル ネットワーク モデルは人間の脳のニューラル ネットワークをシミュレートします。
ここに簡単な図を描きましたので、ご覧ください。簡単にするために、A1、A2、A3 の 3 つのニューロンのみを説明します。各ニューロンは他のニューロンから信号を受信し、他のニューロンに信号を送信します。
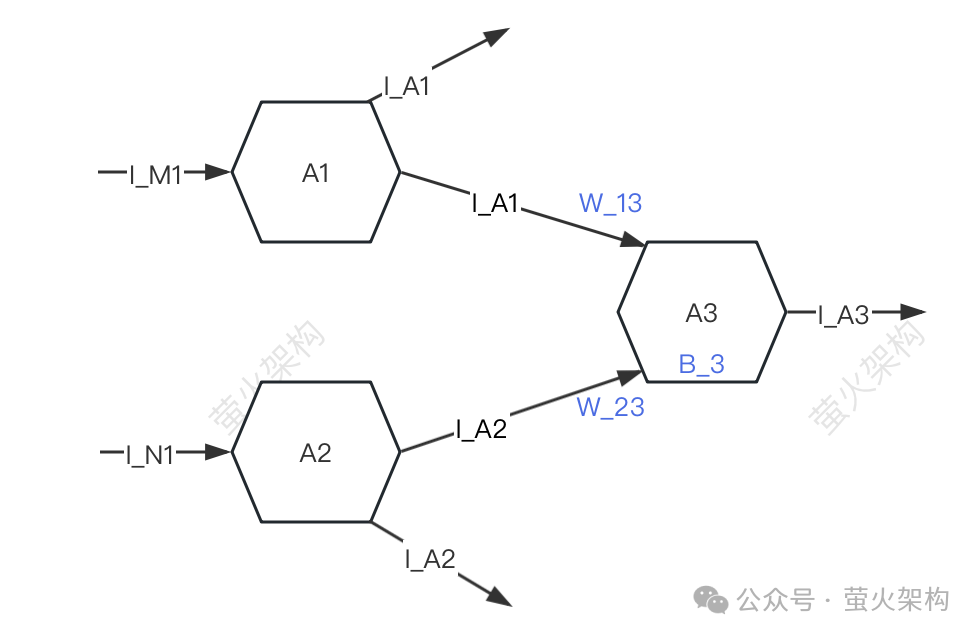 A3はA1とA2から信号I_A1とI_A2を受信しますが、A3がA1とA2から受信する信号の強度は異なります(この強度を「重み」と呼びます)。ここでの強度をW_13と仮定します。 W_23、A3 はそれぞれ受信信号データを処理します。
A3はA1とA2から信号I_A1とI_A2を受信しますが、A3がA1とA2から受信する信号の強度は異なります(この強度を「重み」と呼びます)。ここでの強度をW_13と仮定します。 W_23、A3 はそれぞれ受信信号データを処理します。
最初に信号の加重加算を実行します。つまり、I_A1*W_13+I_A2*W_23、
次に、A3 独自のパラメータ B_3 (「バイアス」と呼ばれます) を追加します。
- 最後に、このデータ特定の形式に変換され、変換された信号は次のニューロンに送信されます。
- この信号データを処理する過程で使用される重み (W_13、W_23) とオフセット (B_3) はモデルのパラメーターです。 もちろん、モデルには他のパラメーターもありますが、重みとオフセットは一般的に次のとおりです。 all パラメータの大部分は、80/20 原則を使用して分割した場合、80% を超える必要があります。
- 大規模な言語モデルを使用してテキストを生成する場合、これらのパラメーターは事前にトレーニングされており、変更することはできません。これは、未知の xyz を渡して出力結果を取得することしかできません。 。
モデル圧縮では、主に重みとバイアスを圧縮します。使用される具体的な方法は、この記事の焦点です。
量子化
量子化とは、モデルパラメータの数値精度を下げることです。例えば、最初に学習された重みは32ビット浮動小数点数ですが、実際に使用すると、ほとんど損失がないことがわかります。 16 ビットで表現されますが、モデル ファイルのサイズは半分に減り、ビデオ メモリの使用量も半分に減り、プロセッサとメモリ間の通信帯域幅要件も減ります。これは、コストの削減と利点の向上を意味します。
レシピに従うのと同じで、各材料の重量を決定する必要があります。 0.01グラムまで正確な電子秤を使用すると、各食材の重さを非常に正確に知ることができるので便利です。ただし、持ち寄りの食事を作るだけで、実際にはそれほど高い精度が必要ない場合は、最小目盛りが 1 グラムのシンプルで安価な秤を使用できます。これはそれほど正確ではありませんが、おいしい食事を作るには十分です。夕食。
Pictures
量子化のもう 1 つの利点は、計算が高速になることです。最新のプロセッサには、通常、低精度のベクトル計算ユニットが多数含まれており、これらのハードウェア機能を最大限に活用して、より多くの並列演算を実行できます。同時に、低精度の演算は高精度の演算よりも高速です。 1 回の乗算と加算の消費時間が短くなります。これらの利点により、このモデルは、高性能 GPU を搭載していない通常のオフィスや家庭のコンピューター、携帯電話、その他のモバイル端末などの低構成のマシンでも実行できます。
この考えに従って、サイズが小さく、コンピューティング リソースの使用量が少ない 8 ビット、4 ビット、2 ビット モデルの圧縮が続けられています。ただし、重みの精度が低下すると、さまざまな重みの値が近づくか等しくなるため、モデル出力の精度と精度が低下し、モデルのパフォーマンスがさまざまな程度で低下します。
量子化テクノロジーには、動的量子化、静的量子化、対称量子化、非対称量子化など、さまざまな戦略と技術的詳細があります。大規模な言語モデルの場合、通常、モデルのトレーニングが完了した後、静的量子化戦略が使用されます。パラメーターは一度定量化されるため、モデルの実行時に定量的な計算が必要なくなるため、配布と展開が容易になります。
枝刈り
枝刈りは、モデル内の重要でない、またはめったに使用されない重みを削除することです。これらの重みの値は通常 0 に近くなります。一部のモデルでは、プルーニングにより高い圧縮率が得られ、モデルがよりコンパクトで効率的になります。これは、リソースに制約のあるデバイスにモデルを展開する場合、またはメモリとストレージが制限されている場合に特に役立ちます。
枝刈りにより、モデルの解釈可能性も向上します。不要なコンポーネントを削除することで、プルーニングによりモデルの基礎となる構造がより透明になり、分析が容易になります。これは、ニューラル ネットワークなどの複雑なモデルの意思決定プロセスを理解するために重要です。
次の図に示すように、枝刈りには重みパラメータの枝刈りだけでなく、特定のニューロン ノードの枝刈りも含まれます。モデル (ほとんどのパラメーターが 0 または 0 に近い) では、枝刈りは効果がない可能性があります。比較的少数のパラメーターを持つ一部の小規模なモデルでは、枝刈りによってモデルのパフォーマンスが大幅に低下する可能性があります。医療診断など死活問題となるモデルの枝刈りには向きません。
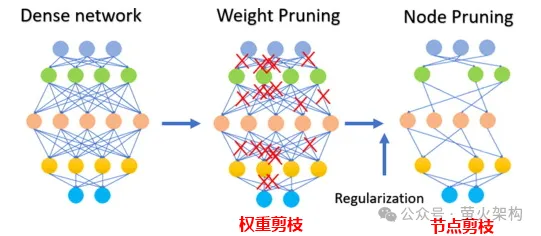 実際に枝刈り技術を適用する場合、通常、モデルの実行速度の向上と枝刈りによるモデルのパフォーマンスへの悪影響を総合的に考慮し、モデル内の各パラメータをスコアリングするなどのいくつかの戦略を採用する必要があります。パラメータの評価がモデルのパフォーマンスにどの程度寄与するか。スコアが高いものは削除してはいけない重要なパラメータであり、スコアが低いものはそれほど重要ではないため削除を検討してもよいパラメータです。このスコアは、パラメーターのサイズを確認する (通常、絶対値が大きいほど重要です) など、さまざまな方法で計算したり、より複雑な統計分析方法で決定したりできます。
実際に枝刈り技術を適用する場合、通常、モデルの実行速度の向上と枝刈りによるモデルのパフォーマンスへの悪影響を総合的に考慮し、モデル内の各パラメータをスコアリングするなどのいくつかの戦略を採用する必要があります。パラメータの評価がモデルのパフォーマンスにどの程度寄与するか。スコアが高いものは削除してはいけない重要なパラメータであり、スコアが低いものはそれほど重要ではないため削除を検討してもよいパラメータです。このスコアは、パラメーターのサイズを確認する (通常、絶対値が大きいほど重要です) など、さまざまな方法で計算したり、より複雑な統計分析方法で決定したりできます。
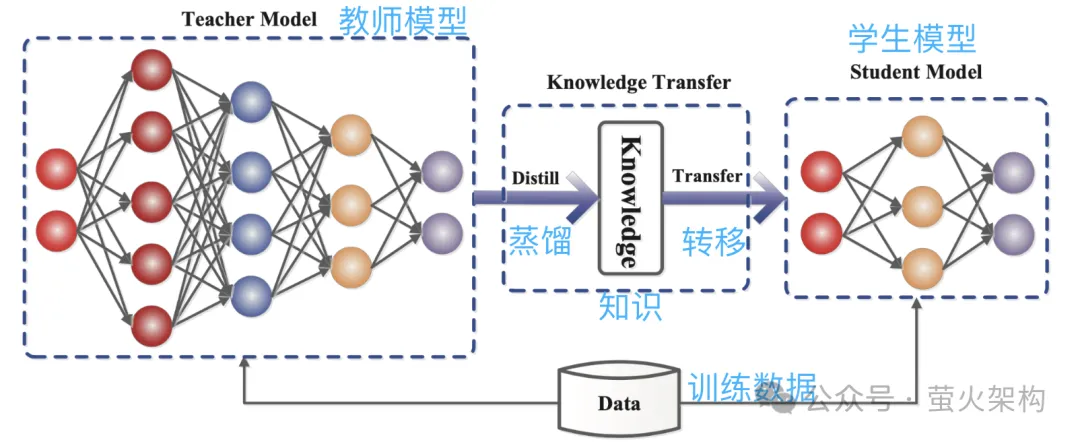
蒸留
蒸留とは、大規模モデルで学習した確率分布を小規模モデルに直接コピーすることです。コピーされたモデルは教師モデルと呼ばれ、一般に多数のパラメータと強力なパフォーマンスを備えた優れたモデルです。新しいモデルは学生モデルと呼ばれ、一般に比較的少ないパラメータを備えた小規模なモデルです。
蒸留中、教師モデルは入力に基づいて複数の可能な出力の確率分布を生成し、その後、生徒モデルはこの入力と出力の確率分布を学習します。広範なトレーニングの後、学生モデルは教師モデルの動作を模倣したり、教師モデルの知識を学習したりできます。
たとえば、画像分類タスクでは、画像が与えられた場合、教師モデルは次のような確率分布を出力する可能性があります:
Cat: 0.7
Dog: 0.4
- Car : 0.1
- 次に、この画像と出力確率分布情報を模倣学習用の学生モデルに送信します。
- 写真
蒸留により教師モデルの知識がより小さく単純な生徒モデルに圧縮されるため、新しいモデルでは一部の情報が失われる可能性があり、さらに、生徒モデルは教師モデルに依存しすぎる可能性があります。モデルの一般化能力が低下します。
 学生モデルの学習効果を高めるために、いくつかの方法と戦略を採用できます。
学生モデルの学習効果を高めるために、いくつかの方法と戦略を採用できます。
温度パラメータの紹介: 非常に早く教える教師がいて、情報密度が非常に高いと仮定します。生徒はそれについていくのが少し難しいかもしれません。このとき、教師がスピードを落として簡潔に説明すると、生徒も理解しやすくなります。モデルの蒸留では、温度パラメータは「講義速度の調整」と同様の役割を果たし、学生モデル (小さなモデル) が教師モデル (大きなモデル) の知識をよりよく理解して学習できるようにします。専門的に言えば、モデルの出力をより滑らかな確率分布にし、学生モデルが教師モデルの出力の詳細を取得して学習しやすくすることです。
教師モデルと生徒モデルの構造を調整します: 専門家間の知識の差が大きすぎて、直接学習しても理解できない可能性があるため、生徒が専門家から何かを学ぶのは難しいかもしれません。専門家の言葉を理解し、それを生徒が理解できる言語に翻訳できる教師を真ん中に加えます。中間に追加される教師は、いくつかの中間層または補助ニューラル ネットワークである場合があります。あるいは、教師は、教師モデルの出力とよりよく一致するように生徒モデルに調整を加えることができます。
上で 3 つの主要なモデル圧縮テクノロジーを紹介しましたが、実際にはまだ詳細がたくさんありますが、原理を理解するにはこれでほぼ十分です。低ランク分解など、他のモデル圧縮テクノロジーもあります。パラメータの共有、スパース接続など。興味のある学生は、さらに関連するコンテンツを確認できます。
さらに、モデルが圧縮された後は、そのパフォーマンスが大幅に低下する可能性があります。現時点では、特に医療診断や財務リスクなど、モデルの高い精度が必要なタスクの場合は、モデルを微調整することができます。制御や自動運転などを微調整することで、モデルの性能をある程度回復させ、ある面では精度や精度を安定させることができます。
モデルの微調整について言えば、最近 AutoDL で Text Generation WebUI の画像を共有しました。 Text Generation WebUI は、大規模な言語モデルの推論と微調整を簡単に実行できる、Gradio を使用して書かれた Web プログラムです。 Transformers、llama.cpp (GGUF)、GPTQ、AWQ、EXL2、その他のさまざまな形式のモデルを含む、さまざまなタイプの大規模言語モデル。最新のイメージには、Meta によって最近オープンソース化された Llama3 大型モデルが組み込まれています。興味のある学生は試してみて、使い方を確認してください: 10 分で大規模な言語モデルを微調整する方法を学びましょう
 写真
写真
参考記事:
https:/ /www.php.cn/link/d7852cd2408d9d3205dc75b59 a6ce22e
https://www.php.cn/link/f204aab71691a8e18c3f6f00872db63b
https://www.php.cn/link/b31f0c758bb498b5d56b5fea80 f313a7
https://www.php.cn/link/129ccfc1c1a82b0b23d4473a72373a0a
以上が定量化、枝刈り、蒸留、これらの大きなモデルのスラングは正確には何を言っているのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7526
7526
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 Meitu Xiu Xiu の元の画質を維持する方法
Apr 09, 2024 am 08:34 AM
Meitu Xiu Xiu の元の画質を維持する方法
Apr 09, 2024 am 08:34 AM
多くの友人は Meituan Xiuxiu ソフトウェアを使用して P ピクチャを作成していますが、P ピクチャ後に保存するときに画像の元の品質を維持するにはどうすればよいですか?以下に操作方法を載せておきますので、興味のある方は一緒に見てみてください。携帯電話で Meitu Xiu Xiu APP を開いた後、ページの右下隅にある「Me」をクリックしてに入り、マイ ページの右上隅にある六角形のアイコンをクリックして開きます。 2. 設定ページに移動したら、「一般」を見つけて、この項目をクリックして入力します。 3. 次に、一般ページに「画質」があるので、その後ろにある矢印をクリックして設定に入ります。 4. 最後に、画質設定画面に入ると、下部に水平線が表示されますので、水平線上の円形スライダーをクリックし、右にドラッグして 100 まで設定します。オリジナルの画質。
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 cURL と wget: どちらが適していますか?
May 07, 2024 am 09:04 AM
cURL と wget: どちらが適していますか?
May 07, 2024 am 09:04 AM
Linux コマンド ラインから直接ファイルをダウンロードしたい場合、wget と cURL という 2 つのツールがすぐに思い浮かびます。これらは多くの同じ特性を持ち、同じタスクの一部を簡単に実行できますが、いくつかの類似した特性がありますが、まったく同じではありません。これら 2 つのプログラムはさまざまな状況に適しており、特定の状況では独自の特徴があります。 cURL と wget: 類似点 wget と cURL はどちらもコンテンツをダウンロードできます。これが、核となる部分がどのように設計されているかです。インターネットにリクエストを送信したり、リクエストされたアイテムを返したりすることができます。これは、ファイル、画像、または Web サイトの生の HTML などの何かです。どちらのプログラムも HTTPPOST リクエストを行うことができます。これは、全員が送信できることを意味します
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
 テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボットは工場で働く、マスク氏:手の自由度は今年22に達する!
May 06, 2024 pm 04:13 PM
テスラのロボット「オプティマス」の最新映像が公開され、すでに工場内で稼働可能となっている。通常の速度では、バッテリー(テスラの4680バッテリー)を次のように分類します:公式は、20倍の速度でどのように見えるかも公開しました - 小さな「ワークステーション」上で、ピッキング、ピッキング、ピッキング:今回は、それがリリースされたハイライトの1つビデオの内容は、オプティマスが工場内でこの作業を完全に自律的に行い、プロセス全体を通じて人間の介入なしに完了するというものです。そして、オプティマスの観点から見ると、自動エラー修正に重点を置いて、曲がったバッテリーを拾い上げたり配置したりすることもできます。オプティマスのハンドについては、NVIDIA の科学者ジム ファン氏が高く評価しました。オプティマスのハンドは、世界の 5 本指ロボットの 1 つです。最も器用。その手は触覚だけではありません
