

Llama 3 の低ビット量子化パフォーマンスは大幅に低下します。総合的な評価結果はこちら | HKU & Beihang University & ETH

大規模モデルの力により、LLaMA3 は新たな高みに到達します:
超大規模な事前トレーニングを経た 15T トークン データで、素晴らしいパフォーマンスの向上が達成されました。 Chinchilla の推奨をはるかに超えていたため、オープンソース コミュニティでの議論が行われませんでした。
同時に、実用的なアプリケーション レベルでは、別のホットなトピックも浮上しています。
リソースが限られたシナリオでは、LLaMA3 の定量的なパフォーマンス改善されましたどうなるでしょうか?
香港大学、北杭大学、チューリッヒ連邦工科大学は共同で、LLaMA3 の低ビット量子化機能を包括的に明らかにする実証研究を開始しました。

研究者らは、既存の 10 種類のトレーニング後の量子化 LoRA 微調整手法を使用して、1 ~ 8 ビットの LLaMA3 の結果とさまざまな評価データセットを評価しました。彼らは次のことを発見しました:
LLaMA3 は、優れたパフォーマンスにもかかわらず、低ビット量子化、特に超低ビット幅で依然として無視できない劣化に悩まされています。

このプロジェクトは GitHub でオープンソース化されており、定量モデルも HuggingFace で公開されています。
具体的に実証結果を見てみましょう。
トラック 1: トレーニング後の量子化
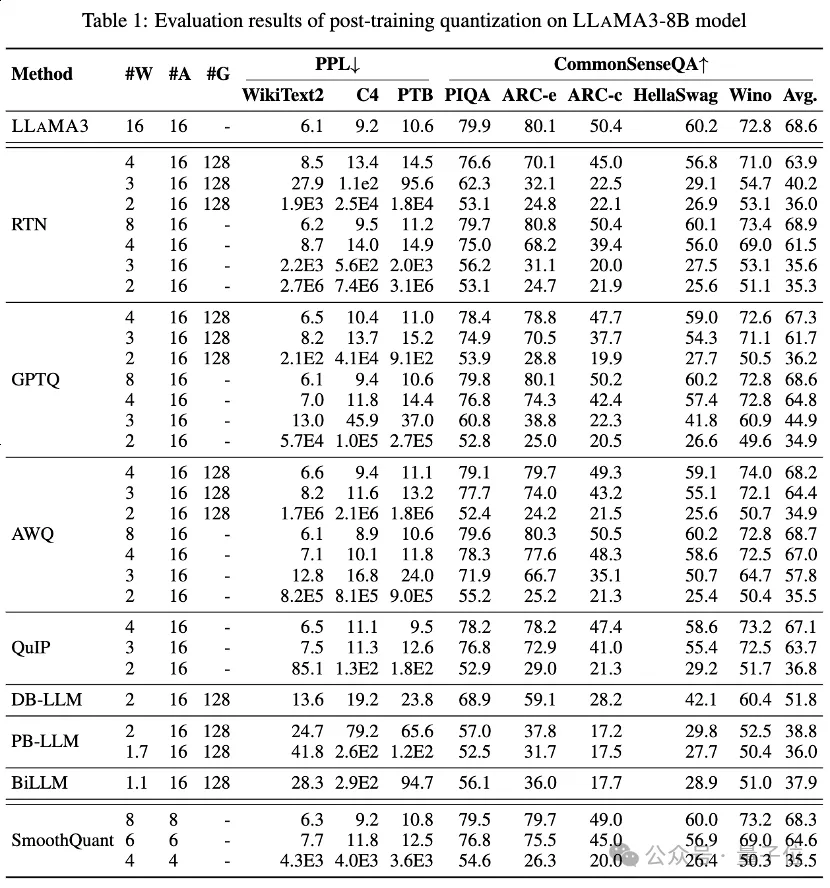
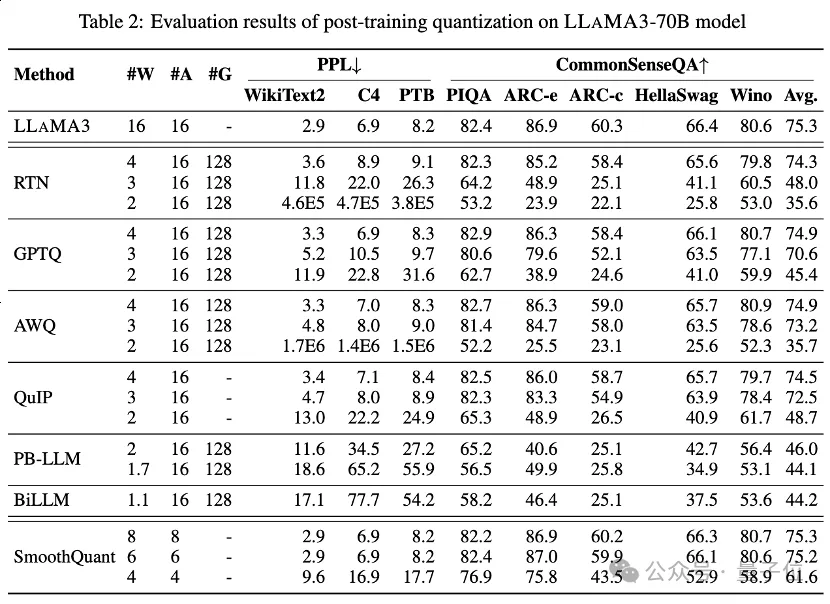
表 1 と表 2 は、1 からの広ビット幅をカバーする、8 つの異なる PTQ メソッドにおける LLaMA3-8B と LLaMA3-70B の低ビット パフォーマンスを示しています。ビットから 8 ビットまで。
1. 低ビット特権の重み
このうち、Round-To-Nearest (RTN) は基本的な丸め量子化手法です。
GPTQ は、現在利用可能な最も効率的かつ効果的な重みのみの量子化手法の 1 つであり、量子化における誤差補償を利用します。しかし、2 ~ 3 ビットでは、GPTQ は LLaMA3 を量子化するときに深刻な精度の低下を引き起こします。
AWQ は異常チャネル抑制手法を使用して重みの定量化の困難さを軽減しますが、QuIP は行列計算を最適化することで重みとヘシアン間の不一致を保証します。これらはすべて、LLaMA3 の機能を 3 ビットで維持し、2 ビット量子化を有望なレベルまで押し上げます。
2. 超低ビット幅 LLM 重み圧縮
最近登場したバイナリ LLM 量子化方式は、超低ビット幅 LLM 重み圧縮を実現します。
PB-LLM は混合精度量子化戦略を採用し、重要な重みの一部の完全な精度を維持しながら、重みの大部分を 1 ビットに量子化します。
DB-LLM は、デュアル 2 値化重み分割を通じて効率的な LLM 圧縮を実現し、2 ビット LLM のパフォーマンスをさらに強化するためのバイアスを意識した蒸留戦略を提案します。
BiLLM は、有意な重みの残差近似と非有意な重みのグループ量子化を通じて、LLM 量子化境界を 1.1 ビットまでさらに押し下げます。超低ビット幅向けに特別に設計されたこれらの LLM 量子化方式は、GPTQ、AWQ、QuIP などの 2 ビット (場合によっては 3 ビット) の方式をはるかに上回る ⩽2 ビットで、より高精度の量子化 LLaMA3-8B を実現できます。
3. 低ビット量子化アクティベーション
は、量子化難易度をアクティベーションから重み、スムーズ アクティベーション外れ値に変換する SmoothQuant を介して量子化アクティベーションに対して LLaMA3 評価も実行しました。評価の結果、SmoothQuant は 8 ビットおよび 6 ビットの重みとアクティベーションで LLaMA3 の精度を維持できるが、4 ビットでは面が崩壊することがわかりました。
トラック 2: LoRA の微調整された量子化
MMLU データセット上で、LoRA-FT 量子化下の LLaMA3-8B では、最も印象的な観察は、Alpaca データセットに対する低ランクの微調整では、量子化によって生じた誤差を補償できないだけでなく、パフォーマンスの低下をより深刻にしていることです。
具体的には、4 ビットでのさまざまな LoRA-FT 量子化方法によって得られる量子化 LLaMA3 のパフォーマンスは、LoRA-FT を使用しない対応する 4 ビットのバージョンよりも劣ります。これは、LLaMA1 および LLaMA2 での同様の現象とは大きく対照的です。LLaMA1 および LLaMA2 では、4 ビットの低ランク微調整量子化バージョンが、MMLU 上の元の FP16 対応バージョンよりも簡単に性能を上回ります。
直観的な分析によると、この現象の主な理由は、LLaMA3 の強力なパフォーマンスが大規模な事前トレーニングの恩恵を受けていることです。つまり、元のモデルの量子化後のパフォーマンス損失を引き継ぐことができないことです。低ランクの微調整の一部がパラメーター データに対して実行され、補正されます (これは元のモデルのサブセットと考えることができます)。
量子化によって引き起こされる大幅な劣化は微調整によって補償することはできませんが、4 ビット LoRA-FT 量子化 LLaMA3-8B は、さまざまな量子化方法の下で LLaMA1-7B および LLaMA2-7B を大幅に上回ります。たとえば、QLoRA メソッドを使用すると、4 ビット LLaMA3-8B の平均精度は 57.0 (FP16: 64.8) となり、4 ビット LLaMA1-7B (FP16: 34.6) の 38.4 を 18.6 上回り、4 ビット LLaMA1-7B の 43.9 を上回ります。 4 ビット LLaMA2-7B (FP16: 45.5) 13.1。これは、LLaMA3 時代における新しい LoRA-FT 量子化パラダイムの必要性を示しています。
同様の現象が CommonSenseQA ベンチマークでも発生しました。 QLoRA および IR-QLoRA で微調整されたモデルのパフォーマンスも、LoRA-FT を使用しない 4 ビットのモデルと比較して低下しました (例: QLoRA では平均 2.8% の低下、IR-QLoRA では平均 2.4% の低下)。これは、LLaMA3 で高品質のデータセットを使用する利点と、汎用データセット Alpaca が他のタスクのモデルのパフォーマンスに寄与しないことをさらに示しています。
結論
この論文では、さまざまな低ビット量子化技術 (トレーニング後の量子化と LoRA 微調整量子化を含む) における LLaMA3 のパフォーマンスを包括的に評価します。
この調査結果は、LLaMA3 が量子化後も依然として優れたパフォーマンスを示しているものの、量子化に伴うパフォーマンスの低下が著しく、多くの場合さらに大きなパフォーマンスの低下につながる可能性があることを示しています。
この発見は、リソースに制約のある環境で LLaMA3 を導入する際に直面する可能性のある潜在的な課題を浮き彫りにし、低ビット量子化のコンテキストにおいて成長と改善の余地が十分にあることを浮き彫りにしています。低ビット量子化によって引き起こされるパフォーマンス低下を解決することで、その後の量子化パラダイムにより、LLM がより低い計算コストでより強力な機能を達成できるようになり、最終的には代表的な生成人工知能を新たな高みに押し上げることが期待されています。
論文リンク: https://arxiv.org/abs/2404.14047。
プロジェクト リンク: https://github.com/Macaronlin/LLaMA3-Quantizationhttps://huggingface.co/LLMQ。
以上がLlama 3 の低ビット量子化パフォーマンスは大幅に低下します。総合的な評価結果はこちら | HKU & Beihang University & ETHの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 SFTを大幅に超えて、O1/DeepSeek-R1の背後にある秘密は、マルチモーダルの大規模モデルでも使用できます
Mar 12, 2025 pm 01:03 PM
SFTを大幅に超えて、O1/DeepSeek-R1の背後にある秘密は、マルチモーダルの大規模モデルでも使用できます
Mar 12, 2025 pm 01:03 PM
上海ジョトン大学、上海アイラブ、および香港中国大学の研究者は、Visual Language Big Model(LVLM)のパフォーマンスを大幅に改善するために少量のデータのみを必要とする視覚RFT(視覚エンハンスメントファインチューニング)オープンソースプロジェクトを開始しました。 Visual-RFTは、DeepSeek-R1のルールベースの強化学習アプローチとOpenAIの強化微調整(RFT)パラダイムを巧みに組み合わせて、このアプローチをテキストフィールドから視野に拡張しました。視覚的サブカテゴリ化やオブジェクト検出などのタスクの対応するルール報酬を設計することにより、Visual-RFTは、テキスト、数学的推論、その他のフィールドに限定されているDeepSeek-R1メソッドの制限を克服し、LVLMトレーニングの新しい方法を提供します。 Vis

 GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
大企業または有名なオープンソースプロジェクトによって開発されたGOのどのライブラリが開発されていますか? GOでプログラミングするとき、開発者はしばしばいくつかの一般的なニーズに遭遇します...
 海外バージョンの配送地域データを取得する方法は?利用可能な既製のリソースは何ですか?
Apr 01, 2025 am 08:15 AM
海外バージョンの配送地域データを取得する方法は?利用可能な既製のリソースは何ですか?
Apr 01, 2025 am 08:15 AM
質問の説明:海外バージョンの配送地域データを取得する方法は?既製のリソースはありますか?国境を越えた電子商取引またはグローバル化ビジネスで正確に入手してください...
 Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
GiteEpages静的Webサイトの展開が失敗しました:404エラーのトラブルシューティングと解像度Giteeを使用する
 Binance LaunchPoolとは何ですか? Binance LaunchPoolに参加する方法は?
Mar 05, 2025 pm 03:06 PM
Binance LaunchPoolとは何ですか? Binance LaunchPoolに参加する方法は?
Mar 05, 2025 pm 03:06 PM
Binance LaunchPool詳細分析:高利回りの採掘ガイドとバイオプロジェクトの詳細な説明は、Binance LaunchPoolの詳細な議論を行い、その利回りを分析し、参加方法を詳細に説明し、最新のプロジェクトBio Coin(BIOL)の導入に焦点を当てます。世界最大の暗号通貨交換として、BinanceはLaunchPoolで高品質のプロジェクトを選択し、投資家に新しい鉱業と新しいトークンを取得する機会を提供しました。 Binance LaunchPoolとは何ですか? Binance LaunchPoolは、指定された通貨を誓約することで、新しいトークンを無料で獲得するプラットフォームです。これは、株式市場の新しい株式サブスクリプションに似ていますが、参加者は少なくなり、競争が少なくなり、少額の投資も高い収益を得ることができます。
 Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python:Hourglassグラフィック図面と入力検証この記事では、Python NoviceがHourglass Graphic Drawingプログラムで遭遇する可変定義の問題を解決します。コード...
 DeepseekはV3/R1の理論的な日々の収入をリリースします。利益率は545%
Mar 12, 2025 pm 02:18 PM
DeepseekはV3/R1の理論的な日々の収入をリリースします。利益率は545%
Mar 12, 2025 pm 02:18 PM
最近、人工知能推論システムDeepseekは、V3/R1推論システムの重要な秘密を包括的に明らかにする記事をリリースしました。この記事は、Deepseekの理論的コストや利益率などの重要な情報を初めて開示しました。報告によると、DeepSeekV3とR1のすべてのサービスはH800GPUを使用し、サービスの有効性を確保するためにトレーニングと同じ精度を採用しています。同時に、Deepseekは、ハードウェアの利用を最大化するために、昼夜のリソース割り当てを実現します。統計によると、GPUレンタルのコストが1時間あたり2米ドルであると仮定すると、1日のDeepSeekの総コストは87,072米ドルです。すべてのトークンがdeepseekr1の価格設定に従って計算されている場合、1日の理論的総収入は56,202です
