

現時点で最強の国産ソラ!清華チームは 16 秒のビデオを突破し、複数のレンズを使った言語を理解し、物理法則をシミュレートできる

ボックスにはダイヤモンドを詰める必要があるとおっしゃっていたので、ボックスにはダイヤモンドが詰め込まれており、実際のショットよりもさらにまばゆいばかりでした。そのようなスキルを好まない乗組員はいるでしょうか?
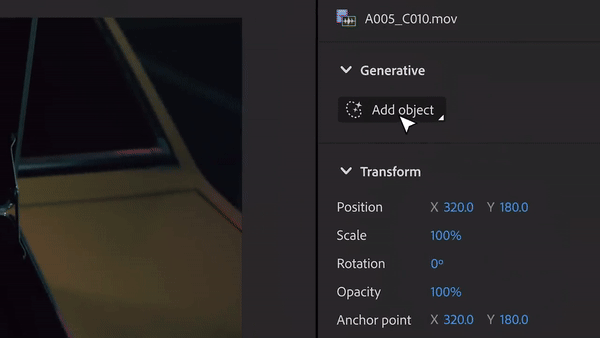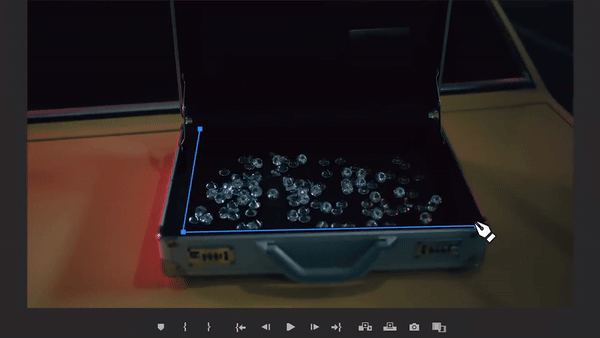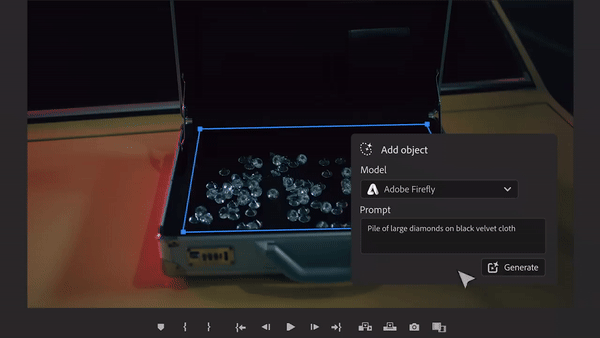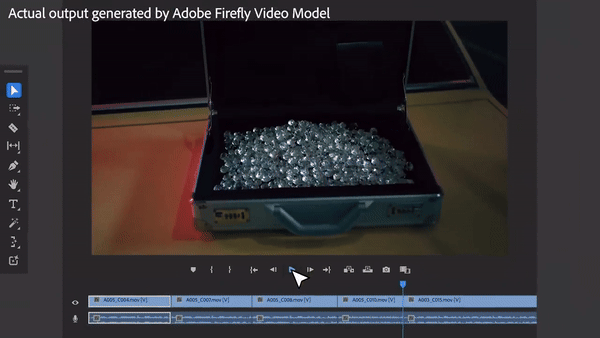
これは、少し前にAdobeのビデオ編集ソフトウェアPremiere Proが提示した「魔法」です。このソフトウェアは、Sora、Runway、Pika などの AI ビデオ ツールを導入し、ビデオ内のオブジェクトの追加、削除、ビデオ クリップの生成機能を実現します。これは、ビデオ分野におけるもう 1 つの技術革新とみなされます。
Soraが再びAdobeのマジックに世界を席巻した2月から、海外は本格化していきます。対照的に、中国はビデオ分野、特に長時間ビデオ生成の方向において依然として「待ち」の状態にある。過去 2 か月間、ソラを追求するという主張をいくつか聞いてきましたが、国内での大きな進展はまだ見られません。しかし、今日Shengshu Technologyが公開したばかりの短いビデオは、私たちに多くの驚きを与えてくれます。 
これは、Shengshu Technologyと清華大学がリリースした最新のビデオモデル「Vidu」の公式ビデオです。生成されるビデオは数秒間の「GIF」ではなくなり、10 秒以上に達することがわかります (最長で約 16 秒に達する場合もあります)。もちろん、さらに驚くべきことは、「Vidu」の画像効果は、複数のレンズの言語、時間と空間の一貫性において非常によく機能し、物理法則に従います。現実世界が存在しないという現実を作り上げます。現在のビデオ生成モデルでは実現が困難な、超現実的な画像 です。 Shengshu Technology はわずか 2 か月でこれほどの成果を達成することができ、本当に驚くべきことです。
Sora に対して完全にベンチマークを行う中国初のビデオモデル
Sora のリリース以来、「国産 Sora」をめぐる戦いが始まりました。しかし、業界が「長い」機能に注目すると、Sora の背後には実際には長いシーケンスにおける一貫性、リアリズム、美しさなどの総合的な効果の向上があるということを無視します。
総合的なエフェクトの観点から、「Vidu」はSoraに対してエフェクトレベルで完全ベンチマークを達成した最初で唯一の動画モデルであり、国内のみならず世界的にも、また、ソラに続く躍進。具体的な効果から、いくつかの明白な利点が明確にわかります:
ビデオに「レンズ言語」を挿入します
ビデオ制作には非常に重要な概念、レンズ言語があります。絵を通してストーリーを表現し、登場人物の心理を明らかにし、雰囲気を作り、観客の感情を誘導する主な方法です。さまざまなショットの選択、角度、動き、組み合わせが、物語と観客の体験に大きな影響を与えます。
既存の AI 生成ビデオでは、レンズ言語の単調さが明らかに感じられ、レンズの動きはわずかな押し、引き、シフトなどの単純なショットに限定されています。この背後にある主な理由は、ほとんどの既存のビデオ コンテンツ生成では、最初に 1 つのフレームが生成され、その後、前後の連続したフレームが予測されるためです。しかし、主流の技術パスでは、長期にわたる一貫した動的予測を実現することが困難です。昨年 7 月に作成された滑走路の SF 映画の予告編「予告編: ジェネシス」。

ヒント: 趣のある海辺の別荘では、太陽が部屋に降り注ぎ、カメラは静かな海を見下ろすバルコニーにゆっくりと移動し、最後にカメラは浮かぶ海、ヨット、反射する雲の上で静止します。 (完全なビデオクリップは Shengshu の PixWeaver 製品の公式 Web サイトで公開されています)
さらに、短編映画の複数のクリップからわかるように、「Vidu」はトランジション、フォーカストラッキング、ロングショットなどのエフェクトを直接生成できます。これには、映画やテレビレベルの映像を生成したり、レンズ言語を挿入したりする機能が含まれます。ビデオを編集し、全体像を強調します。



時間と空間の一貫性を維持する
ビデオ画像の一貫性と滑らかさは、実際にはキャラクターやシーンの時空間的な一貫性によって非常に重要です。空間内のキャラクターとして 動きは常に一貫しており、トランジションなしでシーンが突然変わることはありません。これを AI で実現するのは難しく、特に時間が経つにつれて、AI によって生成されたビデオには、物語の中断、視覚的な一貫性のなさ、論理的エラーなどの問題が発生し、ビデオのリアリズムと楽しさに重大な影響を及ぼします。
「Vidu」はこれらの問題をある程度克服しています。それによって生成された「真珠の耳飾りの猫」の映像を見ると、カメラが移動しても、被写体である猫が常に同じ表情や服装を3D空間内で維持しており、映像全体が変化していることがわかります。非常に一貫性があり、スムーズであり、良好な時間と空間の一貫性を維持します。 
ヒント: これは、フェルメールの「真珠の耳飾りの少女」にインスピレーションを得た、青い目のオレンジ色の猫の肖像画で、ゆっくりと回転しています。この写真は、真珠の耳飾りを付け、オランダ帽と同じような茶色の髪をしています。黒の背景、スタジオのライト。 (Shengshu の PixWeaver 製品の公式 Web サイトで公開された完全なビデオクリップ)
現実の物理世界のシミュレーション
Sora の驚くべき機能の 1 つは、次のような現実の物理世界の動きをシミュレートできることです。オブジェクトの動きと相互作用。 Sora がリリースした古典的なケースの 1 つである「丘の中腹を走る古い SUV」の写真は、タイヤによって巻き上げられるほこり、森の中の光と影、そして車の運転中に変化する影を非常によくシミュレートしています。 。同じプロンプト ワードの下で、「Vidu」と Sora が生成するエフェクトは非常に類似しており、塵、光、影などの詳細は、現実の物理世界での人間の経験に非常に近いです。  ヒント: 松の木に囲まれた険しい未舗装の道路をスピードダウンする黒いルーフラックを備えた白いビンテージ SUV をカメラが追跡します。タイヤは砂埃を巻き上げ、太陽の光が SUV に降り注ぎ、車に暖かい輝きを放ちます。シーン全体。未舗装の道路は緩やかに曲がりくねって遠くまで続き、他の車や車両は見えませんでした。道の両側にはセコイアの木が植えられており、所々に緑が点在しています。後ろから見ると、この車はカーブをスムーズに追従し、荒れた地形を走行しているように見えます。未舗装の道路は険しい丘や山々に囲まれており、その上には澄んだ青い空と雲の切れ端があります。 (Pixweaver 製品の公式 Web サイトで公開されている完全なビデオの断片)
ヒント: 松の木に囲まれた険しい未舗装の道路をスピードダウンする黒いルーフラックを備えた白いビンテージ SUV をカメラが追跡します。タイヤは砂埃を巻き上げ、太陽の光が SUV に降り注ぎ、車に暖かい輝きを放ちます。シーン全体。未舗装の道路は緩やかに曲がりくねって遠くまで続き、他の車や車両は見えませんでした。道の両側にはセコイアの木が植えられており、所々に緑が点在しています。後ろから見ると、この車はカーブをスムーズに追従し、荒れた地形を走行しているように見えます。未舗装の道路は険しい丘や山々に囲まれており、その上には澄んだ青い空と雲の切れ端があります。 (Pixweaver 製品の公式 Web サイトで公開されている完全なビデオの断片) 
Sora の演出効果。
もちろん、「Vidu」は「黒いルーフラック付き」の部分的な詳細を生成できませんでした。しかし、その欠点はその利点を隠すものではなく、その全体的な効果は現実世界に非常に近いものです。
🎜🎜豊かな想像力🎜🎜🎜 実際の撮影と比較して、AI を使用してビデオを生成することには、現実世界には存在しない画像を生成できるという大きな利点があります。以前は、これらの写真を作成したり特殊効果を作成したりするには、多くの人的資源と物的リソースが必要になることがよくありましたが、AI によって短時間で自動的に生成できるようになります。 🎜たとえば、以下のシーンでは、「帆船」と「波」がスタジオに現れることはほとんどなく、波と帆船の相互作用は非常に自然です。 
スタジオ内の船がカメラに向かって航行します。 (Shengshu の PixWeaver 製品の公式 Web サイトで公開されている完全なビデオクリップ)

短編映画の「水槽の女の子」クリップも素晴らしいですが、ある種の合理的な感覚を持っています。現実世界に存在しない画像を捏造するこの能力は、シュールレアリスムのコンテンツを作成するのに非常に役立ち、クリエイターにインスピレーションを与え、斬新な視覚体験を提供するだけでなく、芸術的表現の境界を広げ、より豊かで多様なコンテンツ形式をもたらします。
中国要素を理解する
上記の4つの特徴に加えて、「Vidu」が公開した短編映画からいくつかの異なる驚きも見られました。「Vidu」はパンダやドラゴンなどの独特の中国要素を含む画像を生成できます。宮殿のシーンなど。 
ヒント: 静かな湖のほとりで、パンダが熱心にギターを弾き、環境全体を生き生きとさせます。澄んだ空の下、穏やかな水面に映るこの光景は、臨場感とジャイアントパンダの生き生きとした精神を融合させた鮮やかなパノラマショットで捉えられ、エネルギーと静けさの調和がとれたものを作り出しています。 (Shenshu の PixWeaver 製品の公式 Web サイトで公開された完全なビデオクリップ)
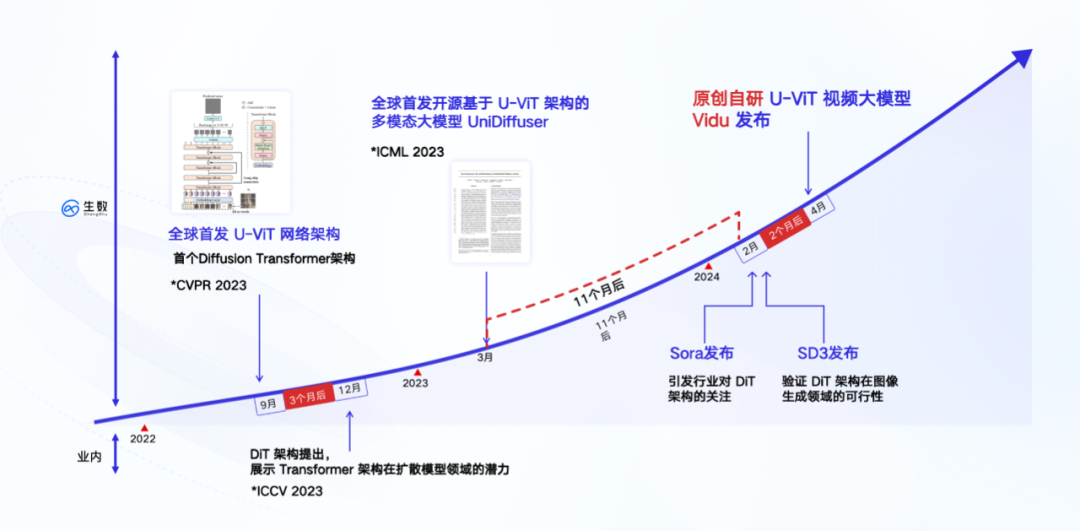
どうやって 2 か月でこの急速な進歩を達成したのですか?
「Vidu」の研究開発チームである Shengshu Technology は、中国のマルチモーダル大型モデル分野の起業家チームです。中心メンバーは清華大学の人工知能研究所の出身です。チームはマルチモーダルなモデルに焦点を当てています。画像、3D、ビデオなどのモーダル生成分野。
今年1月、Shengshu Technologyは、ビジュアルクリエイティブデザインプラットフォームPixWeaver上でショートビデオ生成機能を開始し、4秒の非常に審美的なショートビデオコンテンツをサポートしました。 2月にSoraを発表した後、Shengshu Technologyはオリジナルビデオの方向性の研究開発の進捗を加速するために正式な社内研究チームを設立したと報告されており、3月には社内で8秒ビデオの生成を達成し、その後ブレークスルーを果たした。 4 月には 16 秒世代が導入され、世代の品質と期間のあらゆる面で画期的な進歩が達成されました。
ご存知のとおり、Sora はこれほど短期間で画期的な進歩を遂げることができた背後にある核心は、チームの深い技術的蓄積と、特に 0 から 1 までの多くの独自の成果です。コア技術アーキテクチャのレベル。
「Vidu」の最下層は、2022年9月にチームが提案した完全自社開発のU-ViTアーキテクチャをベースとしています。Soraが採用したDiTアーキテクチャよりも古く、世界初のアーキテクチャです。 Diffusion と Transformer を統合したものです。

DiT 論文が発表される 2 か月前、清華大学の Zhu Jun のチームは「All are Worth Words: A ViT Backbone for Diffusion Models」という論文を提出しました。この論文では、CNN ベースの U-Net を置き換えるために Transformer を使用するネットワーク アーキテクチャ U-ViT を提案します。これが「Vidu」の最も重要な技術基盤です。
技術的なルートでは、「Vidu」はSoraとまったく同じディフュージョンとトランスフォーマーの融合アーキテクチャを採用しています。 「Vidu」は、フレームを補間して長い動画を生成する多段階の処理方法とは異なり、Soraと同じルート、つまりワンステップで直接高品質の動画を生成するルートを採用しています。低レベルの観点から見ると、これは単一のモデルに基づいて完全にエンドツーエンドで生成される「ワンステップ」の実装方法であり、中間フレームの挿入やその他のマルチステップの処理は含まれません。ビデオへの変換は直接的かつ連続的です。 さらに、U-ViT アーキテクチャに基づいて、チームは 2023 年 3 月に、オープンソースの大規模グラフィックおよびテキスト データ セット LAION-5B で 10 億のパラメーターを持つマルチモーダル モデル UniDiffuser をトレーニングし、作成しました。オープンソース (「清華大学の Zhu Jun チームが、Transformer に基づく初の大規模マルチモーダル拡散モデルをオープンソース化し、テキストと画像の相互運用と書き換えがすべて達成されました」を参照)。
UniDiffuser は主にグラフィックとテキストのタスクに優れており、グラフィック モードとテキスト モード間の任意の生成と変換をサポートできます。 UniDiffuser の実装には重要な価値があります。これにより、大規模なトレーニング タスクにおける融合アーキテクチャのスケーラビリティ (スケーリング則) が初めて検証されました。これは、大規模な U-ViT アーキテクチャのすべてのプロセスを実行するのと同等です。 -スケールトレーニングタスク。 UniDiffuser は、同じ DiT アーキテクチャを備えたグラフィック モデルである Stable Diffusion 3 の導入より 1 年早いことは言及する価値があります。
グラフィックおよびテキストタスクで蓄積されたこれらのエンジニアリング経験は、ビデオモデル開発の基礎を築きました。ビデオは本質的に画像のストリームであるため、タイムライン上の画像の拡大に相当します。したがって、画像やテキストのタスクで得られた結果は、多くの場合、ビデオ タスクで再利用できます。 Sora はまさにそれを実現します。DALL・E 3 の再アノテーション技術を使用してビジュアル トレーニング データの詳細な説明を生成し、モデルがユーザーのテキストによる指示に正確に従ってビデオを生成できるようにします。この効果は「ヴィドゥ」でも必ず発生します。
以前のニュースによると、「Vidu」はトレーニングアクセラレーション、並列トレーニング、低メモリトレーニングなどを含むグラフィックスやテキストタスクにおけるBioshu Technologyの経験を多く再利用しており、トレーニングプロセスを迅速に実行します。ビデオデータ圧縮技術を利用して入力データの系列次元を削減すると同時に、自社開発の分散トレーニングフレームワークを採用することで、計算精度を確保しながら通信効率を2倍にし、メモリオーバーヘッドを削減したという。 80% 増加し、トレーニング速度は 40 倍に増加しました。
「Vidu」は、グラフタスクの統合からビデオ機能の統合まで、より多様で長いビデオコンテンツの生成をサポートできる一般的なビジュアルモデルとみなすことができます。関係者はまた、「Vidu」が現在反復的な改善を加速していることも明らかにした。将来に向けて、「Vidu」の柔軟なモデル アーキテクチャは、より幅広いマルチモーダル機能とも互換性を持つようになります。
清華大学の有能なチーム
最後に、「Vidu」の背後にあるチームであるShengshu Technologyについて話しましょう。これは清華大学の背景を持つ有能なチームです。
Shengshu Technology のコアチームは清華大学人工知能研究所の出身です。主任科学者は清華大学人工知能研究所の副所長であるZhu Junであり、CEOのTang Jiayuは清華大学コンピューターサイエンス学部で学び、THUNLPグループのCTOであるBao Fanです。清華大学コンピューターサイエンス学部の博士課程の学生であり、Zhu Jun 教授 研究チームのメンバーであり、長年拡散モデルの分野の研究に携わっており、U-ViT と UniDiffuser の両方の完成を主導しました。
チームは 20 年以上にわたって生成人工知能とベイジアン機械学習の研究に従事しており、深層生成モデルのブレークスルーの初期に詳細な研究を実施しました。普及モデルに関しては、チームは中国でこの方向の研究を率先して立ち上げ、その成果にはバックボーンネットワーク、高速推論アルゴリズム、大規模トレーニングなどのフルスタック技術の方向性が含まれています。
チームは、ICML、NeurIPS、ICLR などの主要な人工知能カンファレンスでマルチモーダル分野に関連する 30 本近くの論文を発表しており、その中にはトレーニング不要の推論アルゴリズムである Analytic-DPM と DPM-Solver が提案されています。画期的な成果を上げ、ICLR優秀論文賞を受賞し、OpenAI、Apple、Stability.aiなどの海外最先端機関に採用され、DALL・E 2やStable Diffusionなどのスタープロジェクトでも使用されています。
2023年の設立以来、チームはAnt Group、Qiming Venture Partners、BV Baidu Ventures、Byte Jinqiu Fundなどの多くの有名な産業機関から認められ、数億元の資金調達を完了しました。 Shengshu Technology は現在、中国のマルチモーダル大型モデルトラックで最も高い評価を得ている起業家チームであると報告されています。 「Vidu」の発売は、マルチモーダルネイティブ大型モデルの分野における神舟テクノロジーのもう一つの革新とリーダーシップです。
関連記事:
《Shengshu TechnologyのTang Jiayu氏への独占インタビュー: Transformerは数億の資金調達を受けて、マルチモーダルな大型モデルを製造できるようになりました》
《国内企業がSoraを製造すると予想されていますか?清華大学の大規模モデルチームが希望を与えます》
以上が現時点で最強の国産ソラ!清華チームは 16 秒のビデオを突破し、複数のレンズを使った言語を理解し、物理法則をシミュレートできるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7749
7749
 15
1643
14
1397
52
1293
25
1234
29
15
1643
14
1397
52
1293
25
1234
29

 DeepMind ロボットが卓球をすると、フォアハンドとバックハンドが空中に滑り出し、人間の初心者を完全に打ち負かしました
Aug 09, 2024 pm 04:01 PM
DeepMind ロボットが卓球をすると、フォアハンドとバックハンドが空中に滑り出し、人間の初心者を完全に打ち負かしました
Aug 09, 2024 pm 04:01 PM
でももしかしたら公園の老人には勝てないかもしれない?パリオリンピックの真っ最中で、卓球が注目を集めています。同時に、ロボットは卓球のプレーにも新たな進歩をもたらしました。先ほど、DeepMind は、卓球競技において人間のアマチュア選手のレベルに到達できる初の学習ロボット エージェントを提案しました。論文のアドレス: https://arxiv.org/pdf/2408.03906 DeepMind ロボットは卓球でどれくらい優れていますか?おそらく人間のアマチュアプレーヤーと同等です: フォアハンドとバックハンドの両方: 相手はさまざまなプレースタイルを使用しますが、ロボットもそれに耐えることができます: さまざまなスピンでサーブを受ける: ただし、ゲームの激しさはそれほど激しくないようです公園の老人。ロボット、卓球用
 初のメカニカルクロー!元羅宝は2024年の世界ロボット会議に登場し、家庭に入ることができる初のチェスロボットを発表した
Aug 21, 2024 pm 07:33 PM
初のメカニカルクロー!元羅宝は2024年の世界ロボット会議に登場し、家庭に入ることができる初のチェスロボットを発表した
Aug 21, 2024 pm 07:33 PM
8月21日、2024年世界ロボット会議が北京で盛大に開催された。 SenseTimeのホームロボットブランド「Yuanluobot SenseRobot」は、全製品ファミリーを発表し、最近、世界初の家庭用チェスロボットとなるYuanluobot AIチェスプレイロボット - Chess Professional Edition(以下、「Yuanluobot SenseRobot」という)をリリースした。家。 Yuanluobo の 3 番目のチェス対局ロボット製品である新しい Guxiang ロボットは、AI およびエンジニアリング機械において多くの特別な技術アップグレードと革新を経て、初めて 3 次元のチェスの駒を拾う機能を実現しました。家庭用ロボットの機械的な爪を通して、チェスの対局、全員でのチェスの対局、記譜のレビューなどの人間と機械の機能を実行します。
 クロードも怠け者になってしまった!ネチズン: 自分に休日を与える方法を学びましょう
Sep 02, 2024 pm 01:56 PM
クロードも怠け者になってしまった!ネチズン: 自分に休日を与える方法を学びましょう
Sep 02, 2024 pm 01:56 PM
もうすぐ学校が始まり、新学期を迎える生徒だけでなく、大型AIモデルも気を付けなければなりません。少し前、レディットはクロードが怠け者になったと不満を漏らすネチズンでいっぱいだった。 「レベルが大幅に低下し、頻繁に停止し、出力も非常に短くなりました。リリースの最初の週は、4 ページの文書全体を一度に翻訳できましたが、今では 0.5 ページの出力さえできません」 !」 https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ というタイトルの投稿で、「クロードには完全に失望しました」という内容でいっぱいだった。
 世界ロボット会議で「未来の高齢者介護の希望」を担う家庭用ロボットを囲みました
Aug 22, 2024 pm 10:35 PM
世界ロボット会議で「未来の高齢者介護の希望」を担う家庭用ロボットを囲みました
Aug 22, 2024 pm 10:35 PM
北京で開催中の世界ロボット会議では、人型ロボットの展示が絶対的な注目となっているスターダストインテリジェントのブースでは、AIロボットアシスタントS1がダルシマー、武道、書道の3大パフォーマンスを披露した。文武両道を備えた 1 つの展示エリアには、多くの専門的な聴衆とメディアが集まりました。弾性ストリングのエレガントな演奏により、S1 は、スピード、強さ、正確さを備えた繊細な操作と絶対的なコントロールを発揮します。 CCTVニュースは、「書道」の背後にある模倣学習とインテリジェント制御に関する特別レポートを実施し、同社の創設者ライ・ジエ氏は、滑らかな動きの背後にあるハードウェア側が最高の力制御と最も人間らしい身体指標(速度、負荷)を追求していると説明した。など)、AI側では人の実際の動きのデータが収集され、強い状況に遭遇したときにロボットがより強くなり、急速に進化することを学習することができます。そしてアジャイル
 ACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
ACL 2024 賞の発表: HuaTech による Oracle 解読に関する最優秀論文の 1 つ、GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
貢献者はこの ACL カンファレンスから多くのことを学びました。 6日間のACL2024がタイのバンコクで開催されています。 ACL は、計算言語学と自然言語処理の分野におけるトップの国際会議で、国際計算言語学協会が主催し、毎年開催されます。 ACL は NLP 分野における学術的影響力において常に第一位にランクされており、CCF-A 推奨会議でもあります。今年の ACL カンファレンスは 62 回目であり、NLP 分野における 400 以上の最先端の作品が寄せられました。昨日の午後、カンファレンスは最優秀論文およびその他の賞を発表しました。今回の優秀論文賞は7件(未発表2件)、最優秀テーマ論文賞1件、優秀論文賞35件です。このカンファレンスでは、3 つの Resource Paper Award (ResourceAward) と Social Impact Award (
 宏蒙スマートトラベルS9とフルシナリオ新製品発売カンファレンス、多数の大ヒット新製品が一緒にリリースされました
Aug 08, 2024 am 07:02 AM
宏蒙スマートトラベルS9とフルシナリオ新製品発売カンファレンス、多数の大ヒット新製品が一緒にリリースされました
Aug 08, 2024 am 07:02 AM
今日の午後、Hongmeng Zhixingは新しいブランドと新車を正式に歓迎しました。 8月6日、ファーウェイはHongmeng Smart Xingxing S9およびファーウェイのフルシナリオ新製品発表カンファレンスを開催し、パノラマスマートフラッグシップセダンXiangjie S9、新しいM7ProおよびHuawei novaFlip、MatePad Pro 12.2インチ、新しいMatePad Air、Huawei Bisheng Withを発表しました。レーザー プリンタ X1 シリーズ、FreeBuds6i、WATCHFIT3、スマート スクリーン S5Pro など、スマート トラベル、スマート オフィスからスマート ウェアに至るまで、多くの新しいオールシナリオ スマート製品を開発し、ファーウェイは消費者にスマートな体験を提供するフル シナリオのスマート エコシステムを構築し続けています。すべてのインターネット。宏孟志興氏:スマートカー業界のアップグレードを促進するための徹底的な権限付与 ファーウェイは中国の自動車業界パートナーと提携して、
 Li Feifei 氏のチームは、ロボットに空間知能を与え、GPT-4o を統合する ReKep を提案しました
Sep 03, 2024 pm 05:18 PM
Li Feifei 氏のチームは、ロボットに空間知能を与え、GPT-4o を統合する ReKep を提案しました
Sep 03, 2024 pm 05:18 PM
ビジョンとロボット学習の緊密な統合。最近話題の1X人型ロボットNEOと合わせて、2つのロボットハンドがスムーズに連携して服をたたむ、お茶を入れる、靴を詰めるといった動作をしていると、いよいよロボットの時代が到来するのではないかと感じられるかもしれません。実際、これらの滑らかな動きは、高度なロボット技術 + 精緻なフレーム設計 + マルチモーダル大型モデルの成果です。有用なロボットは多くの場合、環境との複雑かつ絶妙な相互作用を必要とし、環境は空間領域および時間領域の制約として表現できることがわかっています。たとえば、ロボットにお茶を注いでもらいたい場合、ロボットはまずティーポットのハンドルを掴んで、お茶をこぼさないように垂直に保ち、次にポットの口がカップの口と揃うまでスムーズに動かす必要があります。 、そしてティーポットを一定の角度に傾けます。これ
 分散型人工知能カンファレンス DAI 2024 論文募集: エージェント デイ、強化学習の父であるリチャード サットン氏が出席します。 Yan Shuicheng、Sergey Levine、DeepMind の科学者が基調講演を行います
Aug 22, 2024 pm 08:02 PM
分散型人工知能カンファレンス DAI 2024 論文募集: エージェント デイ、強化学習の父であるリチャード サットン氏が出席します。 Yan Shuicheng、Sergey Levine、DeepMind の科学者が基調講演を行います
Aug 22, 2024 pm 08:02 PM
会議の紹介 科学技術の急速な発展に伴い、人工知能は社会の進歩を促進する重要な力となっています。この時代に、分散型人工知能 (DAI) の革新と応用を目撃し、参加できることは幸運です。分散型人工知能は人工知能分野の重要な分野であり、近年ますます注目を集めています。大規模言語モデル (LLM) に基づくエージェントは、大規模モデルの強力な言語理解機能と生成機能を組み合わせることで、自然言語対話、知識推論、タスク計画などにおいて大きな可能性を示しました。 AIAgent は大きな言語モデルを引き継ぎ、現在の AI 界隈で話題になっています。アウ
