

Xiaohongshu は記憶メカニズムからの情報検索を解釈し、EACL Oral を取得するための新しいパラダイムを提案します


最近、Xiaohongshu検索アルゴリズムチームの論文「Generative Dense Retrieval: Memory Can Be a Burden」が、自然言語処理分野の国際会議であるEACL 2024に口頭発表として採択され、採択率が高くなりました。 11.32% (144/1271 )。
彼らは論文の中で、新しい情報検索パラダイムである生成密検索 (GDR) を提案しました。 このパラダイムは、大規模なデータセットを処理する際に従来の生成検索 (GR) が直面する課題を十分に解決できます。それは記憶のメカニズムからインスピレーションを得たものです。
これまでの実践では、GR は独自のメモリ メカニズムに依存して、クエリとドキュメント ライブラリ間の詳細な対話を実現していました。ただし、言語モデルの自己回帰コーディングに依存するこの方法には、大規模なデータを処理する場合、あいまいで細かいドキュメントの特徴、ドキュメント ライブラリのサイズの制限、インデックスの更新の難しさなど、明らかな制限があります。
Xiaohongshu によって提案された GDR は、粗いものから細かいものまでの 2 段階の検索のアイデアを採用しています。まず、言語モデルの限られたメモリ容量を使用してクエリとドキュメントのマッピングを実現し、次にベクトル マッチング メカニズムを使用して、ドキュメントからドキュメントへのマッピングを完了します。 GDR は、密なセットを取得するためのベクトル マッチング メカニズムを導入することにより、GR 固有の欠点を効果的に軽減します。
さらに、チームは、それぞれ 2 つの段階の検索パフォーマンスを向上させるために、「メモリに優しい文書クラスター識別子構築戦略」と「文書クラスター適応型ネガティブ サンプリング戦略」も設計しました。 Natural question データセットの複数の設定の下で、GDR は SOTA の Recall@k パフォーマンスを実証しただけでなく、深いインタラクションの利点を維持しながら優れたスケーラビリティを達成し、情報検索に関する将来の研究に新たな可能性を切り開きました。
1. 背景
テキスト検索ツールには重要な研究価値と応用価値があります。単語マッチングに基づくスパース検索 (SR) やセマンティック ベクトル マッチングに基づくデンス検索 (DR) などの従来の検索パラダイムは、それぞれに独自の利点がありますが、これに基づく事前トレーニング済み言語モデルの台頭により、生成検索が登場しました。というパラダイムが生まれ始めました。 生成検索パラダイムの始まりは、主にクエリと候補ドキュメント間の意味論的な一致に基づいていました。クエリとドキュメントを同じ意味空間にマッピングすることにより、候補ドキュメントの検索問題はベクトル一致度の密な検索に変換されます。この画期的な検索パラダイムは、事前トレーニングされた言語モデルを利用し、テキスト検索の分野に新たな機会をもたらします。 しかし、生成検索パラダイムは依然として課題に直面しています。一方で、既存の事前トレーニング
トレーニング プロセス中に、モデルは、コンテキストとして指定されたクエリを使用して、関連するドキュメントの識別子を自己回帰的に生成します。このプロセスにより、モデルは候補コーパスを記憶できるようになります。クエリがモデルに入った後、クエリはモデル パラメーターと相互作用し、自己回帰的にデコードされます。これにより、クエリと候補コーパスの間に深い相互作用が暗黙的に生成されます。この深い相互作用は、まさに SR と DR に欠けているものです。したがって、モデルが候補文書を正確に記憶できれば、GR は優れた検索パフォーマンスを発揮できます。
ただし、GR の記憶機構は完璧ではありません。古典的な DR モデル (AR2) と GR モデル (NCI) の比較実験を通じて、メモリ メカニズムが少なくとも 3 つの大きな課題をもたらすことを確認しました:
1) きめ細かい文書特徴のぼかし:
文書識別子の各ビットを粗いものから細かいものまでデコードするときに、NCI と AR2 がエラーを起こす確率をそれぞれ計算しました。 AR2 の場合、ベクトル マッチングを通じて、特定のクエリに最も関連性の高いドキュメントに対応する識別子を見つけ、その識別子の最初のエラー ステップをカウントして、AR2 に対応する段階的な復号エラー率を取得します。表 1 に示すように、NCI はデコードの前半では良好なパフォーマンスを示しますが、後半ではエラー率が高くなり、AR2 ではその逆が当てはまります。これは、NCI がメモリ データベース全体を通じて候補文書の意味空間の粗粒マッピングをより適切に完了できることを示しています。ただし、トレーニング プロセス中に選択された特徴は検索によって決定されるため、その詳細なマッピングを正確に記憶するのは難しく、そのため詳細なマッピングのパフォーマンスは低くなります。

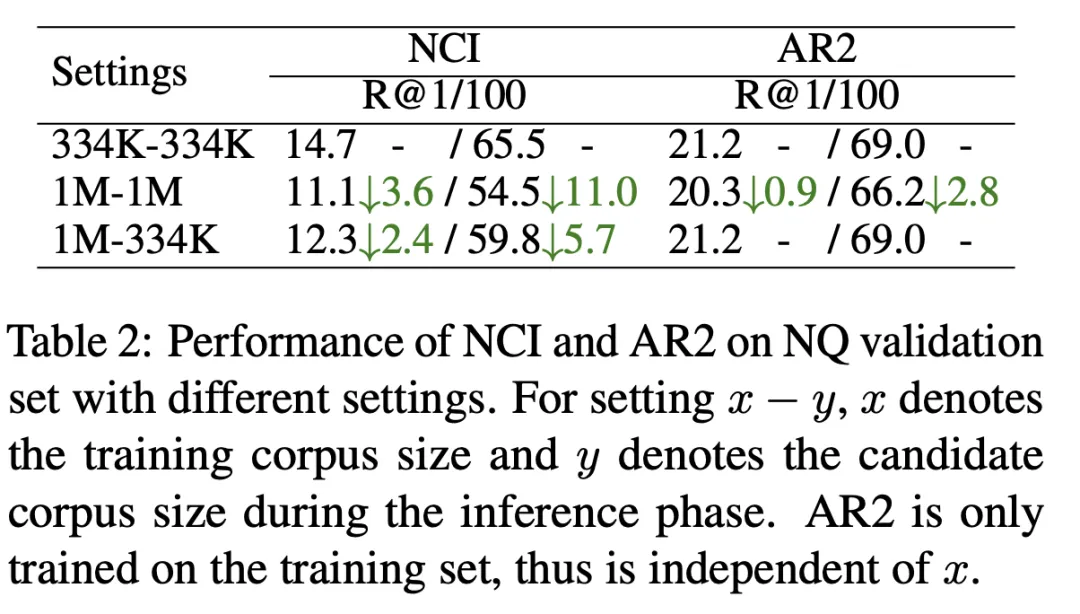
2) ドキュメント ライブラリのサイズは制限されています:
表 2 に示すように、候補ドキュメント ライブラリ サイズ 334K (最初の行) と候補ドキュメント サイズ 1M (2 行目) で NCI モデルをトレーニングしました。 R@kインジケーターでテスト済み。結果は、NCI が R@100 で 11 ポイント低下したのに対し、AR2 は 2.8 ポイントしか低下しなかったことを示しています。候補ドキュメント ライブラリのサイズが増加すると NCI パフォーマンスが大幅に低下する理由を調査するために、候補ドキュメント ライブラリとして 334K を使用した場合に、1M ドキュメント ライブラリでトレーニングされた NCI モデルのテスト結果をさらにテストします (3 行目)。最初の行と比較して、より多くの文書を記憶するという NCI の負担により、再現パフォーマンスが大幅に低下します。これは、モデルの限られたメモリ容量により、大規模な候補文書ライブラリを記憶する能力が制限されていることを示しています。
3) インデックス更新の難易度:
新しい文書を候補ライブラリに追加する必要がある場合、文書識別子を更新する必要があり、モデルを再トレーニングする必要があります。 -すべての書類を暗記します。そうしないと、古いマッピング (クエリからドキュメント識別子、およびドキュメント識別子からドキュメント) により、検索パフォーマンスが大幅に低下します。
上記の問題は、実際のシナリオでの GR の適用を妨げています。このため、解析の結果、DRのマッチング機構は記憶機構と補完的な関係にあると考えられ、そのデメリットを抑えつつ記憶機構を維持するためにGRに導入することを検討しています。 私たちは生成高密度検索 (GDR) の新しいパラダイムを提案しました:
- 私たちは、クラスター間マッチング (クエリーからドキュメントクラスターへのマッピング) を達成するためにメモリーメカニズムを使用して、粗いものから細かいものまでの全体的な 2 段階の検索フレームワークを設計しました。 )、クラスタ内マッチング(ドキュメントへのドキュメント クラスタのマッピング)は、ベクトル マッチング メカニズムを通じて完了します。
- モデルが候補文書ライブラリを記憶できるようにするために、モデルのメモリ容量に基づいて文書クラスターの分割粒度を制御し、クラスター間のマッチングを改善する、メモリに優しい文書クラスター識別子構築戦略を構築しました。効果。
- トレーニング段階では、2 段階検索の特性に基づいて、文書クラスターに対する適応的なネガティブ サンプリング戦略を提案します。これにより、クラスター内のネガティブ サンプルの重みが強化され、クラスター内のマッチング効果が増加します。
2.1 記憶メカニズムに基づくクラスター間マッチング
クエリを入力として受け取り、言語モデルを使用して候補ドキュメント ライブラリを記憶し、k 個の関連ドキュメント クラスター (CID) を自己回帰的に生成して完了します。次のマッピング:
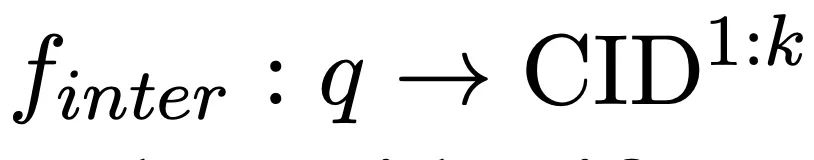
このプロセスでは、CID の生成確率は次のとおりです:
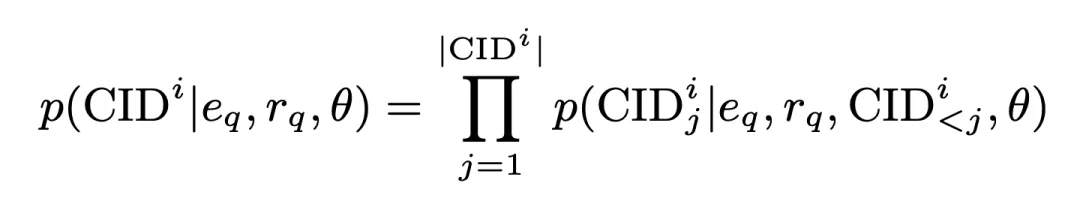
ここで、
はエンコーダによって生成されたすべてのクエリ埋め込みです
は生成されたものですエンコーダによる次元クエリ表現。この確率はクラスター間マッチング スコアとしても保存され、後続の操作に関与します。これに基づいて、標準のクロスエントロピー損失を使用してモデルをトレーニングします。
2.2 ベクトルマッチングメカニズムに基づくクラスター内マッチング
さらに、候補ドキュメントクラスターから候補ドキュメントを取得し、完全なイントラ-クラスターマッチング:
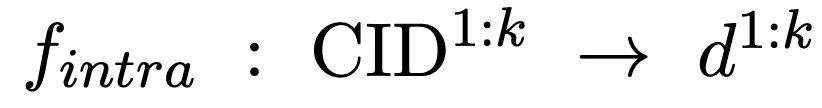
候補文書の表現を抽出するために文書エンコーダーを導入し、このプロセスはオフラインで完了します。これに基づいて、クラスター内のドキュメントとクエリ間の類似性をクラスター内マッチング スコアとして計算します:

このプロセスでは、NLL 損失を使用してモデルをトレーニングします:
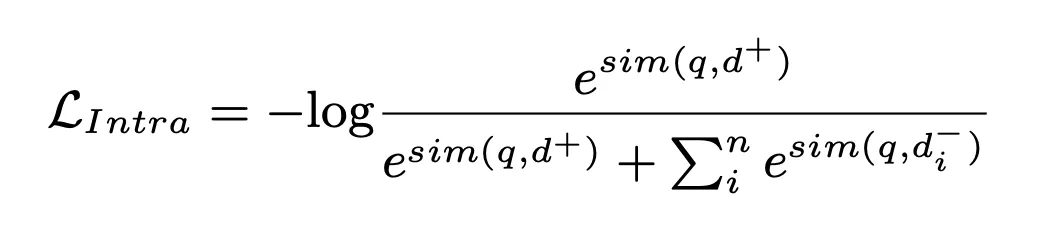
最後に、ドキュメントのクラスター間マッチング スコアとクラスター内マッチング スコアの重み付け値を計算して並べ替え、上位 K を取得した関連ドキュメントとして選択します。
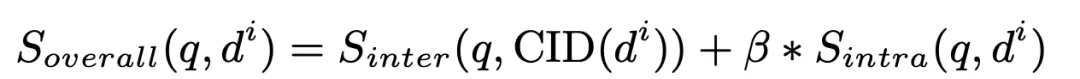
ここで、ベータは実験では 1 に設定します。
2.3 メモリに優しい文書クラスター識別子構築戦略
モデルの限られたメモリ容量を最大限に活用して、クエリと候補文書ライブラリ間の深い相互作用を実現するために、メモリに優しい文書クラスターを提案します。識別子構築戦略。この戦略では、まずモデルのメモリ容量をベンチマークとして使用して、クラスター内のドキュメント数の上限を計算します。
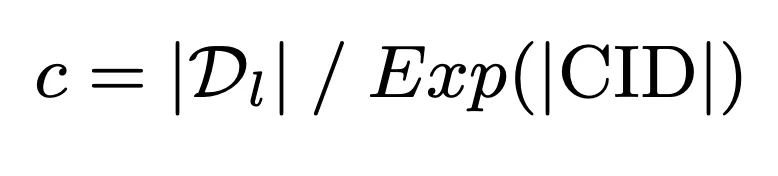
これに基づいて、K 平均法アルゴリズムを通じてドキュメント クラスター識別子がさらに構築されます。モデルのメモリ負荷がメモリ容量を超えないことを確認します。

2.4 ドキュメント クラスタの適応型ネガティブ サンプリング戦略
GDR 2 段階の取得フレームワークにより、クラスタ内のネガティブ サンプルが占める割合が決定されます。クラスタ内マッチング プロセスではその割合が大きくなります。この目的を達成するために、トレーニングの第 2 段階でドキュメント クラスター分割をベンチマークとして使用し、クラスター内の負のサンプルの重みを明示的に強化します。これにより、より優れたクラスター内マッチング結果が得られます。 3. 実験
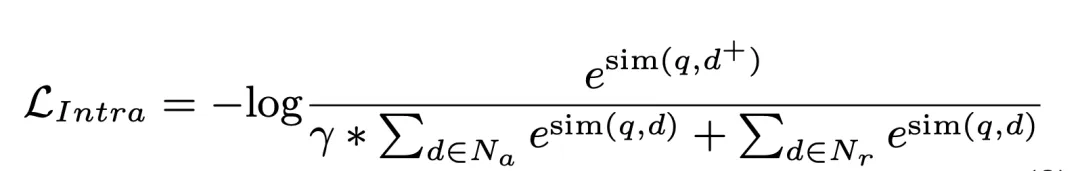 実験で使用されたデータセットは、58,000 のトレーニング ペア (クエリと関連ドキュメント) と 6,000 の検証ペア、および 2,100 万の候補ドキュメント ライブラリを含む Natural question (NQ) です。各クエリには複数の関連ドキュメントがあり、モデルの再現パフォーマンスに対してより高い要件が課されます。さまざまなサイズの文書ベースで GDR のパフォーマンスを評価するために、完全な 2100 万コーパスの残りのパッセージを NQ334K に追加することで、NQ334K、NQ1M、NQ2M、NQ4M などのさまざまな設定を構築しました。 GDR は、より大きな候補ドキュメント ライブラリの意味情報がより小さなコーパスに漏洩することを防ぐために、各データセットに個別に CID を生成します。 SR ベースラインとして BM25 (Anserini 実装)、DR ベースラインとして DPR および AR2、GR ベースラインとして NCI を採用します。評価指標には R@k と Acc@k が含まれます。
実験で使用されたデータセットは、58,000 のトレーニング ペア (クエリと関連ドキュメント) と 6,000 の検証ペア、および 2,100 万の候補ドキュメント ライブラリを含む Natural question (NQ) です。各クエリには複数の関連ドキュメントがあり、モデルの再現パフォーマンスに対してより高い要件が課されます。さまざまなサイズの文書ベースで GDR のパフォーマンスを評価するために、完全な 2100 万コーパスの残りのパッセージを NQ334K に追加することで、NQ334K、NQ1M、NQ2M、NQ4M などのさまざまな設定を構築しました。 GDR は、より大きな候補ドキュメント ライブラリの意味情報がより小さなコーパスに漏洩することを防ぐために、各データセットに個別に CID を生成します。 SR ベースラインとして BM25 (Anserini 実装)、DR ベースラインとして DPR および AR2、GR ベースラインとして NCI を採用します。評価指標には R@k と Acc@k が含まれます。
NQ データセットでは、GDR は R@k メトリックで平均 3.0 向上し、Acc@k メトリックでは 2 位にランクされています。これは、GDR が、深い相互作用における記憶メカニズムの利点と、粗い検索から細かい検索プロセスを介したきめの細かい特徴識別におけるマッチング メカニズムの利点を最大化していることを示しています。
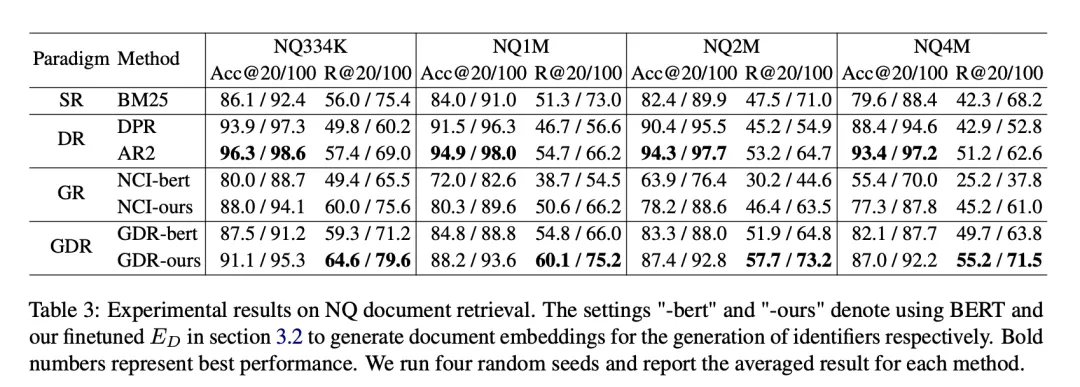
3.2 より大きなコーパスへのスケーリング
候補コーパスをより大きなサイズにスケーリングすると、SR と DR の R@100 削減率は 4.06% 未満のままであるのに対し、GR は3 つの拡大方向すべての下落率は 15.25% を超えています。対照的に、GDR は、メモリ内容を一定量のコーパスの粗粒度特徴に集中させることにより、SR および DR と同様の平均 R@100 削減率 3.50% を達成します。
3.3 アブレーション実験
表 3 GDR-bert と GDR-ours はそれぞれ、従来の戦略と CID 構築戦略の下での対応するモデルのパフォーマンスを表しています。この実験では、メモリの使用が証明されています。フレンドリーなドキュメント クラスター識別子構築戦略によりメモリの負担が大幅に軽減され、それによって検索パフォーマンスの向上につながります。さらに、表 4 は、GDR トレーニングで使用されるドキュメント クラスター適応ネガティブ サンプリング戦略が、ドキュメント クラスター内でより識別的な信号を提供することにより、きめの細かいマッチング機能を強化することを示しています。 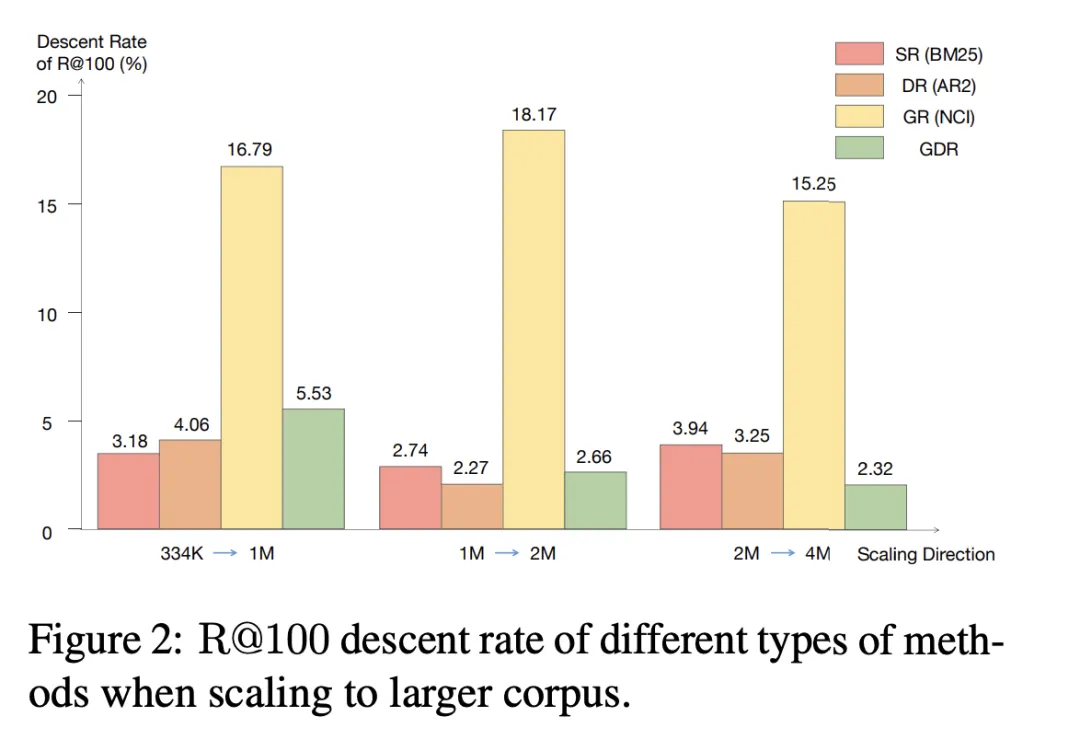
3.4 新しい文書の追加
新しい文書が候補文書ライブラリに追加されると、GDR はその新しい文書を最も近い文書クラスタークラスターセンターに追加し、それに対応する識別子を割り当てます。同時に、ドキュメント エンコーダによってベクトル表現が抽出され、ベクトル インデックスが更新され、それによって新しいドキュメントの迅速な拡張が完了します。表 6 に示すように、候補コーパスに新しい文書を追加する設定では、NCI の R@100 は 18.3 パーセント ポイント低下しますが、GDR のパフォーマンスは 1.9 パーセント ポイントしか低下しません。これは、GDR がマッチング メカニズムを導入することでメモリ メカニズムの困難なスケーラビリティを軽減し、モデルを再トレーニングすることなく良好なリコール効果を維持していることを示しています。 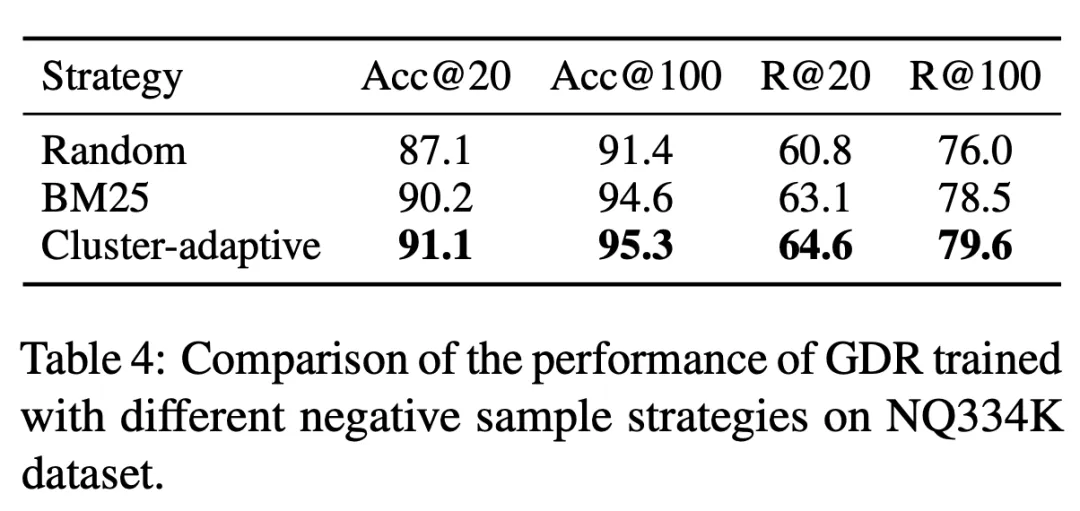
3.5 制限事項
言語モデルの自己回帰生成の特性により制限されますが、GDR は第 2 段階でベクトルマッチング機構を導入しており、GR と比較して大幅な検索効率の向上を実現していますが、DR と比較するとまだ多くの制限があります。 SRに関しては改善の余地あり。私たちは、検索フレームワークへのメモリメカニズムの導入によって引き起こされる遅延の問題を軽減するために、将来のさらなる研究を期待しています。
4. 結論
この研究では、情報検索における記憶メカニズムの諸刃の剣の効果を深く調査しました。一方で、このメカニズムはクエリと候補の間の深い相互作用を実現します。ドキュメント ライブラリ。一方で、モデルのメモリ容量が限られており、インデックスの更新が複雑なため、大規模で動的に変化する候補ドキュメント ライブラリの処理が困難になります。 この問題を解決するために、メモリ機構とベクトルマッチング機構を階層的に革新的に組み合わせ、両者の長所を最大限に発揮し、短所を回避し、相互に補完できるようにしました。
私たちは、新しいテキスト検索パラダイム、Generative Dense Retrieval (GDR) を提案します。 GDR このパラダイムは、指定されたクエリに対して粗い検索から細かい検索までの 2 段階の検索を実行します。まず、メモリ メカニズムが自己回帰的にドキュメント クラスター識別子を生成してクエリをドキュメント クラスターにマッピングし、次にベクトル マッチング メカニズムがそれらの間の関係を計算します。クエリとドキュメントの類似性により、ドキュメント クラスターのドキュメントへのマッピングが完了します。
メモリに優しいドキュメント クラスター識別子構築戦略により、モデルのメモリ負荷がメモリ容量を超えず、クラスター間のマッチング効果が高まります。ドキュメントクラスター適応ネガティブサンプリング戦略は、クラスター内のネガティブサンプルを区別するためのトレーニング信号を強化し、クラスター内のマッチング効果を高めます。 広範な実験により、GDR が大規模な候補ドキュメント ライブラリに対して優れた検索パフォーマンスを達成し、ドキュメント ライブラリの更新に効率的に対応できることが証明されました。
従来の検索方法の利点を統合する成功した試みとして、生成集中検索パラダイムには、大規模な候補ドキュメント ライブラリを含むシナリオでの優れた再現パフォーマンス、強力なスケーラビリティ、および堅牢なパフォーマンスという利点があります。大規模な言語モデルの理解と生成能力が向上し続けるにつれて、生成的な集中検索のパフォーマンスがさらに向上し、情報検索のより広い世界が開かれるでしょう。
論文アドレス:https://www.php.cn/link/9e69fd6d1c5d1cef75ffbe159c1f322e
5. 著者紹介
-
ユアン・ペイウェン
now Ph.D. 北京理工大学で学び、Xiaohongshu コミュニティ検索チームでインターンとして働き、NeurIPS、ICLR、AAAI、EACL などで多くの第一著者論文を発表。主な研究方向は、大規模言語モデルの推論と評価、および情報検索です。 -
王星霖
現在、北京工業大学に留学しており、Xiaohongshu Community Search Groupでインターンをしており、EACL、NeurIPS、ICLRなどでいくつかの論文を発表し、International Dialogue Technologyに参加していますChallenge DSTC11 評価トラックで2位獲得。主な研究方向は、大規模言語モデルの推論と評価、および情報検索です。 -
Feng Shaoxiong
はXiaohongshuコミュニティ検索ベクトルリコールの責任者です。北京理工大学で博士号を取得し卒業し、ICLR、AAAI、ACL、EMNLP、NAACL、EACL、KBSなどの機械学習および自然言語処理の分野のトップカンファレンス/ジャーナルにいくつかの論文を発表しています。 。主な研究方向には、大規模言語モデルの評価、推論蒸留、生成検索、オープンドメイン対話生成などが含まれます。 -
Daoxuan
Xiaohongshu取引検索チームの責任者。浙江大学で博士号を取得し、NeurIPS や ICML などの機械学習分野のトップカンファレンスでいくつかの第一著者論文を発表し、長年にわたり多くのトップカンファレンス/ジャーナルの査読者を務めています。主な事業内容は、コンテンツ検索、電子商取引検索、ライブ放送検索などです。 -
Zeng Shu
は清華大学電子工学科を卒業し、インターネット分野で自然言語処理、推奨、検索などのアルゴリズムの研究に従事しています。現在、Xiaohongshu コミュニティ検索におけるリコールと垂直検索、およびその他の技術的方向性を担当しています。
以上がXiaohongshu は記憶メカニズムからの情報検索を解釈し、EACL Oral を取得するための新しいパラダイムを提案しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7456
7456
 15
1376
52
77
11
16
10
15
1376
52
77
11
16
10

 トークン化を 1 つの記事で理解しましょう!
Apr 12, 2024 pm 02:31 PM
トークン化を 1 つの記事で理解しましょう!
Apr 12, 2024 pm 02:31 PM
言語モデルは、通常は文字列の形式であるテキストについて推論しますが、モデルへの入力は数値のみであるため、テキストを数値形式に変換する必要があります。トークン化は自然言語処理の基本タスクであり、特定のニーズに応じて、連続するテキスト シーケンス (文、段落など) を文字シーケンス (単語、フレーズ、文字、句読点など) に分割できます。その中の単位はトークンまたはワードと呼ばれます。以下の図に示す具体的なプロセスに従って、まずテキスト文がユニットに分割され、次に単一の要素がデジタル化され (ベクトルにマッピングされ)、次にこれらのベクトルがエンコード用のモデルに入力され、最後に下流のタスクに出力され、さらに最終結果を取得します。テキストセグメンテーションは、テキストセグメンテーションの粒度に応じて Toke に分割できます。
 新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
新しい科学的で複雑な質問応答ベンチマークと大規模モデルの評価システムを提供するために、UNSW、アルゴンヌ、シカゴ大学、およびその他の機関が共同で SciQAG フレームワークを立ち上げました。
Jul 25, 2024 am 06:42 AM
編集者 |ScienceAI 質問応答 (QA) データセットは、自然言語処理 (NLP) 研究を促進する上で重要な役割を果たします。高品質の QA データ セットは、モデルの微調整に使用できるだけでなく、大規模言語モデル (LLM) の機能、特に科学的知識を理解し推論する能力を効果的に評価することもできます。現在、医学、化学、生物学、その他の分野をカバーする多くの科学 QA データ セットがありますが、これらのデータ セットにはまだいくつかの欠点があります。まず、データ形式は比較的単純で、そのほとんどが多肢選択式の質問であり、評価は簡単ですが、モデルの回答選択範囲が制限され、科学的な質問に回答するモデルの能力を完全にテストすることはできません。対照的に、自由回答型の Q&A
 大規模なモデルをクラウドにデプロイするための 3 つの秘密
Apr 24, 2024 pm 03:00 PM
大規模なモデルをクラウドにデプロイするための 3 つの秘密
Apr 24, 2024 pm 03:00 PM
コンピレーション|Xingxuan によって制作|51CTO テクノロジー スタック (WeChat ID: blog51cto) 過去 2 年間、私は従来のシステムよりも大規模言語モデル (LLM) を使用した生成 AI プロジェクトに多く関与してきました。サーバーレス クラウド コンピューティングが恋しくなってきました。そのアプリケーションは、会話型 AI の強化から、さまざまな業界向けの複雑な分析ソリューションやその他の多くの機能の提供まで多岐にわたります。多くの企業は、パブリック クラウド プロバイダーが既製のエコシステムをすでに提供しており、それが最も抵抗の少ない方法であるため、これらのモデルをクラウド プラットフォームにデプロイしています。ただし、安くはありません。クラウドは、スケーラビリティ、効率、高度なコンピューティング機能 (オンデマンドで利用可能な GPU) などの他の利点も提供します。パブリック クラウド プラットフォームでの LLM の展開については、あまり知られていない側面がいくつかあります
 大規模言語モデルの効率的なパラメータ微調整 - BitFit/Prefix/Prompt 微調整シリーズ
Oct 07, 2023 pm 12:13 PM
大規模言語モデルの効率的なパラメータ微調整 - BitFit/Prefix/Prompt 微調整シリーズ
Oct 07, 2023 pm 12:13 PM
2018 年に Google が BERT をリリースしました。リリースされると、11 個の NLP タスクの最先端 (Sota) 結果を一気に打ち破り、NLP 界の新たなマイルストーンとなりました。BERT の構造は次のとおりです。下の図では、左側は BERT モデルのプリセット、右側はトレーニング プロセス、右側は特定のタスクの微調整プロセスです。このうち、微調整ステージは、テキスト分類、品詞のタグ付け、質問と回答システムなど、その後のいくつかの下流タスクで使用されるときに微調整するためのものです。BERT はさまざまな上で微調整できます。構造を調整せずにタスクを実行できます。 「事前トレーニング済み言語モデル + 下流タスク微調整」のタスク設計により、強力なモデル効果をもたらします。以来、「言語モデルの事前トレーニング + 下流タスクの微調整」が NLP 分野のトレーニングの主流になりました。
 史上最大の ViT を便利にトレーニングしましたか? Google、ビジュアル言語モデルPaLIをアップグレード:100以上の言語をサポート
Apr 12, 2023 am 09:31 AM
史上最大の ViT を便利にトレーニングしましたか? Google、ビジュアル言語モデルPaLIをアップグレード:100以上の言語をサポート
Apr 12, 2023 am 09:31 AM
近年の自然言語処理の進歩は主に大規模言語モデルによるものであり、新しいモデルがリリースされるたびにパラメータと学習データの量が新たな最高値に押し上げられ、同時に既存のベンチマーク ランキングが壊滅することになります。たとえば、今年 4 月に Google は、5,400 億パラメータの言語モデル PaLM (Pathways Language Model) をリリースしました。これは、一連の言語および推論テストで人間を超えることに成功し、特に数ショットの小規模サンプル学習シナリオで優れたパフォーマンスを発揮しました。 PaLM は、次世代言語モデルの開発方向であると考えられています。同様に、視覚言語モデルは実際に驚くべき働きをしており、モデルの規模を大きくすることでパフォーマンスを向上させることができます。もちろん、それが単なるマルチタスク視覚言語モデルであれば、
 RoSA: 大規模なモデルパラメータを効率的に微調整するための新しい方法
Jan 18, 2024 pm 05:27 PM
RoSA: 大規模なモデルパラメータを効率的に微調整するための新しい方法
Jan 18, 2024 pm 05:27 PM
言語モデルが前例のない規模に拡大するにつれて、下流タスクの包括的な微調整には法外なコストがかかります。この問題を解決するために、研究者はPEFT法に注目し、採用し始めました。 PEFT 手法の主なアイデアは、微調整の範囲を少数のパラメータ セットに制限して、自然言語理解タスクで最先端のパフォーマンスを達成しながら計算コストを削減することです。このようにして、研究者は高いパフォーマンスを維持しながらコンピューティング リソースを節約でき、自然言語処理の分野に新たな研究のホットスポットをもたらします。 RoSA は、一連のベンチマークでの実験を通じて、同じパラメーター バジェットを使用した以前の低ランク適応 (LoRA) および純粋なスパース微調整手法よりも優れたパフォーマンスを発揮することが判明した新しい PEFT 手法です。この記事ではさらに詳しく説明します
 Meta が 650 億のパラメータを持つ大規模言語モデルである AI 言語モデル LLaMA を発表
Apr 14, 2023 pm 06:58 PM
Meta が 650 億のパラメータを持つ大規模言語モデルである AI 言語モデル LLaMA を発表
Apr 14, 2023 pm 06:58 PM
2月25日のニュースによると、Metaは現地時間金曜日、研究コミュニティ向けに人工知能(AI)に基づく新しい大規模言語モデルを立ち上げ、ChatGPTに刺激されたMicrosoft、Google、その他の企業も人工知能に参加すると発表した。 . 知的な競争。 Meta の LLaMA は、「Large Language Model MetaAI」(LargeLanguageModelMetaAI) の略称であり、政府、コミュニティ、学術界の研究者および団体が非営利ライセンスに基づいて利用できます。同社は、基礎となるコードをユーザーが利用できるようにするため、ユーザーはモデルを自分で調整して研究関連のユースケースに使用できるようになります。 Meta 氏は、モデルの計算能力要件について次のように述べています。
 BLOOM は AI 研究の新しい文化を生み出すことができますが、課題はまだ残っています
Apr 09, 2023 pm 04:21 PM
BLOOM は AI 研究の新しい文化を生み出すことができますが、課題はまだ残っています
Apr 09, 2023 pm 04:21 PM
翻訳者 | Li Rui によるレビュー | Sun Shujuan BigScience 研究プロジェクトは最近、大規模言語モデル BLOOM をリリースしましたが、一見すると、OpenAI の GPT-3 をコピーする別の試みのように見えます。しかし、BLOOM が他の大規模自然言語モデル (LLM) と異なる点は、機械学習モデルの研究、開発、トレーニング、リリースへの取り組みです。近年、大手テクノロジー企業は大規模な自然言語モデル (LLM) を厳格な企業秘密のように隠しており、BigScience チームはプロジェクトの開始時から BLOOM の中心に透明性とオープン性を据えてきました。その結果、研究して研究し、誰もが利用できる大規模な言語モデルが誕生しました。 B
