

25平方キロメートルという史上最大規模の再建! NeRF-XL:マルチカード合同トレーニングが実に効果的!

原題: NeRF-XL: Scaling NeRFs with Multiple GPUs
論文リンク: https://research.nvidia.com/labs/toronto-ai/nerfxl/assets/nerfxl.pdf
プロジェクトリンク: https:/ / /research.nvidia.com/labs/toronto-ai/nerfxl/
著者の所属: NVIDIA カリフォルニア大学バークレー校

論文のアイデア:
この論文は、原理である NeRF-XL を提案します。複数のグラフィックス プロセッシング ユニット (GPU) にニューラル レイ フィールド (NeRF) を分散する方法。これにより、任意の大きな容量で NeRF のトレーニングとレンダリングが可能になります。この論文ではまず、大規模なシーンを複数の独立してトレーニングされた NeRF に分解するいくつかの既存の GPU 手法 [9、15、17] をレビューし、トレーニングに追加のコンピューティング リソース (GPU) を使用すると再構成の改善が妨げられる、これらの手法に関するいくつかの基本的な問題を特定します。品質。 NeRF-XL はこれらの問題を解決し、より多くのハードウェアを使用するだけで、任意の数のパラメータを持つ NeRF をトレーニングおよびレンダリングできるようにします。私たちのアプローチの中核は、新しい分散トレーニングとレンダリングの定式化です。これは数学的には古典的な単一 GPU の場合と同等であり、GPU 間の通信を最小限に抑えます。任意の多数のパラメータで NeRF のロックを解除することにより、私たちの方法は NeRF の GPU スケーリング則を初めて明らかにし、パラメータの数が増加するにつれて再構成品質が向上し、使用される GPU の増加に伴って速度が向上することを示しています。この論文は、約 258K の画像を含み、25 平方キロメートルの市街地をカバーする MatrixCity [5] を含む、さまざまなデータセットに対する NeRF-XL の有効性を実証します。
紙のデザイン:
新しい視点合成の最近の進歩により、神経放射場 (NeRF) を捕捉する能力が大幅に向上し、プロセスがよりアクセスしやすくなりました。これらの進歩により、より大きなシーンとその中のより細かいディテールを再構築できるようになります。空間スケールを拡大する (例: 数キロにわたる都市景観をキャプチャする) か、詳細レベルを高める (例: 野原の草の葉をスキャンする) かにかかわらず、キャプチャされたシーンの範囲を広げるには、より多くの情報を NeRF に組み込む必要があります。正確な再構成を実現します。したがって、情報が豊富なシーンの場合、再構築に必要なトレーニング可能なパラメーターの数が 1 つの GPU のメモリ容量を超える可能性があります。
この論文では、複数の GPU 全体にニューラル放射状シーン (NeRF) を効率的に分散するための原則に基づいたアルゴリズムである NeRF-XL を提案します。本記事の手法を利用すれば、ハードウェアリソースを増やすだけで、情報量の多いシーン(大規模かつ高精細なシーンを含む)を撮影できるようになります。 NeRF-XL の中核は、一連の互いに素な空間領域に NeRF パラメータを割り当て、それらを GPU 全体で共同トレーニングすることです。逆方向伝播で勾配を同期する従来の分散トレーニング プロセスとは異なり、私たちの方法では順方向伝播で情報を同期するだけで済みます。さらに、分散設定で方程式と関連する損失項を注意深くレンダリングすることで、GPU 間で必要なデータ転送を大幅に削減します。この斬新な書き換えにより、トレーニングとレンダリングの効率が向上します。この方法の柔軟性とスケーラビリティにより、この記事では複数の GPU を効率的に最適化し、複数の GPU を使用して効率的なパフォーマンスの最適化を行うことができます。
私たちの研究は、独立した立体視 NeRF のセットをトレーニングすることで大規模なシーンをモデル化する GPU アルゴリズムを採用した最近のアプローチとは対照的です [9、15、17]。これらの方法では GPU 間の通信は必要ありませんが、各 NeRF は背景領域を含む空間全体をモデル化する必要があります。これにより、GPU の数が増加するにつれて、モデル容量の冗長性が高まります。さらに、これらの方法ではレンダリング時に NeRF をブレンドする必要があるため、視覚的な品質が低下し、重複領域にアーティファクトが生じます。したがって、NeRF-XL とは異なり、これらの方法はトレーニングでより多くのモデル パラメーター (より多くの GPU に相当) を使用し、視覚的な品質の向上を達成できません。
この論文では、街頭スキャン、ドローン上空飛行、物体中心のビデオなど、さまざまな撮影ケースを通じて私たちのアプローチの有効性を実証しています。ケースの範囲は、小規模なシーン (10 平方メートル) から都市全体 (25 平方キロメートル) まで多岐にわたります。私たちの実験では、より多くのコンピューティング リソースを最適化プロセスに割り当てると、NeRF-XL のビジュアル品質 (PSNR で測定) とレンダリング速度が向上し始めることがわかりました。したがって、NeRF-XL を使用すると、あらゆる空間スケールと詳細のシーンで任意の容量で NeRF をトレーニングすることが可能になります。

図 1: この記事の原理ベースのマルチ GPU 分散トレーニング アルゴリズムは、NeRF を任意の大規模なスケールに拡張できます。

図 2: 独立したトレーニングとマルチ GPU の共同トレーニング。複数の NeRF [9、15、18] を個別にトレーニングするには、各 NeRF が焦点領域とその周囲環境の両方をモデル化する必要があり、これがモデル容量の冗長性につながります。対照的に、私たちの共同トレーニング方法は重複しない NeRF を使用するため、冗長性がありません。
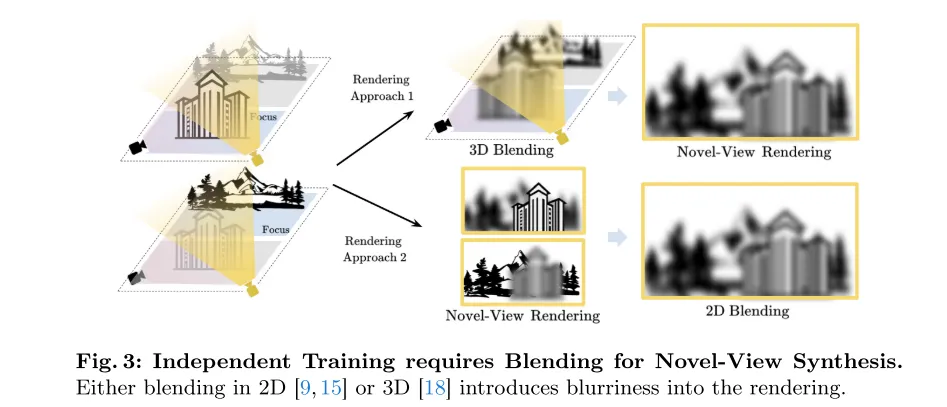
図 3: 独立したトレーニングでは、新しい視点を統合するときにブレンディングが必要です。ブレンディングが 2D [9、15] で実行されるか、3D [18] で実行されるかにかかわらず、レンダリングにブラーが導入されます。
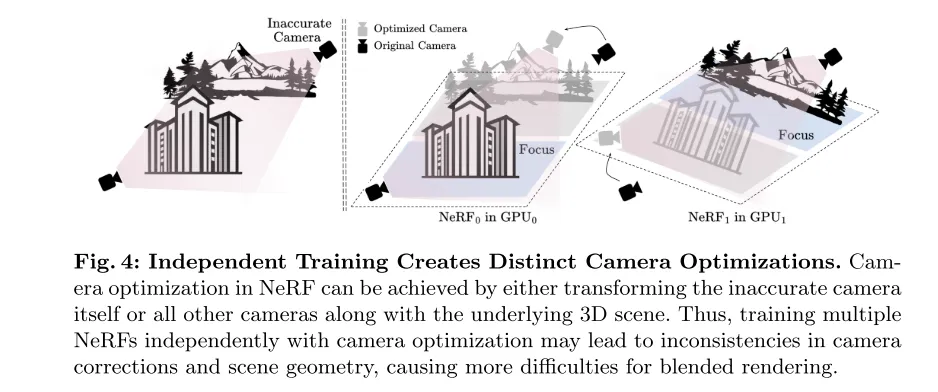
図 4: 独立したトレーニングにより、さまざまなカメラの最適化が行われます。 NeRF では、不正確なカメラ自体、または他のすべてのカメラ、および基礎となる 3D シーンを変換することでカメラの最適化を実現できます。したがって、カメラの最適化とともに複数の NeRF を個別にトレーニングすると、カメラの補正とシーンのジオメトリに不一致が生じる可能性があり、ハイブリッド レンダリングにさらなる困難をもたらします。
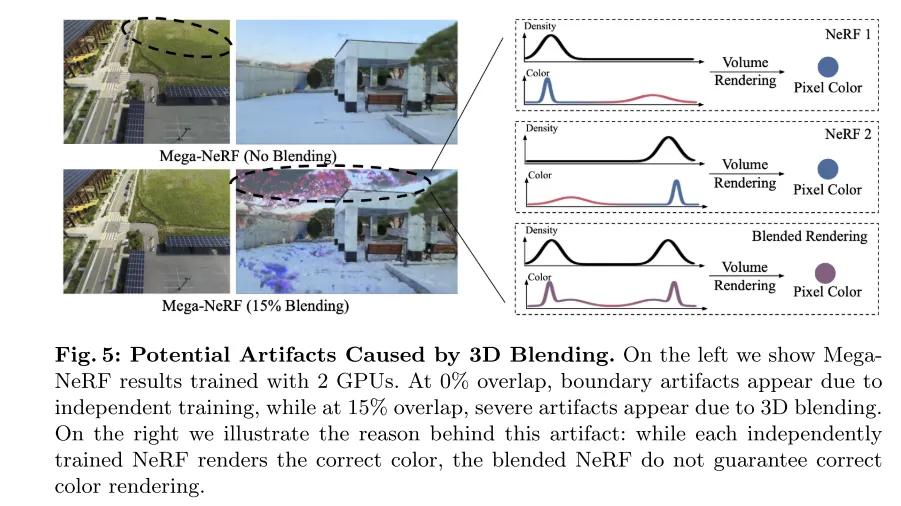
図 5: 3D ブレンドによって発生する可能性のある視覚的なアーティファクト。左側の画像は、2 つの GPU を使用してトレーニングされた MegaNeRF の結果を示しています。 0% オーバーラップでは、独立したトレーニングにより境界にアーティファクトが表示されますが、15% オーバーラップでは、3D ブレンディングにより重大なアーティファクトが表示されます。右側の画像は、このアーティファクトの原因を示しています。独立してトレーニングされた各 NeRF は正しい色をレンダリングしますが、ブレンドされた NeRF は正しい色レンダリングを保証しません。
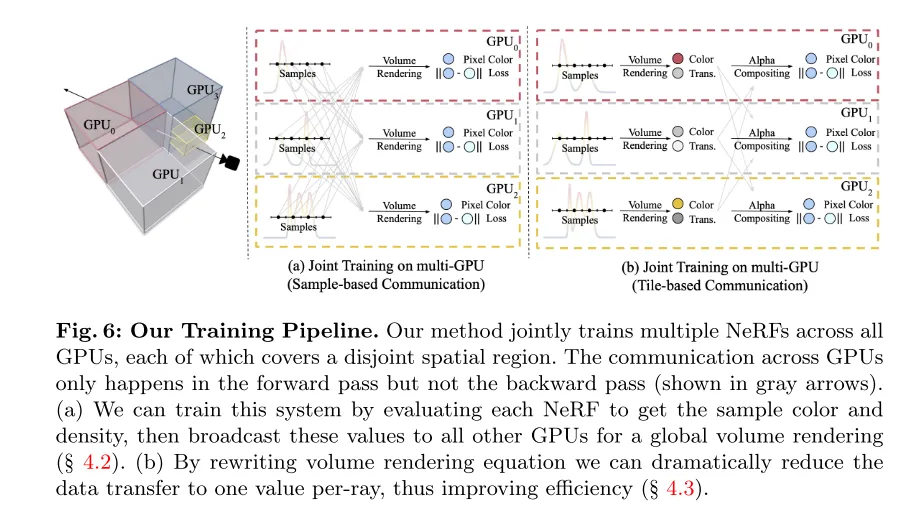
図 6: この記事のトレーニング プロセス。私たちの方法では、すべての GPU 上で複数の NeRF を共同でトレーニングし、各 NeRF が互いに素な空間領域をカバーします。 GPU 間の通信は前方パスでのみ発生し、後方パスでは発生しません (灰色の矢印で示されている)。 (a) この論文は、各 NeRF を評価してサンプルの色と濃度を取得し、これらの値を他のすべての GPU にブロードキャストしてグローバル ボリューム レンダリングを行うことで実装できます (セクション 4.2 を参照)。 (b) ボリューム レンダリング方程式を書き直すことにより、この論文はデータ送信量をレイごとに 1 つの値に大幅に削減し、効率を向上させることができます (セクション 4.3 を参照)。
実験結果:

図 7: 定性的比較。以前の研究と比較して、私たちの方法はマルチ GPU 構成を効果的に活用し、あらゆる種類のデータのパフォーマンスを向上させます。
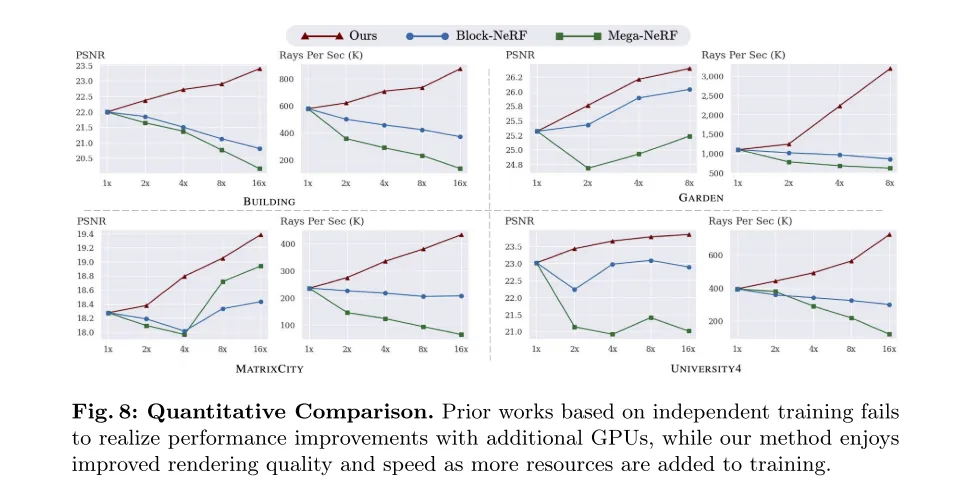
図 8: 定量的な比較。独立したトレーニングに基づいた以前の研究では、追加の GPU を追加してもパフォーマンスの向上を達成できませんでしたが、私たちの方法ではトレーニング リソースが増加するにつれてレンダリングの品質と速度が向上しました。

図 9: この記事のメソッドのスケーラビリティ。 GPU の数が増えると、より多くの学習可能なパラメーターが可能になり、その結果、モデルの容量が増加し、品質が向上します。

図 10: 大規模キャプチャでのその他のレンダリング結果。このペーパーでは、より多くの GPU を使用して、より大規模にキャプチャされたデータ セットに対するメソッドの堅牢性をテストします。これらのデータのビデオ ツアーについては、この記事の Web ページを参照してください。
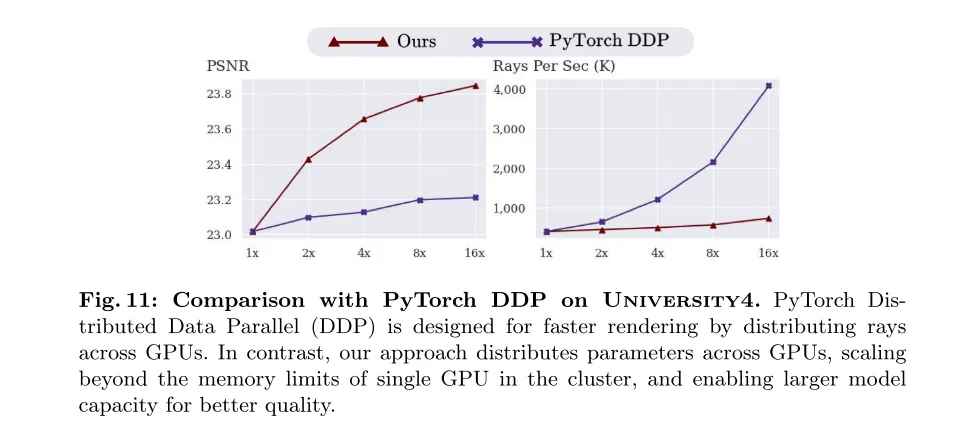
図 11: University4 データセット上の PyTorch DDP との比較。 PyTorch Distributed Data Parallel (DDP) は、GPU 全体に光を分散することでレンダリングを高速化するように設計されています。対照的に、私たちの方法は GPU 全体にパラメータを分散し、クラスター内の単一 GPU のメモリ制限を突破し、モデルの容量を拡張して品質を向上させることができます。
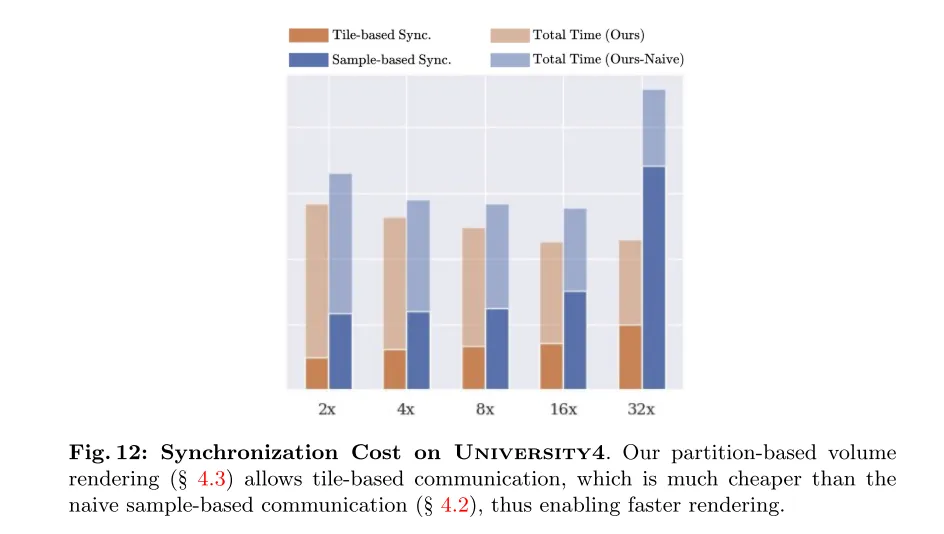
図 12: University4 の同期コスト。パーティションベースのボリューム レンダリング (セクション 4.3 を参照) では、元のサンプルベースの通信 (セクション 4.2 を参照) よりもはるかに安価なタイルベースの通信が可能になるため、より高速なレンダリングが可能になります。
概要:
要約すると、この論文は、大規模なシーンを独立してトレーニングされた NeRF (神経放射場) に分解する既存の方法を再検討し、追加のコンピューティング リソース (GPU) の問題の効果的な利用を妨げる重大な障壁を発見します。これは、マルチ GPU セットアップを活用して大規模な NeRF パフォーマンスを向上させるという中心的な目標に矛盾します。したがって、このホワイト ペーパーでは、マルチ GPU セットアップを効率的に活用し、重複しない複数の NeRF を共同トレーニングすることで、あらゆる規模で NeRF のパフォーマンスを向上できる原則に基づいたアルゴリズムである NeRF-XL を紹介します。重要なのは、私たちの方法はヒューリスティック ルールに依存せず、マルチ GPU 設定で NeRF のスケーリング則に従い、さまざまな種類のデータに適用できることです。
引用:
以上が25平方キロメートルという史上最大規模の再建! NeRF-XL:マルチカード合同トレーニングが実に効果的!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
20
15
1376
52
77
11
18
20

 オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
オープンソース!ゾーイデプスを超えて! DepthFM: 高速かつ正確な単眼深度推定!
Apr 03, 2024 pm 12:04 PM
0.この記事は何をするのですか?私たちは、多用途かつ高速な最先端の生成単眼深度推定モデルである DepthFM を提案します。従来の深度推定タスクに加えて、DepthFM は深度修復などの下流タスクでも最先端の機能を実証します。 DepthFM は効率的で、いくつかの推論ステップ内で深度マップを合成できます。この作品について一緒に読みましょう〜 1. 論文情報タイトル: DepthFM: FastMonocularDepthEstimationwithFlowMatching 著者: MingGui、JohannesS.Fischer、UlrichPrestel、PingchuanMa、Dmytr
 世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
世界で最も強力なオープンソース MoE モデルが登場。GPT-4 に匹敵する中国語機能を備え、価格は GPT-4-Turbo のわずか 1% 近くです
May 07, 2024 pm 04:13 PM
従来のコンピューティングを超える能力を備えているだけでなく、より低コストでより効率的なパフォーマンスを実現する人工知能モデルを想像してみてください。これは SF ではありません。世界で最も強力なオープンソース MoE モデルである DeepSeek-V2[1] が登場しました。 DeepSeek-V2 は、経済的なトレーニングと効率的な推論の特徴を備えた強力な専門家混合 (MoE) 言語モデルです。これは 236B のパラメータで構成されており、そのうち 21B は各マーカーをアクティブにするために使用されます。 DeepSeek67B と比較して、DeepSeek-V2 はパフォーマンスが優れていると同時に、トレーニング コストを 42.5% 節約し、KV キャッシュを 93.3% 削減し、最大生成スループットを 5.76 倍に高めます。 DeepSeek は一般的な人工知能を研究する会社です
 こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
こんにちは、電気アトラスです!ボストン・ダイナミクスのロボットが復活、180度の奇妙な動きにマスク氏も恐怖
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas は正式に電動ロボットの時代に突入します!昨日、油圧式アトラスが歴史の舞台から「涙ながらに」撤退したばかりですが、今日、ボストン・ダイナミクスは電動式アトラスが稼働することを発表しました。ボストン・ダイナミクス社は商用人型ロボットの分野でテスラ社と競争する決意を持っているようだ。新しいビデオが公開されてから、わずか 10 時間ですでに 100 万人以上が視聴しました。古い人が去り、新しい役割が現れるのは歴史的な必然です。今年が人型ロボットの爆発的な年であることは間違いありません。ネットユーザーは「ロボットの進歩により、今年の開会式は人間のように見え、人間よりもはるかに自由度が高い。しかし、これは本当にホラー映画ではないのか?」とコメントした。ビデオの冒頭では、アトラスは仰向けに見えるように地面に静かに横たわっています。次に続くのは驚くべきことです
 MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
MLP に代わる KAN は、オープンソース プロジェクトによって畳み込みまで拡張されました
Jun 01, 2024 pm 10:03 PM
今月初め、MIT やその他の機関の研究者らは、MLP に代わる非常に有望な代替案である KAN を提案しました。 KAN は、精度と解釈可能性の点で MLP よりも優れています。また、非常に少数のパラメーターを使用して、多数のパラメーターを使用して実行する MLP よりも優れたパフォーマンスを発揮できます。たとえば、著者らは、KAN を使用して、より小規模なネットワークと高度な自動化で DeepMind の結果を再現したと述べています。具体的には、DeepMind の MLP には約 300,000 個のパラメーターがありますが、KAN には約 200 個のパラメーターしかありません。 KAN は、MLP が普遍近似定理に基づいているのに対し、KAN はコルモゴロフ-アーノルド表現定理に基づいているのと同様に、強力な数学的基礎を持っています。以下の図に示すように、KAN は
 AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI が数学研究を破壊する!フィールズ賞受賞者で中国系アメリカ人の数学者が上位 11 件の論文を主導 | テレンス・タオが「いいね!」しました
Apr 09, 2024 am 11:52 AM
AI は確かに数学を変えつつあります。最近、この問題に細心の注意を払っている陶哲軒氏が『米国数学協会会報』(米国数学協会会報)の最新号を送ってくれた。 「機械は数学を変えるのか?」というテーマを中心に、多くの数学者が意見を述べ、そのプロセス全体は火花に満ち、ハードコアで刺激的でした。著者には、フィールズ賞受賞者のアクシャイ・ベンカテシュ氏、中国の数学者鄭楽軍氏、ニューヨーク大学のコンピューター科学者アーネスト・デイビス氏、その他業界で著名な学者を含む強力な顔ぶれが揃っている。 AI の世界は劇的に変化しています。これらの記事の多くは 1 年前に投稿されたものです。
 Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
Kuaishou バージョンの Sora「Ke Ling」がテスト用に公開されています。120 秒以上のビデオを生成し、物理学をより深く理解し、複雑な動きを正確にモデル化できます。
Jun 11, 2024 am 09:51 AM
何?ズートピアは国産AIによって実現するのか?ビデオとともに公開されたのは、「Keling」と呼ばれる新しい大規模な国産ビデオ生成モデルです。 Sora も同様の技術的ルートを使用し、自社開発の技術革新を多数組み合わせて、大きく合理的な動きをするだけでなく、物理世界の特性をシミュレートし、強力な概念的結合能力と想像力を備えたビデオを制作します。データによると、Keling は、最大 1080p の解像度で 30fps で最大 2 分の超長時間ビデオの生成をサポートし、複数のアスペクト比をサポートします。もう 1 つの重要な点は、Keling は研究所が公開したデモやビデオ結果のデモンストレーションではなく、ショートビデオ分野のリーダーである Kuaishou が立ち上げた製品レベルのアプリケーションであるということです。さらに、主な焦点は実用的であり、白紙小切手を書かず、リリースされたらすぐにオンラインに移行することです。Ke Ling の大型モデルは Kuaiying でリリースされました。
 超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
超知性の生命力が覚醒する!しかし、自己更新 AI の登場により、母親はデータのボトルネックを心配する必要がなくなりました。
Apr 29, 2024 pm 06:55 PM
世界は狂ったように大きなモデルを構築していますが、インターネット上のデータだけではまったく不十分です。このトレーニング モデルは「ハンガー ゲーム」のようであり、世界中の AI 研究者は、データを貪欲に食べる人たちにどのように餌を与えるかを心配しています。この問題は、マルチモーダル タスクで特に顕著です。何もできなかった当時、中国人民大学学部のスタートアップチームは、独自の新しいモデルを使用して、中国で初めて「モデル生成データフィード自体」を実現しました。さらに、これは理解側と生成側の 2 つの側面からのアプローチであり、両方の側で高品質のマルチモーダルな新しいデータを生成し、モデル自体にデータのフィードバックを提供できます。モデルとは何ですか? Awaker 1.0 は、中関村フォーラムに登場したばかりの大型マルチモーダル モデルです。チームは誰ですか?ソフォンエンジン。人民大学ヒルハウス人工知能大学院の博士課程学生、ガオ・イージャオ氏によって設立されました。
 アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
アメリカ空軍が初のAI戦闘機を公開し注目を集める!大臣はプロセス全体を通じて干渉することなく個人的にテストを実施し、10万行のコードが21回にわたってテストされました。
May 07, 2024 pm 05:00 PM
最近、軍事界は、米軍戦闘機が AI を使用して完全自動空戦を完了できるようになったというニュースに圧倒されました。そう、つい最近、米軍のAI戦闘機が初めて公開され、その謎が明らかになりました。この戦闘機の正式名称は可変安定性飛行シミュレーター試験機(VISTA)で、アメリカ空軍長官が自ら飛行させ、一対一の空戦をシミュレートした。 5 月 2 日、フランク ケンダル米国空軍長官は X-62AVISTA でエドワーズ空軍基地を離陸しました。1 時間の飛行中、すべての飛行動作が AI によって自律的に完了されたことに注目してください。ケンダル氏は「過去数十年にわたり、私たちは自律型空対空戦闘の無限の可能性について考えてきたが、それは常に手の届かないものだと思われてきた」と語った。しかし今では、
