

12 のビデオ理解タスクで、マンバが初めてトランスフォーマーを破りました


このサイトでは学術的、技術的な内容のコラムを公開しています。近年、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com。

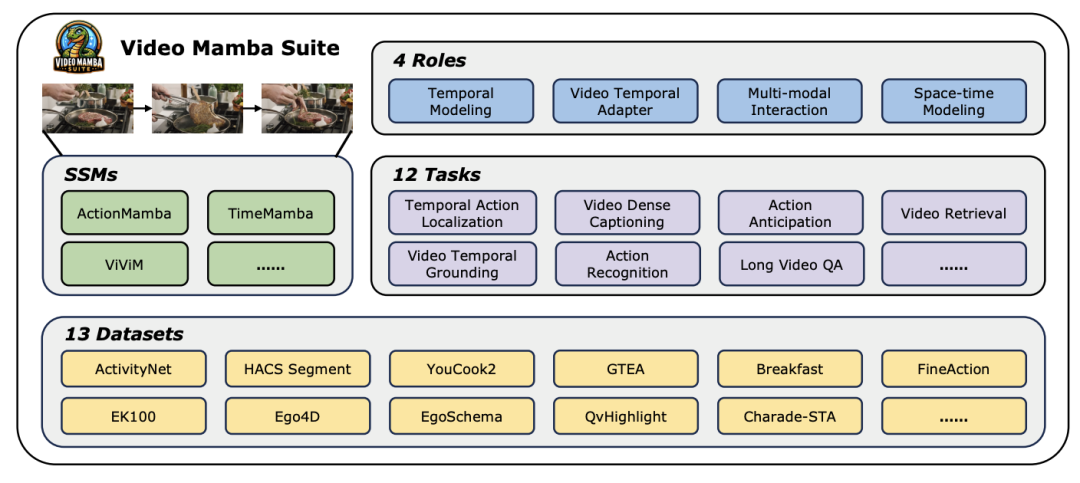
論文タイトル: Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding 論文リンク: https://arxiv.org/abs/2403.09626 コードリンク: https ://github.com/OpenGVLab/video-mamba-suite
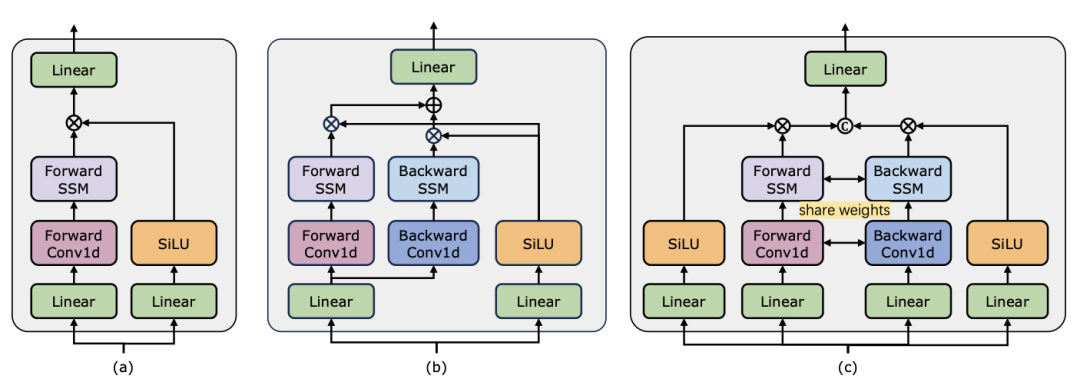
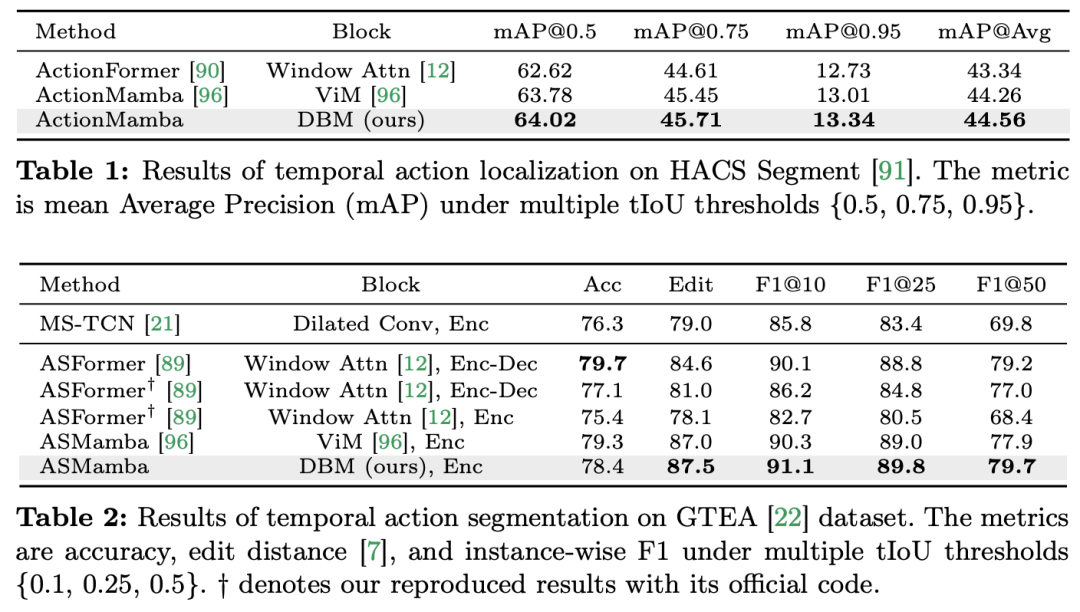
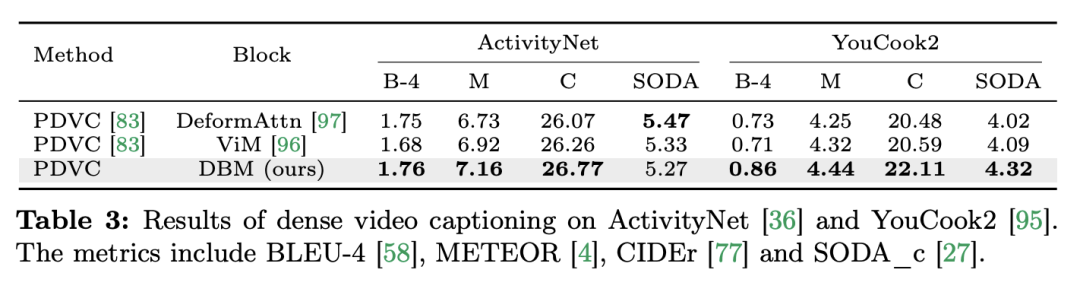
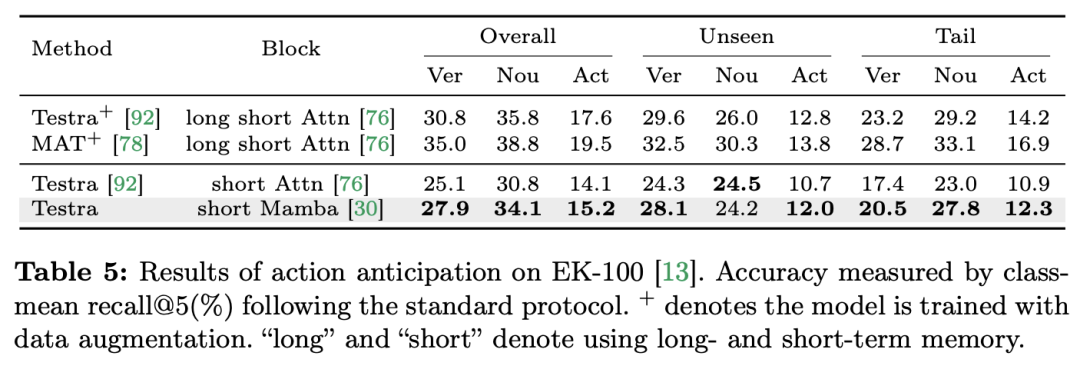
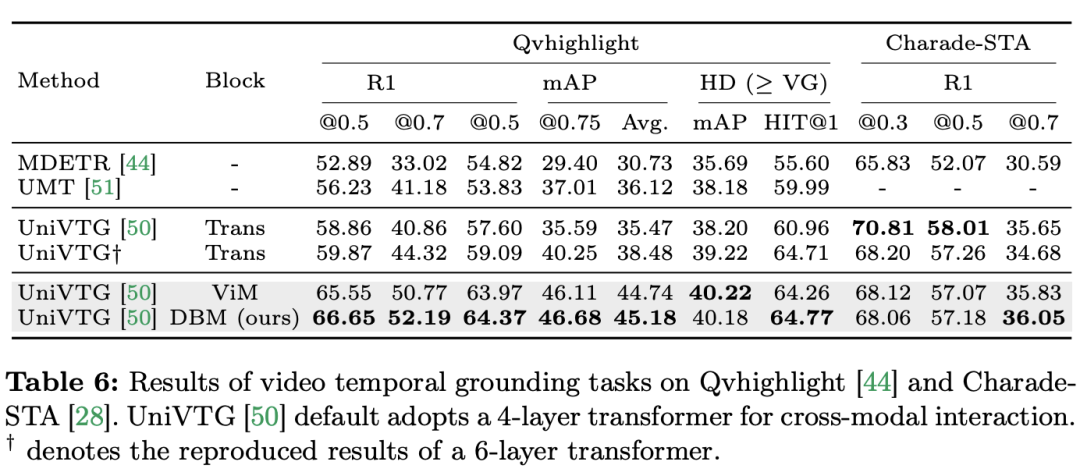

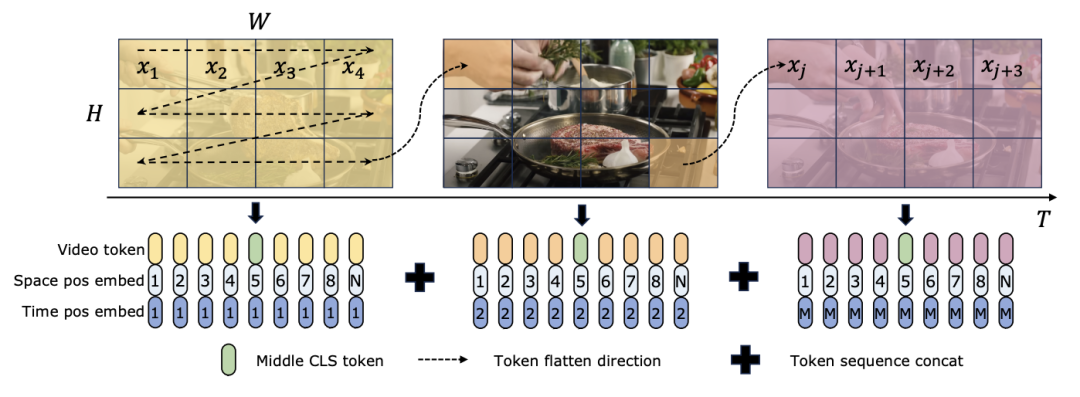
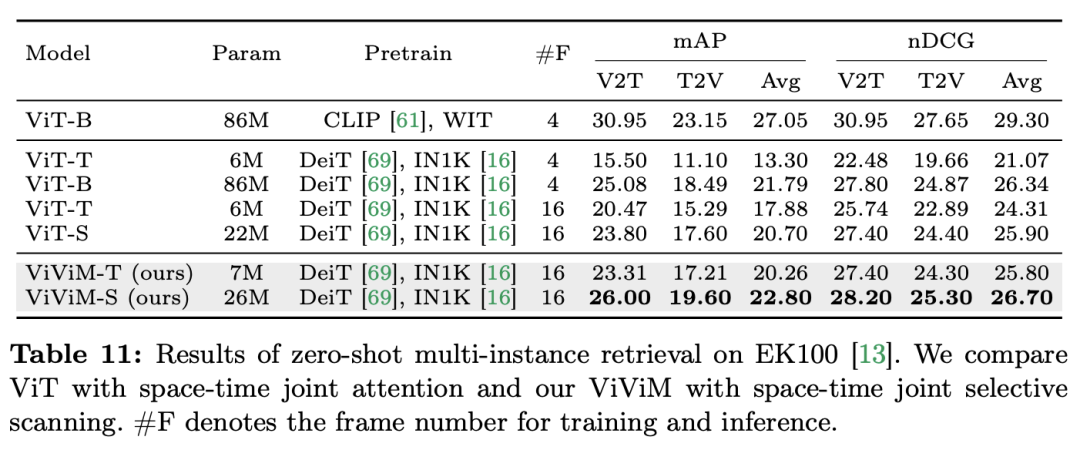
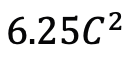 よりわずかに多い) があることは注目に値します (C は特徴次元)。したがって、公平な比較のために、論文では ViM ブロックの拡大率 E を 1 に設定し、パラメーター サイズを
よりわずかに多い) があることは注目に値します (C は特徴次元)。したがって、公平な比較のために、論文では ViM ブロックの拡大率 E を 1 に設定し、パラメーター サイズを 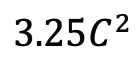 に削減します。 TimeSformer で使用される通常の残留接続形式に加えて、研究チームは Frozen スタイルの適応も検討しました。以下は 5 つのアダプター構造です:
に削減します。 TimeSformer で使用される通常の残留接続形式に加えて、研究チームは Frozen スタイルの適応も検討しました。以下は 5 つのアダプター構造です: 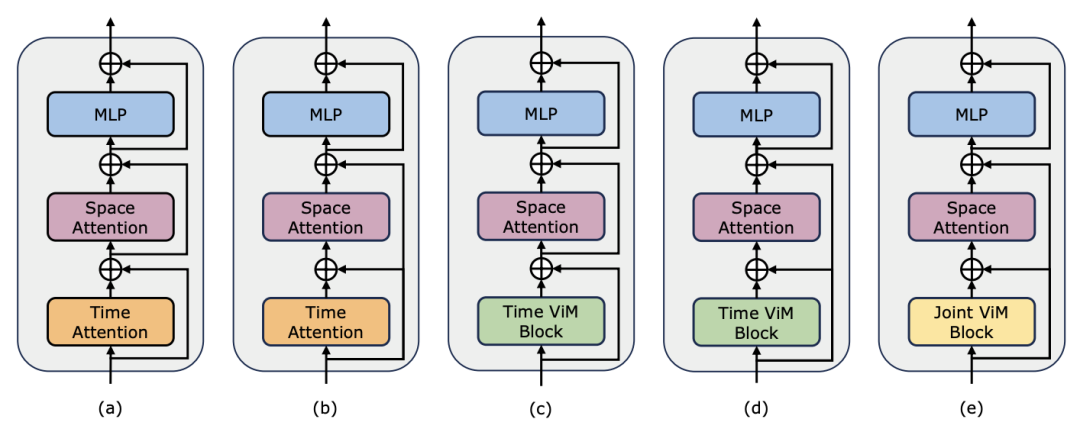
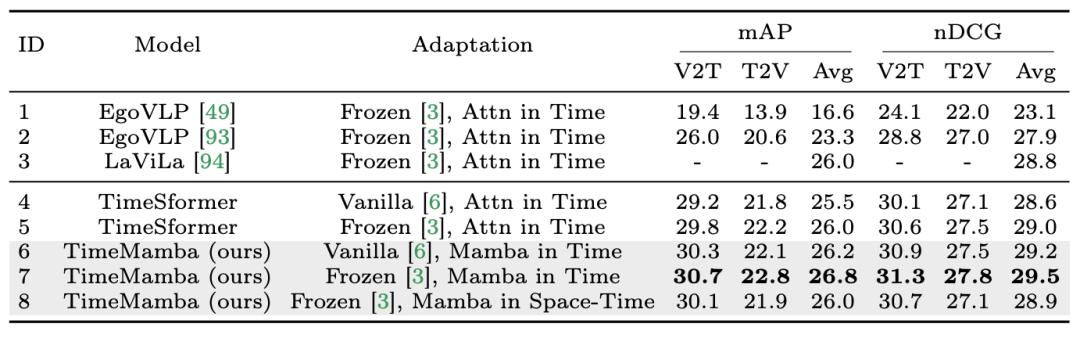
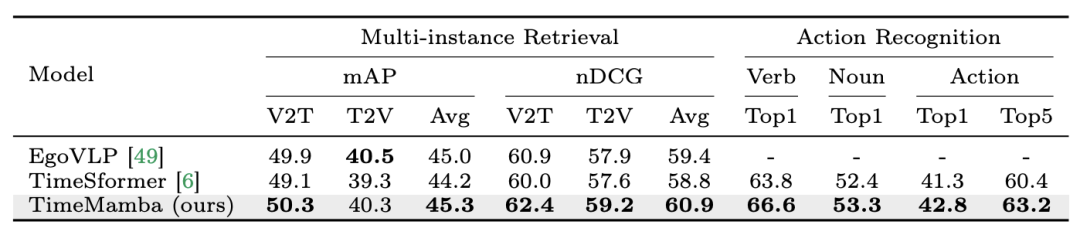
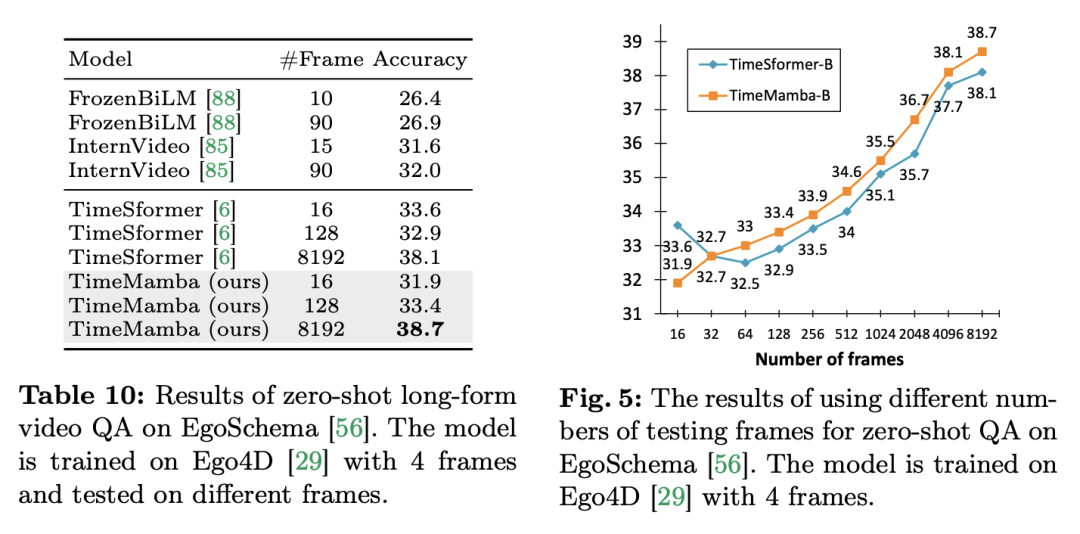
以上が12 のビデオ理解タスクで、マンバが初めてトランスフォーマーを破りましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
20
15
1376
52
77
11
18
20

 Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
GiteEpages静的Webサイトの展開が失敗しました:404エラーのトラブルシューティングと解像度Giteeを使用する
 H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトを実行するには、次の手順が必要です。Webサーバー、node.js、開発ツールなどの必要なツールのインストール。開発環境の構築、プロジェクトフォルダーの作成、プロジェクトの初期化、コードの書き込み。開発サーバーを起動し、コマンドラインを使用してコマンドを実行します。ブラウザでプロジェクトをプレビューし、開発サーバーURLを入力します。プロジェクトの公開、コードの最適化、プロジェクトの展開、Webサーバーの構成のセットアップ。
 H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページは、コードの脆弱性、ブラウザー互換性、パフォーマンスの最適化、セキュリティの更新、ユーザーエクスペリエンスの改善などの要因のため、継続的に維持する必要があります。効果的なメンテナンス方法には、完全なテストシステムの確立、バージョン制御ツールの使用、定期的にページのパフォーマンスの監視、ユーザーフィードバックの収集、メンテナンス計画の策定が含まれます。
 c-subscript 3 subscript 5 c-subscript 3 subscript 5アルゴリズムチュートリアルを計算する方法
Apr 03, 2025 pm 10:33 PM
c-subscript 3 subscript 5 c-subscript 3 subscript 5アルゴリズムチュートリアルを計算する方法
Apr 03, 2025 pm 10:33 PM
C35の計算は、本質的に組み合わせ数学であり、5つの要素のうち3つから選択された組み合わせの数を表します。計算式はC53 = 5です! /(3! * 2!)。これは、ループで直接計算して効率を向上させ、オーバーフローを避けることができます。さらに、組み合わせの性質を理解し、効率的な計算方法をマスターすることは、確率統計、暗号化、アルゴリズム設計などの分野で多くの問題を解決するために重要です。
 WebアノテーションにY軸位置の適応レイアウトを実装する方法は?
Apr 04, 2025 pm 11:30 PM
WebアノテーションにY軸位置の適応レイアウトを実装する方法は?
Apr 04, 2025 pm 11:30 PM
Y軸位置Webアノテーション機能の適応アルゴリズムこの記事では、単語文書と同様の注釈関数、特に注釈間の間隔を扱う方法を実装する方法を探ります...
 ブートストラップ画像の中央でFlexBoxを使用する必要がありますか?
Apr 07, 2025 am 09:06 AM
ブートストラップ画像の中央でFlexBoxを使用する必要がありますか?
Apr 07, 2025 am 09:06 AM
ブートストラップの写真を集中させる方法はたくさんあり、FlexBoxを使用する必要はありません。水平にのみ中心にする必要がある場合、テキスト中心のクラスで十分です。垂直または複数の要素を中央に配置する必要がある場合、FlexBoxまたはグリッドがより適しています。 FlexBoxは互換性が低く、複雑さを高める可能性がありますが、グリッドはより強力で、学習コストが高くなります。メソッドを選択するときは、長所と短所を比較検討し、ニーズと好みに応じて最も適切な方法を選択する必要があります。
 要素UIの隣接する列の高さを自動的にコンテンツに自動的に適応させる方法は?
Apr 05, 2025 am 06:12 AM
要素UIの隣接する列の高さを自動的にコンテンツに自動的に適応させる方法は?
Apr 05, 2025 am 06:12 AM
同じ行の隣接する列の高さを自動的にコンテンツに自動的に適応させる方法は? Webデザインでは、この問題に遭遇することがよくあります。テーブルや列に多くの問題があるとき...
 個別の関数使用距離関数C使用チュートリアル
Apr 03, 2025 pm 10:27 PM
個別の関数使用距離関数C使用チュートリアル
Apr 03, 2025 pm 10:27 PM
std :: uniqueは、コンテナ内の隣接する複製要素を削除し、最後まで動かし、最初の複製要素を指すイテレーターを返します。 STD ::距離は、2つの反復器間の距離、つまり、指す要素の数を計算します。これらの2つの機能は、コードを最適化して効率を改善するのに役立ちますが、隣接する複製要素をstd ::のみ取引するというような、注意すべき落とし穴もあります。 STD ::非ランダムアクセスイテレーターを扱う場合、距離は効率が低くなります。これらの機能とベストプラクティスを習得することにより、これら2つの機能の力を完全に活用できます。
