

ヨガボールの上で「犬」の散歩! NVIDIA のトップ 10 プロジェクトの 1 つに選ばれた Eureka が新たな進歩を遂げました





- 論文アドレス: https://eureka-research.github.io/dr-eureka/assets/dreureka-paper.pdf
- プロジェクトのホームページ: https://github.com/eureka-research/DrEureka
- 論文のタイトル: DrEureka: Language Model Guided Sim-To-Real転送
##ヨガ ボールの歩行タスクは、弾むボールの表面を正確にシミュレートできないため、特に困難です。大きなサイズを簡単に検索できます。多数のシミュレートされた実際の構成を使用して、ロボット犬がさまざまな地形でボールを制御したり、横に歩いたりできるようにします。
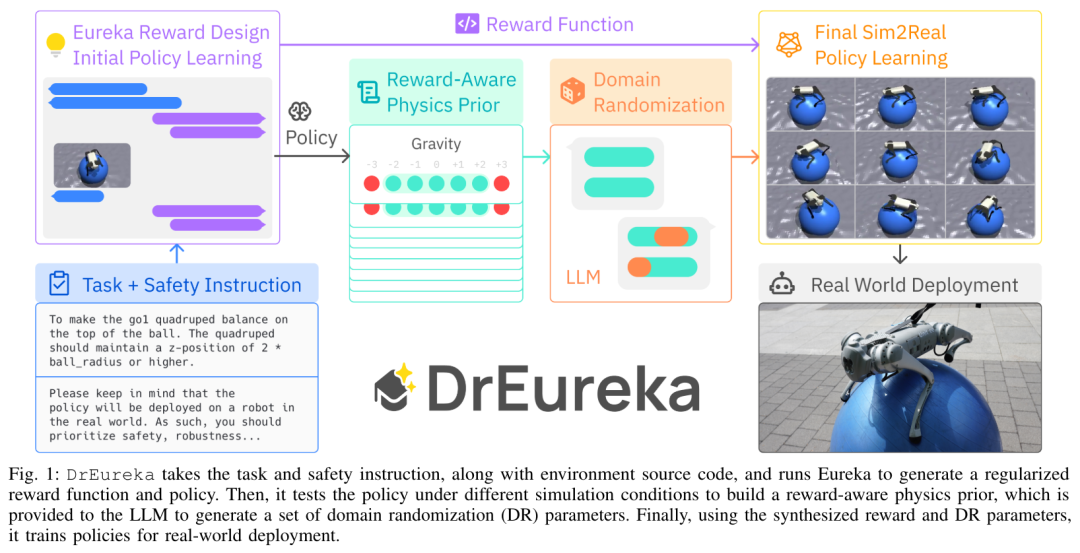




以上がヨガボールの上で「犬」の散歩! NVIDIA のトップ 10 プロジェクトの 1 つに選ばれた Eureka が新たな進歩を遂げましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7692
7692
 15
1639
14
1393
52
1287
25
1229
29
15
1639
14
1393
52
1287
25
1229
29

 Gitプロジェクトをローカルにダウンロードする方法
Apr 17, 2025 pm 04:36 PM
Gitプロジェクトをローカルにダウンロードする方法
Apr 17, 2025 pm 04:36 PM
gitを介してローカルにプロジェクトをダウンロードするには、次の手順に従ってください。gitをインストールします。プロジェクトディレクトリに移動します。次のコマンドを使用してリモートリポジトリのクローニング:git clone https://github.com/username/repository-name.git
 gitでコードを更新する方法
Apr 17, 2025 pm 04:45 PM
gitでコードを更新する方法
Apr 17, 2025 pm 04:45 PM
GITコードを更新する手順:コードをチェックしてください:gitクローンhttps://github.com/username/repo.git最新の変更を取得:gitフェッチマージの変更:gitマージオリジン/マスタープッシュ変更(オプション):gitプッシュオリジンマスター
 gitコミットの使用方法
Apr 17, 2025 pm 03:57 PM
gitコミットの使用方法
Apr 17, 2025 pm 03:57 PM
GITコミットは、プロジェクトの現在の状態のスナップショットを保存するために、ファイルの変更をGITリポジトリに記録するコマンドです。使用方法は次のとおりです。一時的なストレージエリアに変更を追加する簡潔で有益な提出メッセージを書き込み、送信メッセージを保存して終了して送信を完了します。
 Gitダウンロードがアクティブでない場合はどうすればよいですか
Apr 17, 2025 pm 04:54 PM
Gitダウンロードがアクティブでない場合はどうすればよいですか
Apr 17, 2025 pm 04:54 PM
解決:gitのダウンロード速度が遅い場合、次の手順を実行できます。ネットワーク接続を確認し、接続方法を切り替えてみてください。 GIT構成の最適化:ポストバッファーサイズ(Git Config -Global HTTP.Postbuffer 524288000)を増やし、低速制限(GIT Config -Global HTTP.LowsPeedLimit 1000)を減らします。 Gitプロキシ(Git-ProxyやGit-LFS-Proxyなど)を使用します。別のGitクライアント(SourcetreeやGithubデスクトップなど)を使用してみてください。防火を確認してください
 GITでリポジトリを削除する方法
Apr 17, 2025 pm 04:03 PM
GITでリポジトリを削除する方法
Apr 17, 2025 pm 04:03 PM
gitリポジトリを削除するには、次の手順に従ってください。削除するリポジトリを確認します。リポジトリのローカル削除:RM -RFコマンドを使用して、フォルダーを削除します。倉庫をリモートで削除する:倉庫の設定に移動し、「倉庫の削除」オプションを見つけて、操作を確認します。
 gitでコードをマージする方法
Apr 17, 2025 pm 04:39 PM
gitでコードをマージする方法
Apr 17, 2025 pm 04:39 PM
gitコードマージプロセス:競合を避けるために最新の変更を引き出します。マージするブランチに切り替えます。マージを開始し、ブランチをマージするように指定します。競合のマージ(ある場合)を解決します。ステージングとコミットマージ、コミットメッセージを提供します。
 PHPプロジェクトで効率的な検索問題を解決する方法は?タイプセンスはあなたがそれを達成するのに役立ちます!
Apr 17, 2025 pm 08:15 PM
PHPプロジェクトで効率的な検索問題を解決する方法は?タイプセンスはあなたがそれを達成するのに役立ちます!
Apr 17, 2025 pm 08:15 PM
eコマースのウェブサイトを開発するとき、私は困難な問題に遭遇しました:大量の製品データで効率的な検索機能を達成する方法は?従来のデータベース検索は非効率的であり、ユーザーエクスペリエンスが低いです。いくつかの調査の後、私は検索エンジンタイプセンスを発見し、公式のPHPクライアントタイプセンス/タイプセンス-PHPを通じてこの問題を解決し、検索パフォーマンスを大幅に改善しました。
 Gitで空のフォルダーを送信する方法
Apr 17, 2025 pm 04:09 PM
Gitで空のフォルダーを送信する方法
Apr 17, 2025 pm 04:09 PM
GITで空のフォルダーを送信するには、次の手順に従ってください。1。空のフォルダーを作成します。 2.フォルダーをステージング領域に追加します。 3.変更を送信して、コミットメッセージを入力します。 4。(オプション)変更をリモートリポジトリに押します。注:空のフォルダーの名前は開始できません。フォルダーが既に存在する場合は、git addを使用して追加する必要があります。
