

CVPR 2024 | 浙江大学は神経構造化光を利用して動的三次元現象のリアルタイム取得と再構築を実現


AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出電子メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com。
煙などの動的な三次元物理現象を効率的かつ高品質に再構成することは、関連する科学研究において重要な課題であり、空力設計検証、気象三次元観測などの分野で幅広い応用の可能性を秘めています。時間の経過とともに変化する 3 次元の密度シーケンスを集合的に再構成することで、科学者は現実世界のさまざまな複雑な物理現象をより深く理解し、検証できるようになります。

図 1 は、科学研究における動的 3 次元物理現象の観察の重要性を示しています。この写真は、世界最大の風洞施設 NFAC が商用トラックの実体に対して空力実験を行っているところを示しています。
しかし、現実世界で高品質の動的な 3D 密度フィールドを迅速に取得して再構築することは非常に困難です。まず、3 次元情報は、一般的な 2 次元イメージ センサー (カメラなど) を通じて直接測定することが困難です。さらに、高速で変化する動的現象は、物理的取得能力に高い要求を課します。単一の 3 次元密度フィールドの完全なサンプリングを非常に短時間で傍受する必要があり、そうでないと 3 次元密度フィールド自体が変化してしまいます。ここでの基本的な課題は、測定サンプル自体と動的三次元密度場再構成結果との間の情報ギャップをどのように解決するかということです。
現在の主流の研究作業は、測定サンプルの情報不足を補うために事前知識を使用します。事前条件が満たされない場合、計算コストが高く、再構成の品質は低くなります。主流の研究アイデアとは異なり、浙江大学コンピュータ支援設計およびグラフィックスシステム国家重点研究室の研究チームは、問題解決の鍵は単位測定サンプルの情報量を増やすことにあると考えている。研究チームは、AI を使用して再構築アルゴリズムを最適化するだけでなく、同じ目標に基づいて完全に自動化されたソフトウェアとハードウェアの共同最適化を達成するための物理的な収集方法の設計にも AI を使用し、本質的に対象オブジェクトに関する情報量を増加させています。単位測定サンプルにあります。現実世界の物理的な光学現象をシミュレートすることにより、人工知能は構造化光を投影する方法、対応する画像を収集する方法、サンプル ブックから動的 3 次元密度フィールドを再構成する方法を決定できます。最終的に、研究チームは、単一の三次元密度フィールド(空間解像度 128x128x128)をモデル化するための構造化光パターンの数を減らすために、単一のプロジェクターと少数のカメラ(1 つまたは 3 つ)を含む軽量のハードウェア プロトタイプのみを使用しました。から 6 まで、1 秒あたり 40 の 3 次元密度フィールドの効率的な取得セットを実現します。
チームは、デコーダ入力の一部としてローカル入力光を使用し、異なるカメラで撮影された異なるマテリアルの下でデコーダパラメータを共有する、再構築アルゴリズムで軽量な一次元デコーダを革新的に提案し、ネットワークの複雑さを大幅に軽減しました。計算速度を向上させます。異なるカメラのデコード結果を融合するために、単純な構造の3D U-Net融合ネットワークを設計しました。単一の 3 次元密度フィールドの最終的な再構成にかかる時間はわずか 9.2 ミリ秒です。SOTA の研究作業と比較して、再構成速度が 2 ~ 3 桁向上し、3 次元密度フィールドのリアルタイムの高品質な再構成が実現されます。 。関連研究論文「Real-time Acquisition and Reconstruction of Dynamic Volumes with Neural Structured Illumination」が、コンピュータビジョン分野のトップ国際学会であるCVPR 2024に採択されました。

- 研究ホームページ: https://svbrdf.github.io/publications/realtimedynamic/project. html


制御不可能な照明に基づく最初のタイプの作品は、特別な光源を必要とせず、収集プロセス中に照明を制御しないため、収集条件の要件がより緩やかです [2,3]。単視点カメラは 3 次元構造の 2 次元投影をキャプチャするため、異なる 3 次元構造を高品質で区別することは困難です。この点に関して、高密度のカメラ アレイやライト フィールド カメラを使用するなど、収集される視野角サンプルの数を増やすことが 1 つのアイデアですが、これによりハードウェアのコストが高くなります。もう 1 つのアイデアは、パースペクティブ ドメインをまばらにサンプリングし、ヒューリスティック事前分布、物理的ルール、または既存のデータから学習した事前知識など、さまざまな種類の事前情報を通じて情報ギャップを埋めることです。実際に先験的な条件が満たされなくなると、このタイプの方法の再構成結果の品質が低下します。さらに、リアルタイムの再構成をサポートするには計算オーバーヘッドが高すぎます。
2 番目のタイプの作業では、制御可能な照明を使用して、収集プロセス中に照明条件をアクティブに制御します [4,5]。このような作業では、物理世界をより積極的に調査するために照明をエンコードし、事前分布への依存も少なくなり、その結果、再構築の品質が向上します。単一のランプを使用するか複数のランプを同時に使用するかに応じて、関連する作業はさらにスキャン方式と照明多重方式に分類できます。動的な物理オブジェクトの場合、前者は高価なハードウェアを使用して高速スキャンを達成するか、取得の負担を軽減するために結果の整合性を犠牲にする必要があります。後者は、複数の光源を同時にプログラムすることで収集効率を大幅に向上させます。ただし、高品質で高速なリアルタイム密度フィールドの場合、既存の方法のサンプリング効率はまだ不十分です [5]。
浙江大学チームの作品は第二カテゴリーに属します。既存のほとんどの研究とは異なり、この研究研究は人工知能を使用して物理的取得 (つまり、神経構造化光) と計算による再構成を共同で最適化し、それによって効率的で高品質な動的 3 次元密度場モデリングを実現します。
ハードウェアプロトタイプ
研究チームは、1 台の商用プロジェクター (BenQ X3000: 解像度 1920×1080、速度 240fps) と 3 台の産業用カメラ (Basler acA1440-220umQGR: 解像度 1440×1080、速度 240fps) を構築しました。 シンプルなハードウェア プロトタイプ(図 3 を参照)。 6 つの事前トレーニングされた構造化光パターンがプロジェクターを通じて周期的に投影され、3 台のカメラが同時に撮影し、カメラによって収集された画像に基づいて動的 3 次元密度フィールド再構成が実行されます。収集オブジェクトに対する 4 つのデバイスの角度は、さまざまなシミュレーション実験からのシミュレーション後に選択された最適な配置です。
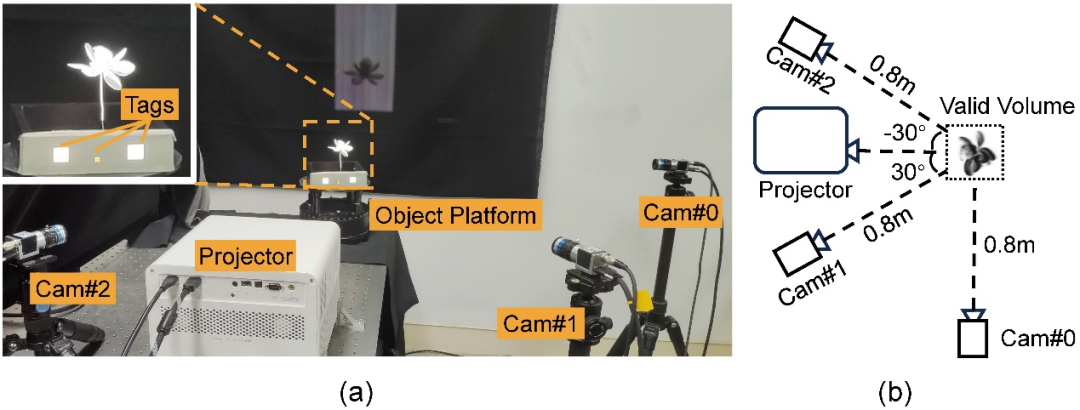
図 3: コレクション ハードウェアのプロトタイプ。 (a) ハードウェア プロトタイプの実際のショット。カメラとプロジェクターを同期するために使用されるステージ上の 3 つの白いタグがあります。 (b) カメラ、プロジェクター、被写体の間の幾何学的関係の概略図 (上面図)。
ソフトウェア処理
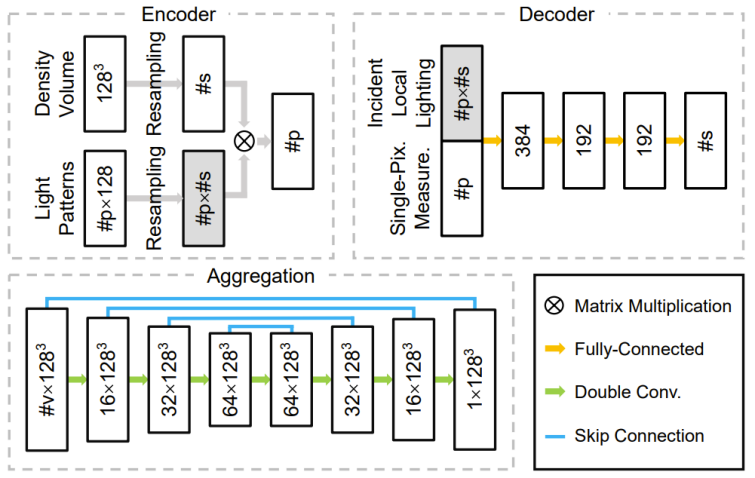
研究開発チームは、エンコーダー、デコーダー、集約モジュールで構成されるディープ ニューラル ネットワークを設計します。エンコーダの重みは、取得中の構造化された光強度分布に直接対応します。デコーダは、単一ピクセルで測定されたサンプルを入力として受け取り、1 次元の密度分布を予測し、それを 3 次元の密度フィールドに補間します。集約モジュールは、各カメラに対応するデコーダによって予測された複数の 3 次元密度フィールドを最終結果に結合します。この研究では、トレーニング可能な構造化光と軽量の 1 次元デコーダを使用することで、構造化光パターン、2 次元写真、3 次元密度フィールドの間の本質的な関係をより簡単に学習できるため、トレーニング データにオーバーフィットする可能性が低くなります。 。以下の図 4 はパイプライン全体を示し、図 5 は関連するネットワーク構造を示します。

図 4: グローバル取得および再構成パイプライン (a)、および構造化光パターンから 1D 局所入射光への再処理 (b)、および予測された 1D 密度分布から 3D 密度場への再処理 (c)サンプリングプロセス。研究は、シミュレーションされた/実際の 3 次元密度フィールドから始まり、事前に最適化された構造化光パターン (つまり、エンコーダー内の重み) が最初に投影されます。各カメラビューの有効なピクセルごとに、そのすべての測定値とリサンプリングされた局所入射光がデコーダーに供給され、対応するカメラ光線上の 1 次元密度分布が予測されます。次に、1 台のカメラからのすべての密度分布が収集され、単一の 3 次元密度フィールドにリサンプリングされます。マルチカメラの場合、この研究では各カメラの予測された密度フィールドを融合して最終結果を取得します。図 5: ネットワークの 3 つの主要コンポーネント (エンコーダ、デコーダ、集約モジュール) のアーキテクチャ。
 結果表示
結果表示
図 6 は、4 つの異なる動的シーンに対するこの方法の部分再構成結果を示しています。動的な水ミストを生成するために、研究者らは液体の水が入ったボトルにドライアイスを加えて水ミストを生成し、バルブを通る流れを制御し、ゴムチューブを使って水ミストをさらに収集装置に導きました。 図 6: さまざまな動的シーンの再構成結果。各行は、特定の水霧シーケンス内の再構成されたフレームの選択された部分の視覚化結果です。シーン内の水霧ソースの数は上から下にそれぞれ 1、1、3、2 です。左上のオレンジ色のマークに示すように、A、B、C はそれぞれ 3 台の入力カメラで収集された画像に対応し、D は再構成結果のレンダリング視点と同様の実撮影参照画像です。タイムスタンプは左下隅に表示されます。詳細な動的再構成結果については、論文ビデオを参照してください。 この研究の正確さと品質を検証するために、研究チームはこの手法を実際の静的オブジェクトに対する関連する SOTA 手法と比較しました (図 7 を参照)。図 7 では、さまざまなカメラ番号での再構成の品質も比較しています。すべての再構成結果は、同じ新しい未取得の視点の下でプロットされ、3 つの評価指標によって定量的に評価されます。図 7 からわかるように、取得効率の最適化のおかげで、この方法の再構成品質は SOTA 方法よりも優れています。 図 7: 実際の静的オブジェクトに対するさまざまな手法の比較。左から右へ、光学層切断方法 [4]、この方法 (3 台のカメラ)、この方法 (ダブル カメラ)、この方法 (シングル カメラ)、単一カメラの下で手動で設計された構造化光を使用する [5]、SOTA の方法です。 PINF [3] および GlobalTrans [2] メソッドの再構成結果の視覚化。光学スライスの結果をベンチマークとして採用し、他のすべての結果の定量的誤差は、対応する画像の右下隅にリストされ、3 つの指標 SSIM/PSNR/RMSE (×0.01) で評価されます。再構成されたすべての密度フィールドは非入力ビューを使用してレンダリングされます。#v は取得されたビューの数を表し、#p は使用された構造化光パターンの数を表します。 研究チームはまた、動的シミュレーションデータに対するさまざまな方法の再構成品質を定量的に比較しました。図 8 は、シミュレートされた煙シーケンスの再構成品質の比較を示しています。フレームごとの再構成結果の詳細については、論文ビデオを参照してください。 図 8: シミュレートされた煙シーケンスにおけるさまざまな方法の比較。左から右へ、実際の値、この方法の再構成結果、PINF [3]、GlobalTrans [2] です。入力ビューと新しいビューのレンダリング結果がそれぞれ 1 行目と 2 行目に表示されます。定量的誤差 SSIM/PSNR/RMSE (×0.01) は、対応する画像の右下隅に示されています。再構成されたシーケンス全体の平均誤差については、論文の補足資料を参照してください。また、シーケンス全体の動的再構成結果については論文ビデオをご覧ください。 将来の展望 研究チームは、この方法をより高度な取得装置(ライトフィールドプロジェクター[6]など)に適用して、動的取得再構成を実行することを計画しています。研究チームはまた、より豊富な光学情報(偏光状態など)を収集することで、収集に必要な構造化光パターンとカメラの数をさらに削減したいと考えています。さらに、この手法をニューラル表現 (NeRF など) と組み合わせるのも、チームが興味を持っている将来の開発方向の 1 つです。最後に、後処理ソフトウェアに限定されず、AI が物理的取得と計算による再構成の設計にさらに積極的に関与できるようにすることで、物理的知覚能力をさらに向上させるための新しいアイデアが提供され、最終的にはさまざまなオブジェクトの効率的かつ高品質なモデリングが達成される可能性があります。複雑な物理現象。 参考: [1]。世界最大の風洞の内部 https://youtu.be/ubyxYHFv2qw?si=KK994cXtARP3Atwn [2]。フランツ、バーバラ・ソレンターラー、Nils Thuerey、CVPR の 1632 ~ 1642 ページ、2021 年。Mengyu Chu、Lingjie Liu、Quan Zheng、Erik Franz、HansPeter Seidel、Christian。 Thebalt、Rhaleb Zayer、スパース データを使用した煙の再構築のための物理学、ACM Transactions on Graphics、2022 年 [4]。 Paul Debevec、ACM Transactions on Graphics、24 (3):812–815、2005. [5]。 Belhumeur、Ravi Ramamoorthi、不均質な参加メディアを回復するための圧縮構造化光、パターン分析とマシン インテリジェンスに関する IEEE トランザクション、35 (3):1–1、2013 年。Xianmin Xu、Yuxin。 Lin、Haoyang Zhou、Chong Zeng、Yaxin Yu、Kun Zhou、Hongzhi Wu。形状と反射率を単一ビューで取得するための統合された空間角度構造化光、CVPR、206 ~ 215 ページ。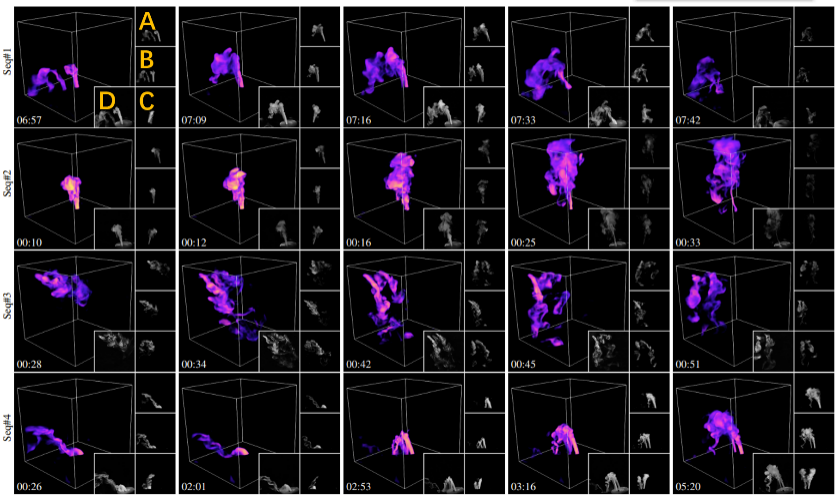


以上がCVPR 2024 | 浙江大学は神経構造化光を利用して動的三次元現象のリアルタイム取得と再構築を実現の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 Gitプロジェクトをローカルにダウンロードする方法
Apr 17, 2025 pm 04:36 PM
Gitプロジェクトをローカルにダウンロードする方法
Apr 17, 2025 pm 04:36 PM
gitを介してローカルにプロジェクトをダウンロードするには、次の手順に従ってください。gitをインストールします。プロジェクトディレクトリに移動します。次のコマンドを使用してリモートリポジトリのクローニング:git clone https://github.com/username/repository-name.git
 gitでコードを更新する方法
Apr 17, 2025 pm 04:45 PM
gitでコードを更新する方法
Apr 17, 2025 pm 04:45 PM
GITコードを更新する手順:コードをチェックしてください:gitクローンhttps://github.com/username/repo.git最新の変更を取得:gitフェッチマージの変更:gitマージオリジン/マスタープッシュ変更(オプション):gitプッシュオリジンマスター
 gitでコードをマージする方法
Apr 17, 2025 pm 04:39 PM
gitでコードをマージする方法
Apr 17, 2025 pm 04:39 PM
gitコードマージプロセス:競合を避けるために最新の変更を引き出します。マージするブランチに切り替えます。マージを開始し、ブランチをマージするように指定します。競合のマージ(ある場合)を解決します。ステージングとコミットマージ、コミットメッセージを提供します。
 PHPプロジェクトで効率的な検索問題を解決する方法は?タイプセンスはあなたがそれを達成するのに役立ちます!
Apr 17, 2025 pm 08:15 PM
PHPプロジェクトで効率的な検索問題を解決する方法は?タイプセンスはあなたがそれを達成するのに役立ちます!
Apr 17, 2025 pm 08:15 PM
eコマースのウェブサイトを開発するとき、私は困難な問題に遭遇しました:大量の製品データで効率的な検索機能を達成する方法は?従来のデータベース検索は非効率的であり、ユーザーエクスペリエンスが低いです。いくつかの調査の後、私は検索エンジンタイプセンスを発見し、公式のPHPクライアントタイプセンス/タイプセンス-PHPを通じてこの問題を解決し、検索パフォーマンスを大幅に改善しました。
 Gitダウンロードがアクティブでない場合はどうすればよいですか
Apr 17, 2025 pm 04:54 PM
Gitダウンロードがアクティブでない場合はどうすればよいですか
Apr 17, 2025 pm 04:54 PM
解決:gitのダウンロード速度が遅い場合、次の手順を実行できます。ネットワーク接続を確認し、接続方法を切り替えてみてください。 GIT構成の最適化:ポストバッファーサイズ(Git Config -Global HTTP.Postbuffer 524288000)を増やし、低速制限(GIT Config -Global HTTP.LowsPeedLimit 1000)を減らします。 Gitプロキシ(Git-ProxyやGit-LFS-Proxyなど)を使用します。別のGitクライアント(SourcetreeやGithubデスクトップなど)を使用してみてください。防火を確認してください
 gitコミットの使用方法
Apr 17, 2025 pm 03:57 PM
gitコミットの使用方法
Apr 17, 2025 pm 03:57 PM
GITコミットは、プロジェクトの現在の状態のスナップショットを保存するために、ファイルの変更をGITリポジトリに記録するコマンドです。使用方法は次のとおりです。一時的なストレージエリアに変更を追加する簡潔で有益な提出メッセージを書き込み、送信メッセージを保存して終了して送信を完了します。
 Gitでローカルコードを更新する方法
Apr 17, 2025 pm 04:48 PM
Gitでローカルコードを更新する方法
Apr 17, 2025 pm 04:48 PM
ローカルGitコードを更新する方法は? Git Fetchを使用して、リモートリポジトリから最新の変更を引き出します。 Git Merge Origin/<リモートブランチ名>を使用して、地元のブランチへのリモート変更をマージします。合併から生じる競合を解決します。 Git Commit -M "Merge Branch< Remote Branch Name>"を使用してください。マージの変更を送信し、更新を適用します。
 GITでリポジトリを削除する方法
Apr 17, 2025 pm 04:03 PM
GITでリポジトリを削除する方法
Apr 17, 2025 pm 04:03 PM
gitリポジトリを削除するには、次の手順に従ってください。削除するリポジトリを確認します。リポジトリのローカル削除:RM -RFコマンドを使用して、フォルダーを削除します。倉庫をリモートで削除する:倉庫の設定に移動し、「倉庫の削除」オプションを見つけて、操作を確認します。
