

ルカンが月に? Nankai と Byte が StoryDiffusion をオープンソース化、複数枚の漫画や長いビデオをより一貫性のあるものにする

2日前、チューリング賞受賞者のヤン・ルカン氏が長編漫画「月に行って自分自身を探検しよう」を再版し、ネチズンの間で熱い議論を巻き起こした。

論文「ストーリー拡散: 長距離画像およびビデオ生成のための一貫した自己注意」の中で、研究チームはストーリーと呼ばれる手法を提案しました。複雑な状況を描写する一貫した画像とビデオを生成するための Diffusion の新しいアプローチ。これらの漫画に関する研究は、南開大学やバイトダンスなどの機関によって行われています。

- 論文アドレス: https://arxiv.org/pdf/2405.01434v1 #プロジェクトのホームページ: https://storydiffusion.github.io/
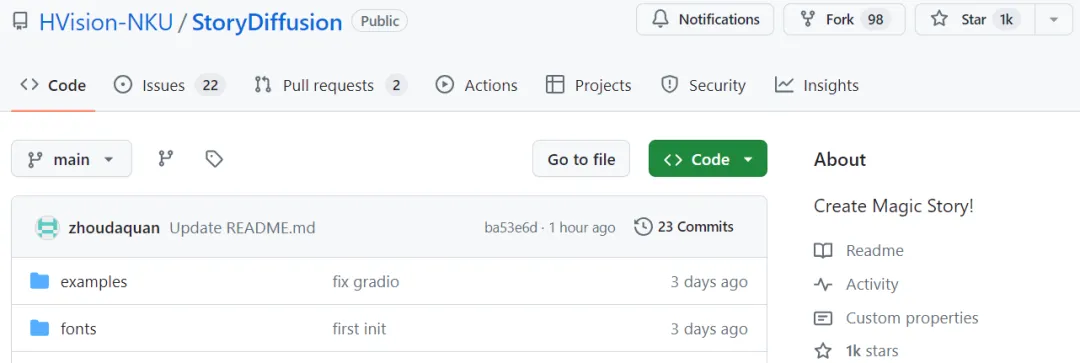
Basedプロジェクトのデモンストレーションでは、StoryDiffusion はさまざまなスタイルのコミックを生成し、キャラクターのスタイルや服装の一貫性を維持しながら一貫したストーリーを伝えることができます。
 #StoryDiffusion は、複数のキャラクターのアイデンティティを同時に維持し、一連の画像にわたって一貫したキャラクターを生成できます。
#StoryDiffusion は、複数のキャラクターのアイデンティティを同時に維持し、一連の画像にわたって一貫したキャラクターを生成できます。
 さらに、StoryDiffusion は、生成された一貫した画像またはユーザーが入力した画像に基づいて高品質のビデオを生成できます。
さらに、StoryDiffusion は、生成された一貫した画像またはユーザーが入力した画像に基づいて高品質のビデオを生成できます。

 #拡散ベースの生成モデルの場合、生成された一連の画像でコンテンツの一貫性を維持する方法を知っています。 、特に複雑なテーマや詳細を含む画像は、大きな課題です。
#拡散ベースの生成モデルの場合、生成された一連の画像でコンテンツの一貫性を維持する方法を知っています。 、特に複雑なテーマや詳細を含む画像は、大きな課題です。
そこで研究チームは、画像生成時にバッチを確立することで、画像間のつながりを確立するという、新しいセルフアテンション計算手法を提案しました。文字の一貫性を維持するために画像内の要素が維持され、トレーニングなしでテーマ的に一貫した画像を生成できます。
この方法を長いビデオ生成に拡張するために、研究チームは、画像を意味空間にエンコードし、意味空間内の動きを予測するセマンティック動き予測器 (Semantic Motion Predictor) を導入しました。モーションを使用してビデオを生成します。これは、潜在空間のみに基づく動き予測よりも安定しています。
次に、フレームワークの統合を実行し、一貫した自己注意とセマンティック モーション予測子を組み合わせて、一貫したビデオを生成し、複雑なストーリーを伝えます。 StoryDiffusion は、既存の方法よりもスムーズで一貫性のあるビデオを生成できます。
#図 1: チームの StroyDiffusion によって生成された画像とビデオ
手法の概要
研究チームの方法は、図 2 と 3 に示すように 2 つの段階に分けることができます。
最初の段階では、StoryDiffusion は Consistent Self-Attention を使用して、トレーニング不要の方法でトピックに一貫性のある画像を生成します。これらの一貫した画像は、ストーリーテリングで直接使用することも、第 2 段階への入力として使用することもできます。第 2 段階では、StoryDiffusion はこれらの一貫した画像に基づいて一貫したトランジション ビデオを作成します。
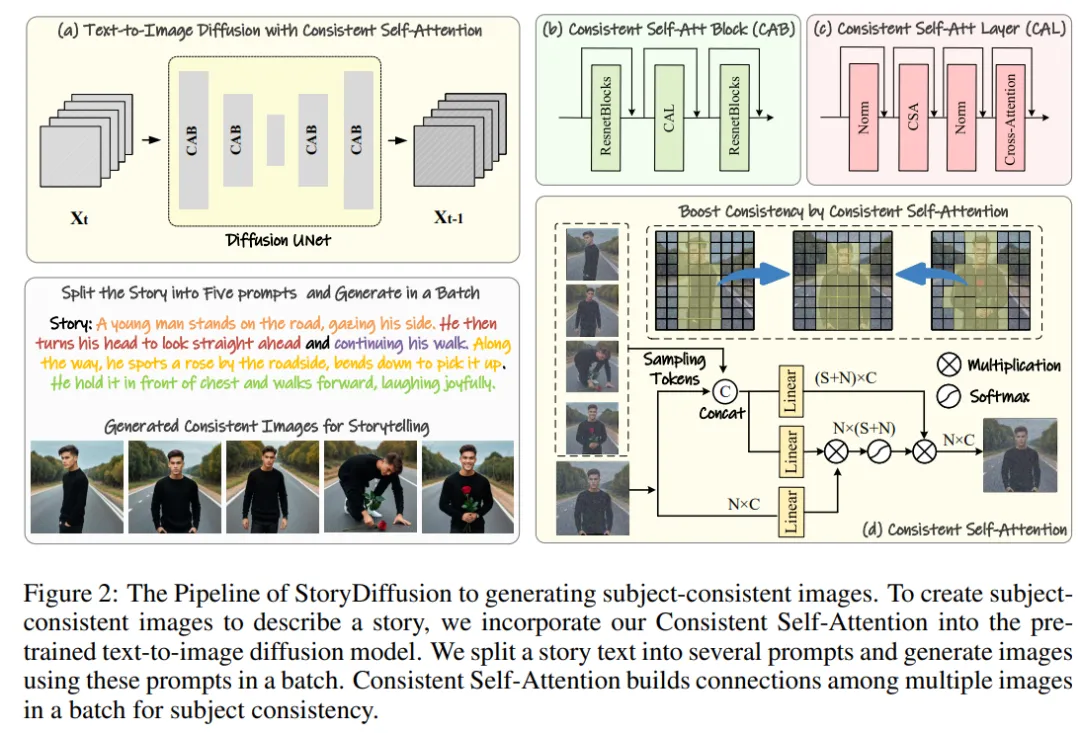
#図 2: テーマに一貫した画像を生成するための StoryDiffusion プロセスの概要
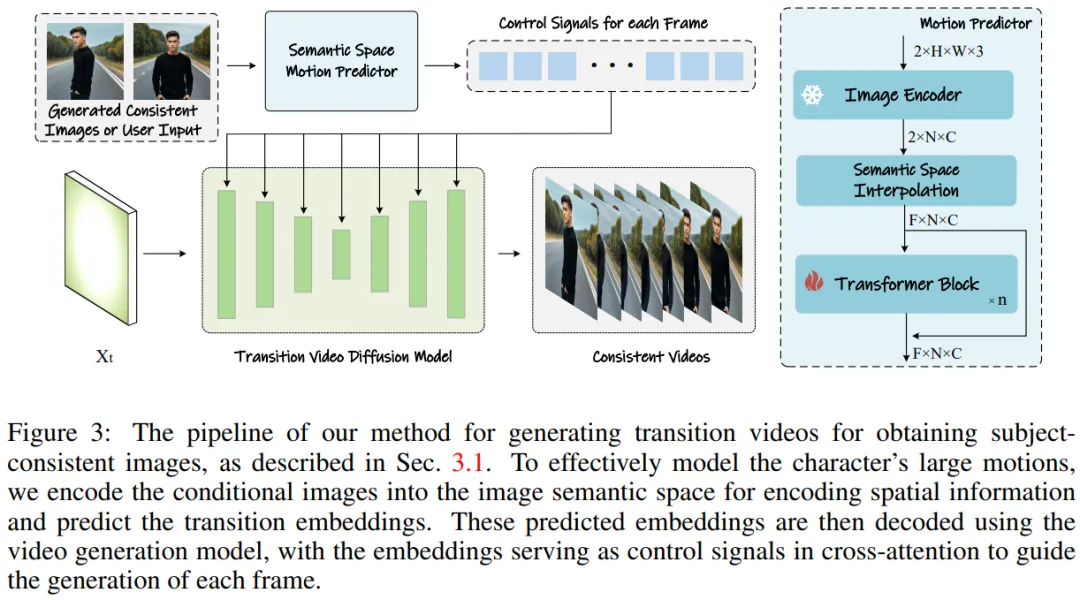 図 3: 取得するトランジション ビデオの生成テーマ的に一貫した画像へのアプローチ。
図 3: 取得するトランジション ビデオの生成テーマ的に一貫した画像へのアプローチ。
トレーニングなしで一貫した画像生成
研究チームは、「トレーニングなしでテーマ的に一貫した画像を生成する方法」という手法を紹介しました。上記の問題を解決する鍵は、画像のバッチ内の文字の一貫性をどのように維持するかです。これは、生成プロセス中に、イメージのバッチ間の接続を確立する必要があることを意味します。
拡散モデルにおけるさまざまな注意メカニズムの役割を再検討した後、彼らは、画像のバッチ内で画像の一貫性を維持するために自己注意を使用する方法を探求するようインスピレーションを受け、次のことを提案しました。一貫した自己注意。
研究チームは、既存の画像生成モデルの U-Net アーキテクチャ内の元の自己注意の位置に一貫した自己注意を挿入し、元の自己注意の重みを再利用しました。トレーニング不要でプラグアンドプレイの性質を維持します。
研究チームの手法は、ペアのトークンを与えられると、一連の画像に対してセルフアテンションを実行し、異なる画像の特徴間の相互作用を促進します。このタイプのインタラクションにより、生成中にモデルのキャラクター、顔、服装の収束が促進されます。一貫した自己注意の方法はシンプルでトレーニングを必要としませんが、テーマ的に一貫した画像を効果的に生成できます。
より明確に説明するために、研究チームはアルゴリズム 1 の疑似コードを示しています。

ビデオ生成のためのセマンティック モーション プレディクター
研究チーム A セマンティック モーションPredictor が提案されており、画像を画像意味空間にエンコードして空間情報を取得し、それによって特定の開始フレームと終了フレームからより正確な動き予測を実現します。
より具体的には、チームによって提案されたセマンティック動き予測器では、最初に関数 E を使用して、RGB 画像から画像のセマンティック空間ベクトルへのマッピングが確立されます。情報はエンコードされます。
チームは、線形層を関数 E として直接使用しませんでした。代わりに、事前トレーニングされた CLIP 画像エンコーダーを関数 E として使用して、ゼロ サンプル (ゼロ) を活用しました。 - ショット)パフォーマンスを向上させる機能。
関数 E を使用して、指定された開始フレーム F_s と終了フレーム F_e が画像意味空間ベクトル K_s と K_e に圧縮されます。

実験結果
主題に一貫した画像を生成するという点では、チームの方法では何も必要ありません。これはプラグアンドプレイなので、Stable Diffusion XL と Stable Diffusion 1.5 の両方のバージョンにこのメソッドが実装されています。比較したモデルと一貫性を保つために、Stable-XL モデルで同じ事前トレーニング済みの重みを比較に使用しました。
一貫したビデオを生成するために、研究者らは Stable Diffusion 1.5 特化モデルに基づいた研究手法を実装し、ビデオ生成をサポートする事前トレーニング済みの時間モジュールを統合しました。比較されたすべてのモデルは、7.5 の分類子なしのガイダンス スコアと 50 ステップの DDIM サンプリングを使用します。
一貫性イメージ生成の比較
チームは、2 つの最新の ID 保存方法である IP を使用してこれを達成しました。 - アダプターとフォト メーカー - テーマ的に一貫した画像を生成する方法を比較し、評価します。
パフォーマンスをテストするために、彼らは GPT-4 を使用して、特定のアクティビティを記述する 20 の役割命令と 100 のアクティビティ命令を生成しました。
定性的な結果を図 4 に示します。「StoryDiffusion は一貫性の高い画像を生成できます。一方、IP アダプターや PhotoMaker などの他の方法では、一貫性のない服装や制御可能なテキストが生成される可能性があります。画像。"######

図 4: 一貫した画像生成に関する現在の方法との比較結果
研究者は表 1 にあります。定量的比較の結果は次のとおりです。提示されました。結果は次のようになります。「チームの StoryDiffusion は両方の定量的指標で最高のパフォーマンスを達成しました。これは、この方法がキャラクターの特徴を維持しながらプロンプトの説明によく適合し、その堅牢性を示していることを示しています。」 表 1: 一貫した画像生成の定量的な比較結果
 トランジションビデオ生成の比較
トランジションビデオ生成の比較
用語研究チームは、トランジション ビデオの生成について、SparseCtrl と SEINE という 2 つの最先端の方法と比較してパフォーマンスを評価しました。
彼らはトランジション ビデオ生成の定性的な比較を実施し、その結果を図 5 に示しました。結果は、「チームの StoryDiffusion は SEINE や SparseCtrl よりも大幅に優れており、生成されたトランジション ビデオはスムーズで物理原理と一致しています。」 #図 5: 現在さまざまな最先端の方法を使用したトランジション ビデオ生成の比較
彼らはまた、この方法を SEINE および SparseCtrl と比較し、LPIPSfirst、LPIPS の 4 つを使用しました。フレーム、CLIPSIM ファースト、および CLIPSIM フレームを含む定量的指標を表 2 に示します。

詳細な技術的および詳細については、実験の詳細については、元の論文を参照してください。
以上がルカンが月に? Nankai と Byte が StoryDiffusion をオープンソース化、複数枚の漫画や長いビデオをより一貫性のあるものにするの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 Vue Paginationの使用方法
Apr 08, 2025 am 06:45 AM
Vue Paginationの使用方法
Apr 08, 2025 am 06:45 AM
ページネーションは、パフォーマンスとユーザーエクスペリエンスを向上させるために、大きなデータセットを小さなページに分割するテクノロジーです。 VUEでは、次の組み込みメソッドを使用してページを使用できます。ページの総数を計算します。TotalPages()トラバーサルページ番号:V-For Directive on Currentページを設定します。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 gitはgithubと同じですか?
Apr 08, 2025 am 12:13 AM
gitはgithubと同じですか?
Apr 08, 2025 am 12:13 AM
gitとgithubは同じものではありません。 Gitはバージョン制御システムであり、GithubはGitベースのコードホスティングプラットフォームです。 GITはコードバージョンの管理に使用され、GitHubはオンラインコラボレーション環境を提供します。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
