

58 行のコードは Llama 3 から 100 万コンテキストまで拡張可能、あらゆる微調整バージョンが適用可能

Llama 3、オープンソースの雄大な王様、オリジナルのコンテキストウィンドウは、実際には...8k しかありません。これには「本当に」という言葉を飲み込みました。おいしい」とまた口元に。。
現在、32k が開始点であり、100k が一般的ですが、これはオープンソース コミュニティへの貢献の余地を意図的に残しているのでしょうか?
オープンソース コミュニティは、この機会を決して逃すことはありません:
わずか 58 行のコードで、Llama 3 70b の微調整されたバージョンであれば、 1048k(100万)コンテキストは自動的に拡張されます。
ファイルはわずか 800mb です。
次に、Mergekit を使用して、同じアーキテクチャの他のモデルで実行したり、モデルに直接マージしたりできます。
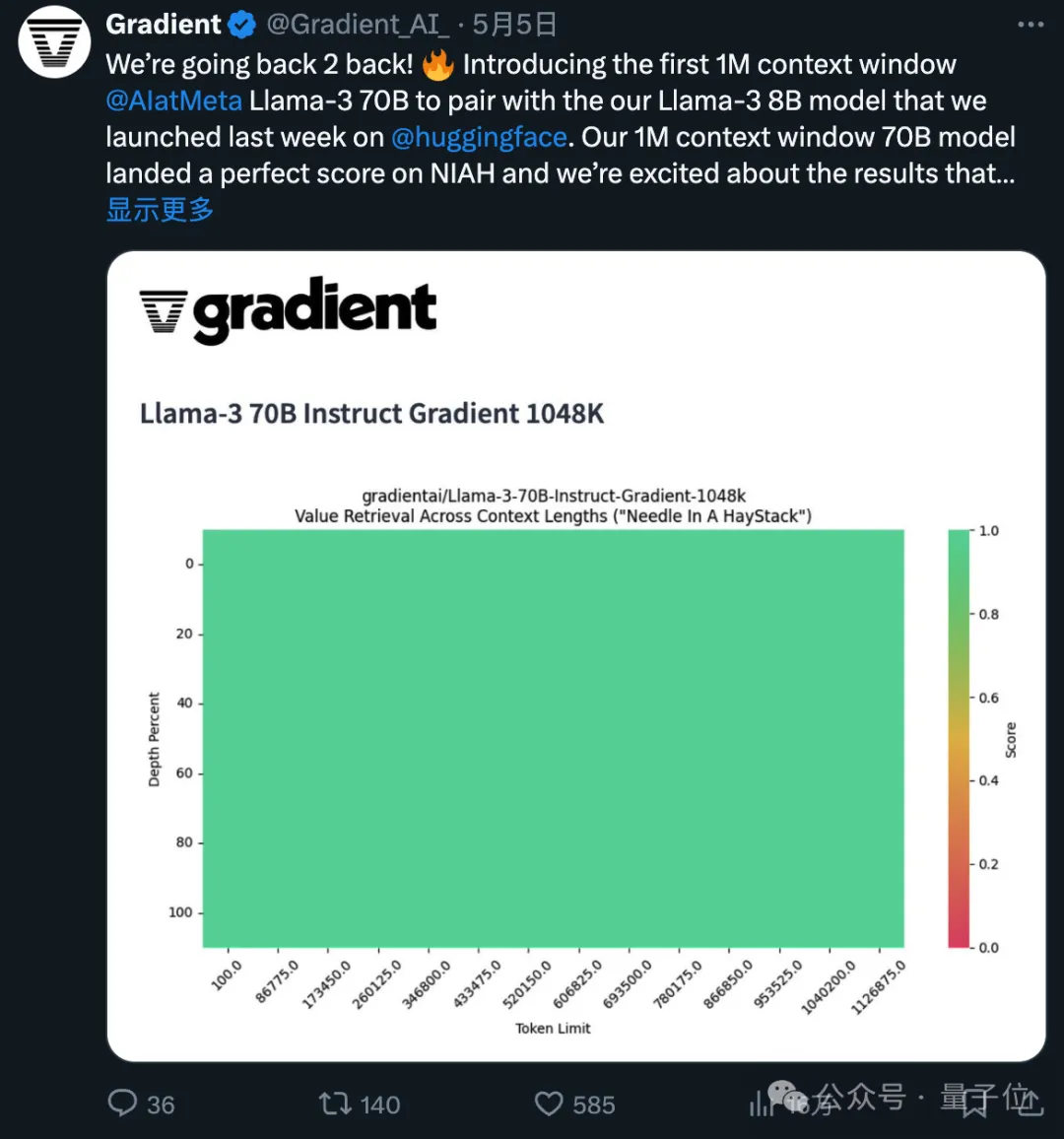
Gradient AI から来ています。 はエンタープライズ AI ソリューションのスタートアップです。

Eric Hartford によるもので、微調整されたモデルと元のバージョンの違いを比較します。 、パラメータはさまざまに抽出されます。
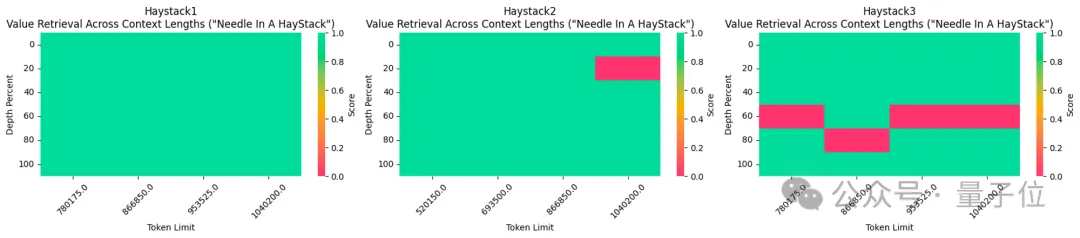
彼は最初に 524k コンテキスト バージョンを作成し、次に 1048k バージョンを更新しました。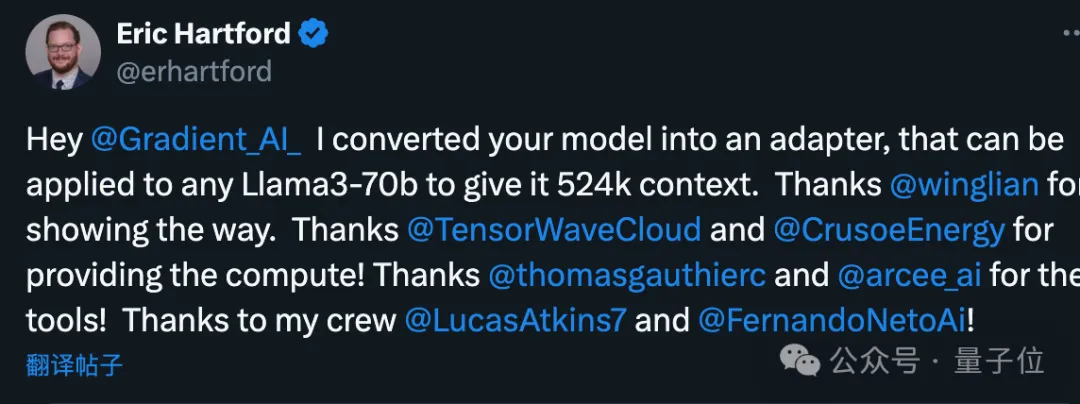
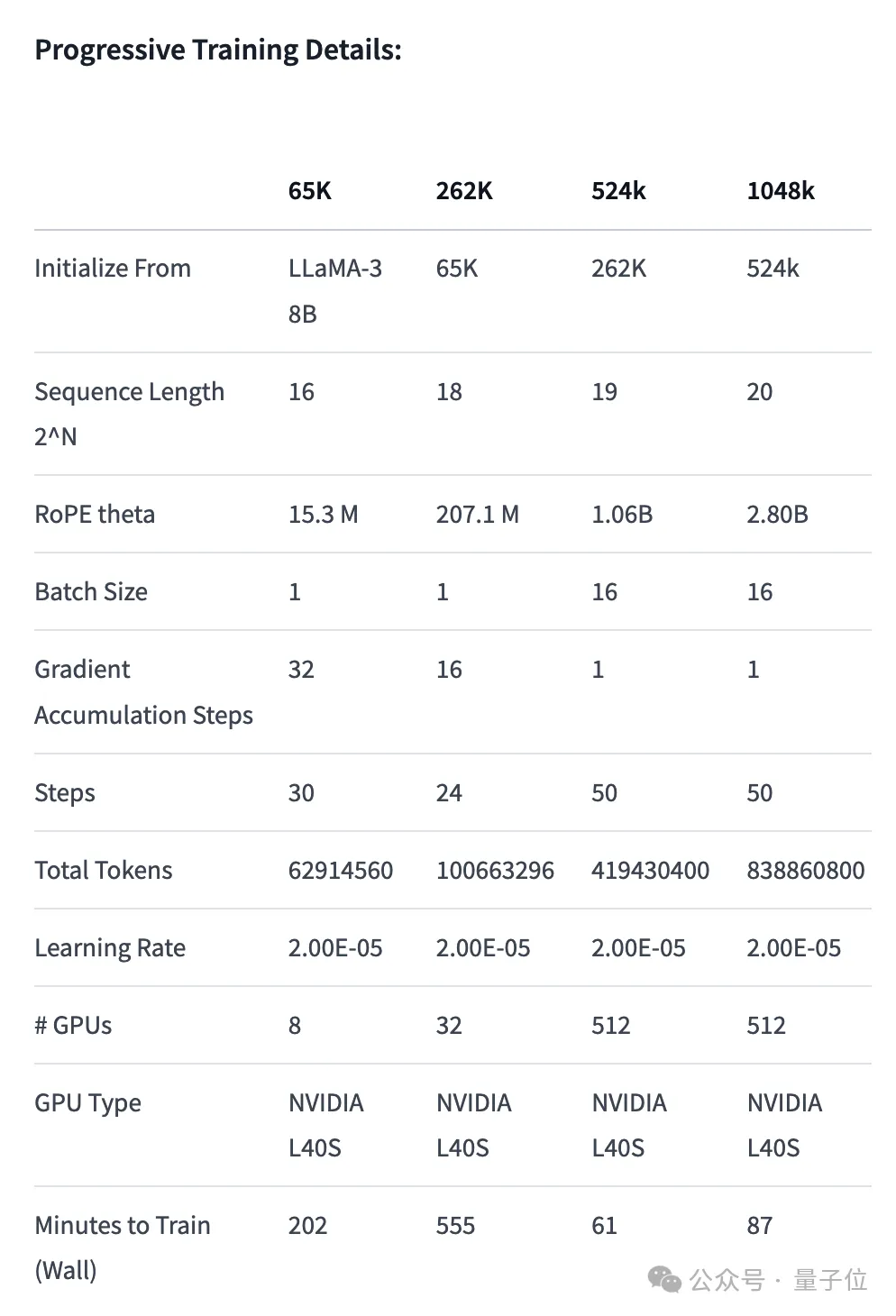
- 位置エンコーディングの調整: RoPE theta を NTK で初期化します。意識的な補間 最適なスケジューリング、長さを延長した後の高周波情報の損失を防ぐための最適化
- プログレッシブ トレーニング: カリフォルニア大学バークレー校によって提案Pieter Abbeel チーム Blockwise RingAttendance メソッドはモデルのコンテキスト長を拡張します

#524k バージョン LoRA: https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-524k-adapter
1048k バージョン LoRA: https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-1048k-adapter
# #マージコード:https://gist.github.com/ehartford/731e3f7079db234fa1b79a01e09859ac
以上が58 行のコードは Llama 3 から 100 万コンテキストまで拡張可能、あらゆる微調整バージョンが適用可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7333
7333
 9
1627
14
1351
46
1262
25
1209
29
9
1627
14
1351
46
1262
25
1209
29

 DeepSeekをインストールする方法
Feb 19, 2025 pm 05:48 PM
DeepSeekをインストールする方法
Feb 19, 2025 pm 05:48 PM
DeepSeekをインストールするには、Dockerコンテナ(最も便利な場合は、互換性について心配する必要はありません)を使用して、事前コンパイルパッケージ(Windowsユーザー向け)を使用してソースからコンパイル(経験豊富な開発者向け)を含む多くの方法があります。公式文書は慎重に文書化され、不必要なトラブルを避けるために完全に準備します。
 DeepSeek使用のためのFAQの概要
Feb 19, 2025 pm 03:45 PM
DeepSeek使用のためのFAQの概要
Feb 19, 2025 pm 03:45 PM
Deepseekai ToolユーザーガイドとFAQ Deepseekは、強力なAIインテリジェントツールです。 FAQ:異なるアクセス方法の違い:Webバージョン、アプリバージョン、API呼び出しの間に機能に違いはありません。アプリは、Webバージョンのラッパーにすぎません。ローカル展開は蒸留モデルを使用します。これは、DeepSeek-R1のフルバージョンよりもわずかに劣っていますが、32ビットモデルには理論的には90%のフルバージョン機能があります。居酒屋とは何ですか? Sillytavernは、APIまたはOllamaを介してAIモデルを呼び出す必要があるフロントエンドインターフェイスです。壊れた制限とは何ですか

 Grayscale Encryption Trust Fundsとは何ですか?
Mar 05, 2025 pm 12:33 PM
Grayscale Encryption Trust Fundsとは何ですか?
Mar 05, 2025 pm 12:33 PM
グレイスケール投資:機関投資家が機関や投資家にデジタル通貨投資サービスを提供するための機関投資家が入国します。同社はいくつかの暗号信託を立ち上げました。これは広範な市場の注目を集めていますが、これらの資金のトークン価格に対する影響は大きく異なります。この記事では、Grayscaleの主要なCrypto Trust Fundsの一部を詳細に紹介します。 Grayscale Major Crypto Trust Fundsは、Grayscale Investment(2013年にDigitalCurrencyGroupによって設立された)で利用可能なさまざまなCrypto Asset Trust Fundsを管理し、機関投資家と順応の高い個人を提供する投資チャネルを提供します。その主な資金には、ZCASH(ZEC)、SOL、
 トップマーケットメーカーが暗号市場に参入すると、キャッスル証券は業界にどのような影響を与えますか?
Mar 04, 2025 pm 08:03 PM
トップマーケットメーカーが暗号市場に参入すると、キャッスル証券は業界にどのような影響を与えますか?
Mar 04, 2025 pm 08:03 PM
トップマーケットメーカーのキャッスル証券のビットコインマーケットメーカーへの参入は、ビットコイン市場の成熟度の象徴であり、将来の資産価格設定力を競うための従来の金融勢力の重要なステップです。ブルームバーグによると、2月25日、シタデル証券は暗号通貨の流動性プロバイダーになろうとしています。同社は、Coinbaseglobal、Binanceholdings、Crypto.comが運営する取引所など、さまざまな取引所でマーケットメーカーのリストに参加することを目指していると、この問題に精通している人々は述べています。取引所によって承認されると、当社は当初、米国外にマーケットメーカーチームを設立することを計画していました。この動きは標識だけではありません
 Delphi Digital:新しいElizaos V2アーキテクチャを解析することにより、新しいAIエコノミーを変更する方法は?
Mar 04, 2025 pm 07:00 PM
Delphi Digital:新しいElizaos V2アーキテクチャを解析することにより、新しいAIエコノミーを変更する方法は?
Mar 04, 2025 pm 07:00 PM
ElizaOSV2:AIのエンパワーメントAIは、補助ツールから独立したエンティティに進化しています。この記事では、ElizaOSV2の主要な革新と、AI主導の将来の経済をどのように形成するかについて説明します。 AIオートメーション:Elizaosを独立して操作することは、もともとWeb3オートメーションに焦点を当てたAIフレームワークでした。 V1バージョンを使用すると、AIはスマートコントラクトとブロックチェーンデータと対話できますが、V2バージョンは大幅なパフォーマンスの改善を実現します。単純な指示を実行する代わりに、AIはワークフローを独立して管理し、ビジネスを運営し、財務戦略を開発することができます。アーキテクチャのアップグレード:強化a
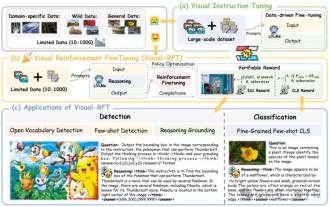 SFTを大幅に超えて、O1/DeepSeek-R1の背後にある秘密は、マルチモーダルの大規模モデルでも使用できます
Mar 12, 2025 pm 01:03 PM
SFTを大幅に超えて、O1/DeepSeek-R1の背後にある秘密は、マルチモーダルの大規模モデルでも使用できます
Mar 12, 2025 pm 01:03 PM
上海ジョトン大学、上海アイラブ、および香港中国大学の研究者は、Visual Language Big Model(LVLM)のパフォーマンスを大幅に改善するために少量のデータのみを必要とする視覚RFT(視覚エンハンスメントファインチューニング)オープンソースプロジェクトを開始しました。 Visual-RFTは、DeepSeek-R1のルールベースの強化学習アプローチとOpenAIの強化微調整(RFT)パラダイムを巧みに組み合わせて、このアプローチをテキストフィールドから視野に拡張しました。視覚的サブカテゴリ化やオブジェクト検出などのタスクの対応するルール報酬を設計することにより、Visual-RFTは、テキスト、数学的推論、その他のフィールドに限定されているDeepSeek-R1メソッドの制限を克服し、LVLMトレーニングの新しい方法を提供します。 Vis
 ビットワイズ:企業はビットコインを無視された大きな傾向を購入します
Mar 05, 2025 pm 02:42 PM
ビットワイズ:企業はビットコインを無視された大きな傾向を購入します
Mar 05, 2025 pm 02:42 PM
毎週の観察:ビットコインを蓄えている企業 - 醸造の変化毎週のメモの見落とされがちな市場動向をよく指摘します。 MicroStrategyの動きは厳しい例です。多くの人は、「マイクロストラテジーとマイケルセイリャーはすでによく知られていますが、これは真実ですが、多くの投資家はそれを特別なケースと見なし、その背後にあるより深い市場の力を無視しています。このビューは片側です。ここ数ヶ月の予備資産としてのビットコインの採用に関する詳細な研究は、これが孤立したケースではなく、出現している主要な傾向であることを示しています。今後12〜18か月で、何百もの企業が訴訟を起こし、大量のビットコインを購入すると予測しています
