

Java の基礎から実践的な応用への入門: ビッグデータの実践的な分析

このチュートリアルは、Java の基礎から実践的なアプリケーションまでビッグ データ分析スキルを習得するのに役立ちます。 Java の基本 (変数、制御フロー、クラスなど)、ビッグ データ ツール (Hadoop エコシステム、Spark、Hive)、および実践的なケース (OpenFlights からの飛行データの取得) が含まれています。 Hadoop を使用してデータを読み取り、処理し、フライトの目的地として最も頻繁に使用される空港を分析します。 Spark を使用してドリルダウンし、目的地への最新のフライトを見つけます。 Hive を使用して対話的にデータを分析し、各空港のフライト数をカウントします。

#Java の基礎から実践的な応用: ビッグデータの実践的な分析
#はじめに ビッグデータ時代の到来により、ビッグデータ分析スキルを習得することが重要になっています。このチュートリアルでは、Java の基礎から Java を使用した実践的なビッグ データ分析までを説明します。
Java の基本変数、データ型、演算子
- 制御フロー (if-else、for、while)
- クラス、オブジェクト、メソッド ##配列とコレクション (リスト、マップ、コレクション)
- ##ビッグ データ分析ツール
Spark
Hive- 実用的なケース: Java を使用した飛行データの分析
OpenFlights データセットからフライト データをダウンロードします。
ステップ 2: Hadoop を使用したデータの読み取りと書き込み
Hadoop と MapReduce を使用したデータの読み取りと処理。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlightStats {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Flight Stats");
job.setJarByClass(FlightStats.class);
job.setMapperClass(FlightStatsMapper.class);
job.setReducerClass(FlightStatsReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class FlightStatsMapper extends Mapper<Object, Text, Text, IntWritable> {
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(",");
context.write(new Text(line[1]), new IntWritable(1));
}
}
public static class FlightStatsReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
}ステップ 3: Spark を使用してさらに分析する
Spark DataFrame と SQL クエリを使用してデータを分析します。
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class FlightStatsSpark {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().appName("Flight Stats Spark").getOrCreate();
Dataset<Row> flights = spark.read().csv("hdfs:///path/to/flights.csv");
flights.createOrReplaceTempView("flights");
Dataset<Row> top10Airports = spark.sql("SELECT origin, COUNT(*) AS count FROM flights GROUP BY origin ORDER BY count DESC LIMIT 10");
top10Airports.show(10);
}
}ステップ 4: Hive 対話型クエリを使用する
Hive 対話型クエリを使用してデータを分析します。
CREATE TABLE flights (origin STRING, dest STRING, carrier STRING, dep_date STRING, dep_time STRING, arr_date STRING, arr_time STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; LOAD DATA INPATH 'hdfs:///path/to/flights.csv' OVERWRITE INTO TABLE flights; SELECT origin, COUNT(*) AS count FROM flights GROUP BY origin ORDER BY count DESC LIMIT 10;
結論
このチュートリアルを通じて、Java の基本と、実際のビッグ データ分析に Java を使用するスキルを習得しました。 Hadoop、Spark、Hive を理解することで、大規模なデータ セットを効率的に分析し、そこから貴重な洞察を抽出できます。
以上がJava の基礎から実践的な応用への入門: ビッグデータの実践的な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7469
7469
 15
1376
52
77
11
19
29
15
1376
52
77
11
19
29

 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
Java は、初心者と経験豊富な開発者の両方が学習できる人気のあるプログラミング言語です。このチュートリアルは基本的な概念から始まり、高度なトピックに進みます。 Java Development Kit をインストールしたら、簡単な「Hello, World!」プログラムを作成してプログラミングを練習できます。コードを理解したら、コマンド プロンプトを使用してプログラムをコンパイルして実行すると、コンソールに「Hello, World!」と出力されます。 Java の学習はプログラミングの旅の始まりであり、習熟が深まるにつれて、より複雑なアプリケーションを作成できるようになります。
 ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
多くのウェブサイト開発者は、ランプアーキテクチャの下でnode.jsまたはPythonサービスを統合する問題に直面しています:既存のランプ(Linux Apache MySQL PHP)アーキテクチャWebサイトのニーズ...
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトを実行するには、次の手順が必要です。Webサーバー、node.js、開発ツールなどの必要なツールのインストール。開発環境の構築、プロジェクトフォルダーの作成、プロジェクトの初期化、コードの書き込み。開発サーバーを起動し、コマンドラインを使用してコマンドを実行します。ブラウザでプロジェクトをプレビューし、開発サーバーURLを入力します。プロジェクトの公開、コードの最適化、プロジェクトの展開、Webサーバーの構成のセットアップ。
 Java をシンプルに: プログラミング能力を高める初心者向けガイド
Oct 11, 2024 pm 06:30 PM
Java をシンプルに: プログラミング能力を高める初心者向けガイド
Oct 11, 2024 pm 06:30 PM
Java をシンプルに: プログラミング能力の初心者向けガイド はじめに Java は、モバイル アプリケーションからエンタープライズ レベルのシステムに至るまで、あらゆるもので使用される強力なプログラミング言語です。初心者にとって、Java の構文はシンプルで理解しやすいため、プログラミングの学習に最適です。基本構文 Java は、クラスベースのオブジェクト指向プログラミング パラダイムを使用します。クラスは、関連するデータと動作をまとめて編成するテンプレートです。簡単な Java クラスの例を次に示します。 publicclassperson{privateStringname;privateintage;
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
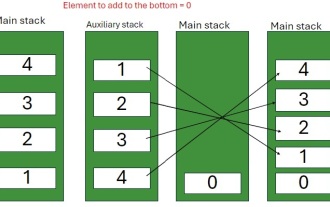 スタックの下部に要素を挿入するJavaプログラム
Feb 07, 2025 am 11:59 AM
スタックの下部に要素を挿入するJavaプログラム
Feb 07, 2025 am 11:59 AM
スタックは、LIFO(最後の、最初のアウト)の原則に従うデータ構造です。言い換えれば、スタックに最後に追加する要素は、削除される最初の要素です。要素をスタックに追加(またはプッシュ)すると、それらは上に配置されます。つまり、とりわけ
