

LeCun 氏が転送、AI により失語症の人が再び話せるようになりました。ニューヨーク大学が新しい「ニューラルスピーチ」デコーダをリリース

科学研究および応用分野におけるブレイン コンピューター インターフェイス (BCI) の開発は、一般に BCI の応用の可能性について広く注目を集めています。
神経系の欠陥によって引き起こされる失語症は、患者の日常生活に重大な支障をきたすだけでなく、専門能力の発達や社会活動も制限する可能性があります。ディープラーニングとブレインコンピューターインターフェース技術の急速な発展により、現代科学は神経音声補綴物を通じて失語症の人がコミュニケーション能力を取り戻すのを支援する方向に進んでいます。
人間の脳は一連のエキサイティングな発展を遂げ、音声や操作などの信号の解読において多くの画期的な進歩を遂げてきました。イーロン・マスク氏のニューラリンク社も、ブレイン・インターフェース・テクノロジーの破壊的な開発により、この分野で画期的な進歩を遂げたことは特に言及する価値があります。
同社は、被験者の脳に電極を埋め込むことに成功し、簡単なカーソル操作でタイピングやゲームなどの機能を利用できるようになりました。これは、より複雑な神経音声/運動デコードへの新たな一歩を示します。他の脳とコンピューターのインターフェイス技術と比較して、神経音声デコードはより複雑であり、その研究開発作業は主に特殊なデータソースである皮質電図 (ECoG) に依存しています。
ベッドは主に、患者の回復過程で受信した皮膚電気チャートのデータを処理します。研究者らはこれらの電極を使用して、発声中の脳活動に関するデータを収集しました。これらのデータは高度な時間的・空間的解像度を有するだけでなく、音声解読研究においても顕著な成果を上げ、ブレイン・コンピュータ・インターフェース技術の発展を大きく促進しました。これらの先進技術の助けにより、将来的にはより多くの神経障害を持つ人々がコミュニケーションの自由を取り戻すことが期待されています。
Nature に掲載された最近の研究では、画期的な進歩が達成されました。この研究では、定量化された HuBERT 特徴を、埋め込み型デバイスを装着した患者の中間表現として使用し、事前に訓練された音声合成変換器と組み合わせました。これらの特徴を音声に変換することで、音声の自然さを向上させるだけでなく、高い精度を維持するアプローチです。
ただし、HuBERT の機能はスピーカーの固有の音響特性を捉えることができず、生成されるサウンドは通常、統一されたスピーカーの音声であるため、この普遍的なサウンドを組み合わせるには追加のモデルが依然として必要です。具体的な患者さんの声。
もう 1 つの注目すべき点は、この研究とこれまでのほとんどの試みでは非因果的アーキテクチャが採用されているため、因果的操作を必要とするブレイン コンピューター インターフェイス アプリケーションでの実際の使用が制限される可能性があることです。
2024 年 4 月 8 日、ニューヨーク大学 VideoLab と Flinker Lab は共同で画期的な研究を雑誌「Nature Machine Intelligence」に発表しました。
 写真
写真
論文リンク: https://www.nature.com/articles/s42256-024-00824-8
研究関連のコードのオープン ソースは https://github.com/flinkerlab/neural_speech_decoding
さらに生成された音声の例は https://xc1490.github.io/nsd/# にあります。
##「深層学習と音声合成を活用したニューラル音声復号化フレームワーク」というタイトルのこの研究では、革新的な微分可能な音声合成装置を紹介します。 シンセサイザーは、軽量の畳み込みニューラル ネットワークを組み合わせて、音声をピッチ、ラウドネス、フォルマント周波数などの一連の解釈可能な音声パラメータにエンコードし、微分可能な手法を使用して音声を再合成します。 この研究は、ニューラル信号をこれらの特定の音声パラメータにマッピングすることにより、解釈可能性が高く、小さなデータセットに適用可能なニューラル音声デコードシステムの構築に成功しました。このシステムは、高忠実度で自然な音声を再構築できるだけでなく、将来のブレイン コンピューター インターフェイス アプリケーションにおける高精度のための経験的基礎も提供します。 研究チームは合計48人の被験者からデータを収集し、これに基づいて音声の解読を試み、高精度脳の実用化と開発の基礎を提供しました。コンピュータインターフェース技術は確固たる基盤を築きました。 チューリング賞受賞者の Lecun 氏も研究の進捗状況を報告しました。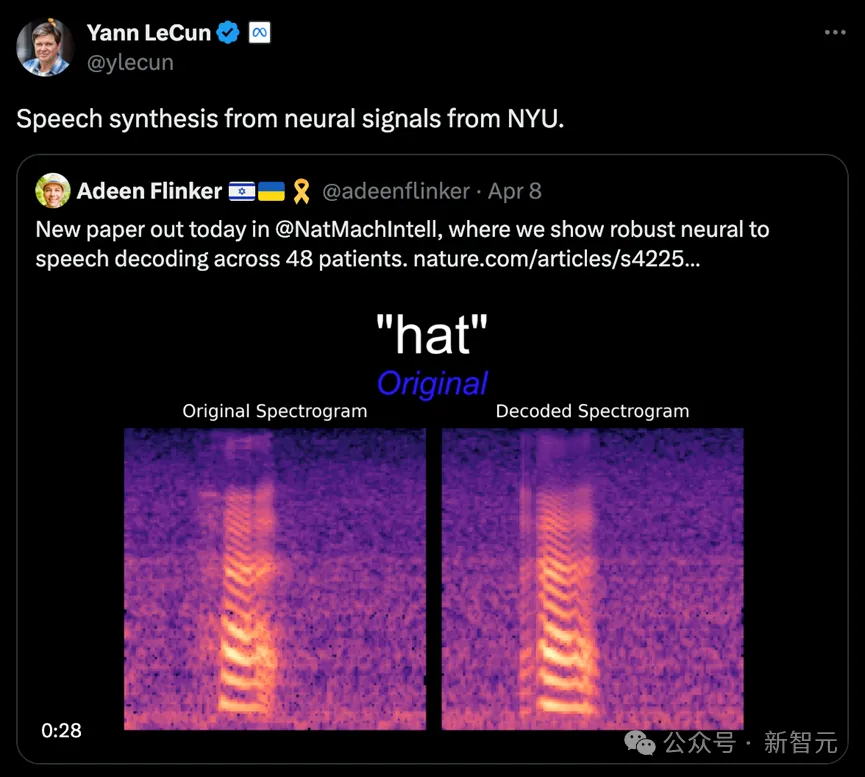 写真
写真
初期の試みでは、研究者は主に線形モデルを使用して神経信号を音声にデコードしました。このタイプのモデルは、巨大なデータセットのサポートを必要とせず、強力な解釈可能性を備えていますが、通常、その精度は低くなります。
最近、深層学習技術、特に畳み込みニューラル ネットワーク (CNN) とリカレント ニューラル ネットワーク (RNN) の応用の進歩により、研究者は音声の中間潜在表現をシミュレートしています。合成音声の品質を向上させるために広範な試みが行われてきた。
たとえば、一部の研究では、大脳皮質の活動を口の動きにデコードし、それを音声に変換します。この方法はデコードのパフォーマンスがより強力ですが、再構成された音は十分に自然に聞こえないことがよくあります。
さらに、いくつかの新しい方法では、Wavenet ボコーダーと敵対的生成ネットワーク (GAN) を使用して自然な音声を再構築しようとしています。これらの方法はサウンドの自然さを改善できますが、実際にはそうではありません。精度にはまだ限界があります。
主要モデル フレームワーク
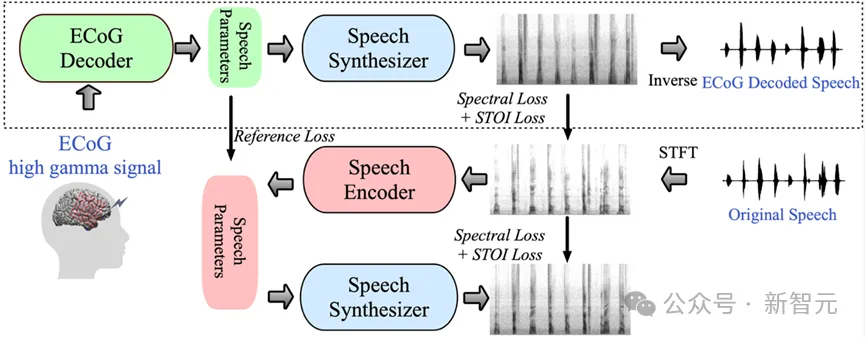
この研究では、研究チームは、脳波 (ECoG) 信号から音声への革新的なデコード フレームワークを実証しました。彼らは、音声信号のみを使用する軽量の音声符号化および復号化モデルによって生成される低次元の潜在表現空間を構築しました。
このフレームワークには 2 つのコア部分が含まれています。1 つ目は ECoG デコーダで、ECoG 信号をピッチや発音の有無などの一連の理解可能な音響音声パラメータに変換する役割を果たします。 、ラウドネスやフォルマント周波数など、これらのパラメータをスペクトログラムに変換する音声合成部分が続きます。
研究者らは、微分可能な音声合成装置を構築することで、ECoG デコーダをトレーニングしながら音声合成装置を最適化し、スペクトログラム再構成の誤差を共同で削減することができました。この低次元潜在空間の強力な解釈可能性と、軽量の事前トレーニング済み音声エンコーダーによって生成された参照音声パラメーターとを組み合わせることで、ニューラル音声復号化フレームワーク全体が効率的かつ適応可能になり、この分野のデータ不足の問題が効果的に解決されます。
さらに、このフレームワークは話者に非常に近い自然な音声を生成できるだけでなく、ECoG デコーダー部分に複数の深層学習モデル アーキテクチャの挿入をサポートし、因果的な操作。
研究チームは、48 人の脳神経外科患者の ECoG データを処理し、さまざまな深層学習アーキテクチャ (畳み込み、リカレント ニューラル ネットワーク、Transformer を含む) を使用して ECoG デコードを実現しました。
これらのモデルは、特に ResNet 畳み込みアーキテクチャを使用した実験で高い精度を示しました。この研究枠組みは、因果演算と比較的低いサンプリングレート(10mm間隔)により高い精度を達成するだけでなく、脳の左半球と右半球の両方から音声を効果的にデコードできる能力を実証し、それによってニューラルの応用範囲を拡大します。音声解読 右脳へ。
 写真
写真
この研究の中核となるイノベーションの 1 つは、微分可能な音声合成装置の開発です。音声再合成の効率が大幅に向上し、原音に近い高忠実度の音声を合成できます。
この音声合成装置の設計は人間の音声システムからインスピレーションを受けており、音声を 2 つの部分に細分化します: Voice (主に母音シミュレーションに使用) と Unvoice (主に母音シミュレーションに使用)子音のシミュレーション)。
音声パートでは、まず基本周波数信号を使用して倍音を生成し、次に F1 ~ F6 フォルマントで構成されるフィルターを通過させて、母音のスペクトル特性を取得します。
無声部分の場合、ホワイト ノイズに特定のフィルタリングを実行することによって、対応するスペクトルが生成されます。学習可能なパラメータは、各時点での 2 つの部分の混合比を制御します。
最後に、ラウドネス信号を調整し、背景ノイズを追加することで、最終的な音声スペクトルが生成されます。
この音声合成装置に基づいて、研究チームは効率的な音声再合成フレームワークとニューラル音声復号フレームワークを設計しました。詳細なフレーム構造については、元の記事の図 6 を参照してください。
研究結果
1. 時間的因果関係を伴う音声解読結果
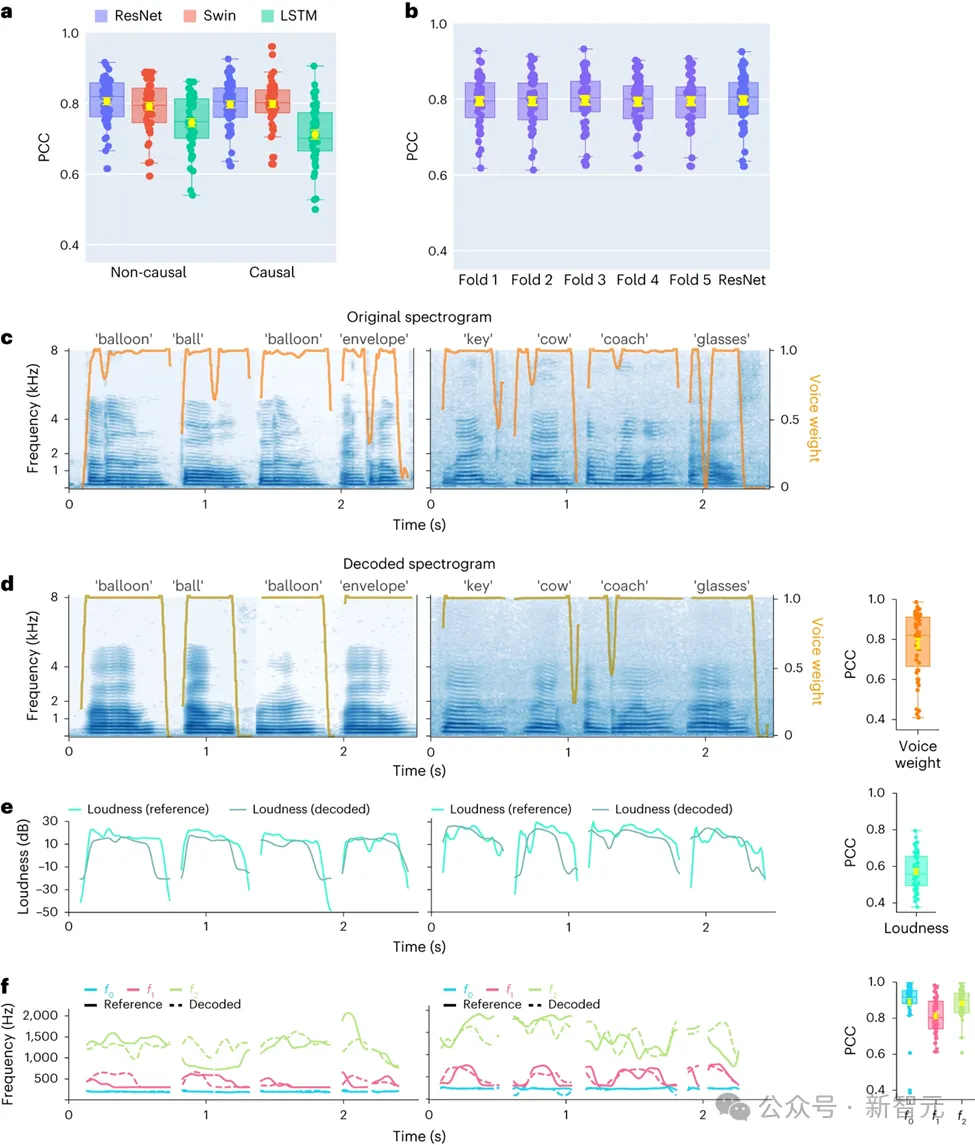
この研究では、まず、直接的な畳み込みネットワーク (ResNet)、リカレント ニューラル ネットワーク (LSTM)、トランスフォーマー アーキテクチャ (3D Swin) などのさまざまなモデル アーキテクチャの比較が、音声デコード パフォーマンスの違いを評価するために行われました。
これらのモデルは、時系列に対して非因果的操作または因果的操作を実行できることは注目に値します。
 写真
写真
ブレイン コンピューター インターフェイス (BCI) のアプリケーションにおけるモデルの原因と結果の解読) これには重要な意味があります。因果モデルは音声を生成するために過去と現在の神経信号のみを使用しますが、非因果モデルは将来の神経信号も参照しますが、これは実際には不可能です。
したがって、研究の焦点は、因果関係のある操作と非因果関係の操作を実行したときの同じモデルのパフォーマンスを比較することです。結果は、ResNet モデルの因果関係のあるバージョンでも、非因果関係のあるバージョンと同等のパフォーマンスがあり、両者の間に大きなパフォーマンスの差がないことを示しています。
同様に、Swin モデルの因果バージョンと非因果バージョンは同様のパフォーマンスを示しますが、LSTM の因果バージョンのパフォーマンスは非因果バージョンよりも大幅に低くなります。この研究では、音の重み(母音と子音を区別するパラメータ)、ラウドネス、基本周波数 f0、第 1 フォルマント f1、第 2 フォルマント f2 など、いくつかの主要な音声パラメータの平均デコード精度(合計 48 サンプル)も実証されました。
これらの音声パラメータ、特に基本周波数、音の重み、最初の 2 つのフォルマントを正確に再構成することは、正確な音声デコードと参加者の音声の自然な再生を実現するために重要です。
研究結果は、非因果モデルと因果モデルの両方が合理的な解読効果を提供できることを示しており、これは将来の関連研究と応用に前向きなインスピレーションを与えます。
2. 音声デコードと左脳と右脳の神経信号の空間サンプリング レートに関する研究
最新の研究では、研究者らは、音声デコードにおける左脳と右脳の半球のパフォーマンスの違い。
伝統的に、ほとんどの研究は、音声および言語機能と密接に関連する左半球に焦点を当ててきました。
 写真
写真
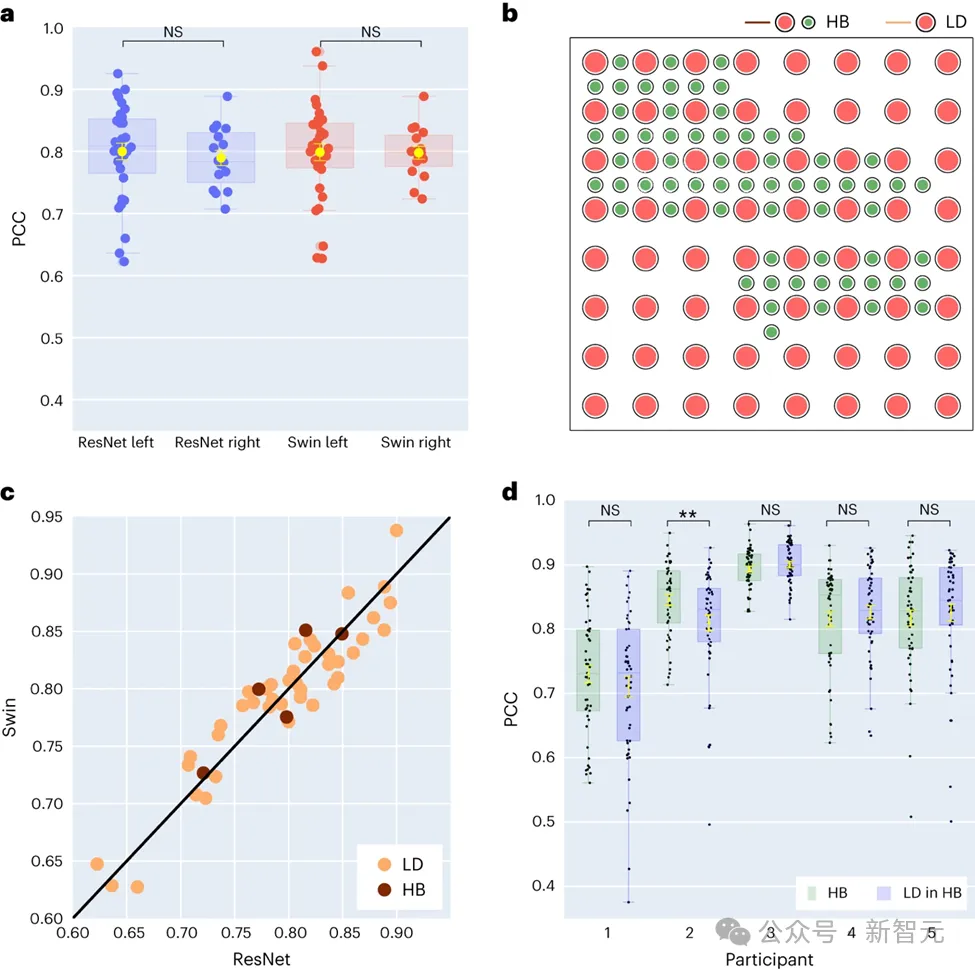
ただし、右脳半球の言語情報を解読する能力について私たちが知っていることは、まだ非常に限られています。この領域を調査するために、研究チームは参加者の左半球と右半球のデコード性能を比較し、音声回復に右半球を使用する実現可能性を検証しました。
研究で収集された 48 人の被験者のうち、16 人が右脳からの ECoG 信号を持っていました。 ResNet デコーダと Swin デコーダのパフォーマンスを比較することにより、研究者らは右半球でも音声を効果的にデコードでき、その効果は左半球の場合と同様であることを発見しました。この発見は、左脳に損傷があり言語機能を失った患者に言語回復の選択肢を提供する可能性がある。
研究には、音声デコード効果に対する電極サンプリング密度の影響も含まれています。以前の研究では主に高密度の電極グリッド (0.4 mm) が使用されていましたが、臨床現場で一般的に使用されている電極グリッドの密度はそれより低い (1 cm) です。
この研究の 5 人の参加者は、主に低密度ですが、いくつかの電極が追加されたハイブリッド型 (HB) 電極グリッドを使用しました。残りの 43 人の参加者には低密度サンプリングが使用されました。
結果は、これらのハイブリッド サンプリング (HB) のデコード パフォーマンスが従来の低密度サンプリング (LD) のデコード パフォーマンスと同様であることを示しており、このモデルが脳からデータを効果的に抽出できることを示しています。異なる密度の皮質電極グリッドで音声情報を学習します。この発見は、臨床現場で一般的に使用される電極サンプリング密度が、将来のブレイン-コンピューター インターフェイス アプリケーションをサポートするのに十分である可能性があることを示唆しています。
3. 音声解読に対する左脳と右脳の異なる脳領域の寄与に関する研究
研究者らは音声関連についても調査しました。これは、将来、左脳と右脳の半球に音声復元装置が埋め込まれる可能性に対して重要な意味を持ちます。音声デコードに対するさまざまな脳領域の影響を評価するために、研究チームはオクルージョン分析を使用しました。
ResNet デコーダーと Swin デコーダーの因果モデルと非因果モデルを比較することにより、この研究では、非因果モデルでは聴覚皮質の役割がより重要であることがわかりました。この結果は、将来のニューロフィードバック信号に依存できないリアルタイム音声デコード アプリケーションで因果モデルを使用する必要性を強調しています。 ##################写真############
さらに、研究では、音声解読に対する感覚運動皮質、特に腹部の寄与は、脳の左半球でも右半球でも同様であることも示しています。この発見は、言語を回復するために右半球に神経人工器官を移植することが実行可能な選択肢である可能性を示唆しており、将来の治療戦略に重要な洞察を提供します。
結論 (感動的な展望)
研究チームは、軽量のボリュームを使用する新しいタイプの微分可能な音声合成装置を開発しました。製品のニューラル ネットワークは音声をエンコードします。ピッチ、ラウドネス、フォルマント周波数などの一連の解釈可能なパラメータに変換し、同じ微分可能なシンセサイザーを使用して音声を再合成します。
研究者らは、神経信号をこれらのパラメータにマッピングすることで、解釈可能性が高く、小さなデータセットに適用でき、自然な音声を生成できるニューラル音声復号化システムを構築しました。
このシステムは、48 人の参加者の間で高度な再現性を実証し、異なる空間サンプリング密度でデータを処理でき、左脳と右脳の両方の電気信号を同時に処理できました。 、音声デコードにおける強力な可能性を示しています。
大幅な進歩にもかかわらず、研究者らは、ECoG 録音と組み合わせた音声トレーニング データに依存するデコード プロセスなど、モデルの現在の限界も指摘しており、これは人々にとって困難である可能性があります。失語症のある方は対象外です。
研究チームは将来、非グリッドデータを処理し、複数の患者およびマルチモーダルな脳波データをより効果的に利用できるモデルアーキテクチャを確立したいと考えています。ハードウェア技術の絶え間ない進歩と深層学習技術の急速な発展により、ブレイン・コンピュータ・インターフェース分野の研究はまだ初期段階にありますが、時間が経つにつれて、SF映画におけるブレイン・コンピュータ・インターフェースのビジョンは徐々に変化していきます。現実になる。
#参考:https://www.nature.com/articles/s42256-024-00824-8# #この記事の筆頭著者: Xupeng Chen (xc1490@nyu.edu)、Ran Wang、責任著者: Adeen Flinker
ニューラル音声デコーディングの因果関係について詳しくは、次のリンクを参照してください。著者による別の論文を参照してください:
https://www.pnas.org/doi/10.1073/pnas.2300255120
以上がLeCun 氏が転送、AI により失語症の人が再び話せるようになりました。ニューヨーク大学が新しい「ニューラルスピーチ」デコーダをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
18
20
15
1376
52
77
11
18
20

 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
mysqlはjsonを返すことができますか
Apr 08, 2025 pm 03:09 PM
MySQLはJSONデータを返すことができます。 json_extract関数はフィールド値を抽出します。複雑なクエリについては、Where句を使用してJSONデータをフィルタリングすることを検討できますが、そのパフォーマンスへの影響に注意してください。 JSONに対するMySQLのサポートは絶えず増加しており、最新バージョンと機能に注意を払うことをお勧めします。
 酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
酸性特性を理解する:信頼できるデータベースの柱
Apr 08, 2025 pm 06:33 PM
データベース酸属性の詳細な説明酸属性は、データベーストランザクションの信頼性と一貫性を確保するための一連のルールです。データベースシステムがトランザクションを処理する方法を定義し、システムのクラッシュ、停電、または複数のユーザーの同時アクセスの場合でも、データの整合性と精度を確保します。酸属性の概要原子性:トランザクションは不可分な単位と見なされます。どの部分も失敗し、トランザクション全体がロールバックされ、データベースは変更を保持しません。たとえば、銀行の譲渡が1つのアカウントから控除されているが別のアカウントに増加しない場合、操作全体が取り消されます。 TRANSACTION; updateaccountssetbalance = balance-100wh
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
 マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
マスターSQL制限条項:クエリの行数を制御する
Apr 08, 2025 pm 07:00 PM
sqllimit句:クエリ結果の行数を制御します。 SQLの制限条項は、クエリによって返される行数を制限するために使用されます。これは、大規模なデータセット、パジネートされたディスプレイ、テストデータを処理する場合に非常に便利であり、クエリ効率を効果的に改善することができます。構文の基本的な構文:SelectColumn1、column2、... FromTable_nameLimitnumber_of_rows; number_of_rows:返された行の数を指定します。オフセットの構文:SelectColumn1、column2、... FromTable_nameLimitoffset、number_of_rows; offset:skip
