

Occと自動運転の過去と現在を見てみよう!最初のレビューでは、機能強化/量産展開/アノテーションの効率化という 3 つの主要テーマを包括的にまとめています。

文面&筆者個人の理解
近年、自動運転はドライバーの負担軽減や運転の安全性向上につながる可能性があるため、ますます注目を集めています。ビジョンベースの 3 次元占有予測は、自動運転の安全性に関する費用対効果の高い包括的な調査に適した新たな認識タスクです。オブジェクト中心の知覚タスクと比較して 3D 占有予測ツールの優位性は多くの研究で実証されていますが、この急速に発展している分野に特化したレビューはまだあります。このホワイトペーパーでは、まずビジョンベースの 3D 占有予測の背景を紹介し、このタスクで直面する課題について説明します。次に、現在の 3D 占有予測手法の現状と開発傾向を、機能強化、展開の容易さ、ラベル付けの効率という 3 つの側面から包括的に説明します。最後に、現在の研究動向を要約し、いくつかの有望な将来展望を提案します。
オープンソースリンク: https://github.com/zya3d/Awesome-3D-Occupancy-Prediction
要約すると、この論文の主な貢献は次のとおりです:
- 私たちが知っている限り、この論文は最初の自動運転のためのビジョンベースの 3D 占有予測手法の包括的なレビュー。
- この記事では、機能強化、計算のしやすさ、ラベルの効率という 3 つの観点から、ビジョンベースの 3 次元占有予測手法の構造的概要を示し、さまざまなカテゴリの手法の詳細な分析と比較を行います。
- この論文では、ビジョンベースの 3D 占有率予測に関するいくつかの刺激的な将来の見通しを示し、関連する論文、データセット、コードを収集するために定期的に更新される github リポジトリを提供します。
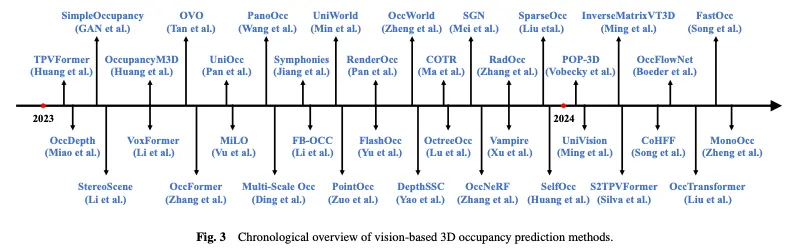
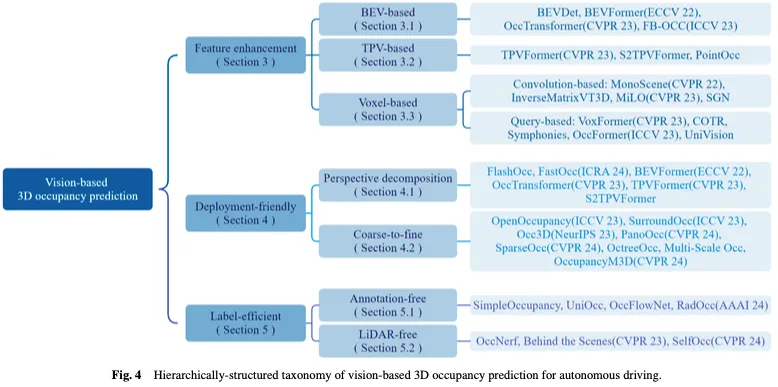
図 3 は、ビジョンベースの 3D 占有予測方法の時間的概要を示し、図 4 は、対応する階層構造の分類を示しています。
関連背景
真の値の生成
GT ラベルの生成は、3D 占有予測の課題です。 nuScenes や Waymo などの多くの 3D 認識データセットは LIDAR 点群セグメンテーション ラベルを提供しますが、これらのラベルは疎であり、高密度の 3D 占有予測タスクを監視するのは困難です。高密度占有を GT ラベルとして使用することの重要性は、Wei らによって実証されています。最近の研究の中には、疎な LIDAR 点群セグメンテーション アノテーションを使用して高密度の占有ラベルを生成することに焦点を当てたものがあり、3D 占有予測タスクに役立つデータセットとベンチマークを提供しています。
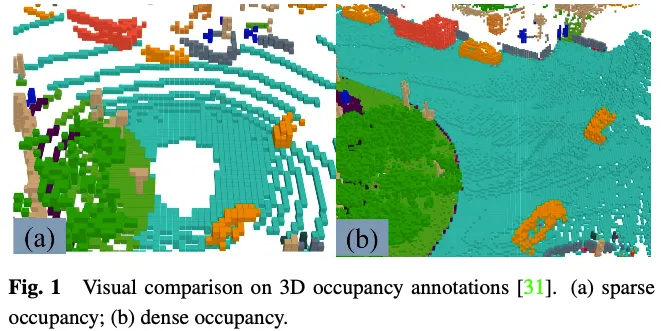
3D 占有予測タスクの GT ラベルは、3D 空間内の各要素が占有されているかどうか、および占有されている要素の意味ラベルを示します。 3 次元空間には多数の要素があるため、各要素に手動でラベルを付けることは困難です。一般的なアプローチは、既存の 3D 点群セグメンテーション タスクのグラウンド トゥルースをボクセル化し、ボクセル中間点のセマンティック ラベルに基づく投票を通じて 3D 占有予測用の GT を生成することです。ただし、この方法で生成されたグラウンド トゥルースは実際には単純化されています。図 1 に示すように、占有済みとしてマークされていない道路などの場所には、依然として多くの占有要素が存在します。この単純化された地形リアリティを持つモデルを含む監視ツールでは、モデルのパフォーマンスが低下します。したがって、高品質の高密度 3D 占有アノテーションを自動または半自動で生成する方法に取り組んでいる人もいます。
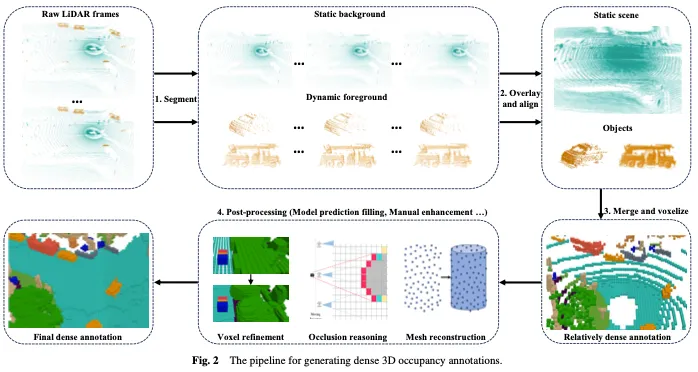
図 2 に示すように、高密度 3D 占有アノテーションの生成には、通常、次の 4 つのステップが含まれます。
- 連続生 LIDAR フレームを取得し、LIDAR ポイントを静的な背景と動的な前景にセグメント化します。
- 連続した LIDAR フレームを静的な背景に重ね合わせ、位置情報に基づいて動き補償を実行して、マルチフレームの点群を位置合わせして、より高密度の点群を取得します。連続した LIDAR フレームが動的前景に重ねられ、動的前景の点群がターゲット フレームとターゲット ID に従って位置合わせされて密度が高まります。点群は比較的密ですが、ボクセル化後にはさらに処理を必要とするギャップがまだいくつかあることに注意してください。
- 前景と背景の点群を結合し、それらをボクセル化し、投票メカニズムを使用してボクセルのセマンティクスを決定し、比較的高密度のボクセル アノテーションを生成します。
- 前のステップで取得したボクセルは後処理を通じて洗練され、GT としてより高密度で細かいアノテーションが実現されます。
データセット
このセクションでは、3D 占有率予測に一般的に使用されるオープンソースの大規模データセットをいくつか紹介します。それらの比較を表 1 に示します。
NUYv2 データセットは、Microsoft Kinect の RGB カメラと深度カメラでキャプチャされた、さまざまな屋内シーンからのビデオ シーケンスで構成されています。これには、密にラベル付けされて位置合わせされた 1,449 組の RGB および深度画像と、3 つの都市からの 407,024 個のラベルなしフレームが含まれています。主に屋内での使用を目的としており、自動運転シナリオには適していませんが、一部の研究ではこのデータセットを 3D 占有予測に使用しています。
SemanticKITTI は 3D 占有予測に広く使用されているデータセットで、KITTI データセットからの 22 のシーケンスと 43000 以上のフレームが含まれています。将来のフレームをオーバーレイし、ボクセルをセグメント化し、ポイント投票によってラベルを割り当てることにより、高密度の 3D 占有注釈を作成します。さらに、光線を追跡して車のポーズごとにどのボクセルがセンサーに表示されているかを調べ、トレーニングと評価中に目に見えないボクセルを無視します。ただし、KITTI データセットに基づいているため、入力としてフロント カメラからの画像のみが使用され、後続のデータセットでは通常マルチビュー画像が使用されます。表 2 に示すように、SemanticKITTI データセット上の既存手法の評価結果を収集しました。
NuScenes 占有率は、屋外環境における大規模な自動運転データセットである NuScenes に基づく 3D 占有率予測データセットです。これには、850 のシーケンス、200,000 のフレーム、17 のセマンティック カテゴリが含まれています。データセットは、最初に拡張および精製 (AAP) パイプラインを使用して大まかな 3D 占有ラベルを生成し、次に手動拡張を使用してラベルを調整します。さらに、高度な 3D 占有予測方法を評価するために、アンビエント セマンティック占有認識の最初のベンチマークである OpenOccupancy を導入します。
その後、Tian らは、nuScenes と Waymo の自動運転データセットに基づいて、3D 占有率予測用の Occ3D nuScenes と Occ3D Waymo データセットをさらに構築しました。彼らは、既存のラベル付き 3D 認識データセットを活用し、可視性に基づいてボクセル タイプを識別する半自動ラベル生成パイプラインを導入しています。さらに、さまざまな手法の評価と比較を強化するために、大規模な 3D 占有予測用の Occ3d ベンチマークを確立しました。表 2 に示すように、Occ3D nuScenes データセットに対する既存の手法の評価結果を収集しました。
さらに、Occ3D Nude および Nude Occupancy と同様に、OpenOcc も Nude データセットに基づいて 3D 占有予測用に構築されたデータセットです。これには、850 のシーケンス、34149 のフレーム、および 16 のクラスが含まれています。このデータセットは、8 つの前景オブジェクトに追加のアノテーションを提供し、動作計画などの下流のタスクに役立つことに注意してください。
主な課題
ビジョンベースの 3D 占有予測は近年大幅に進歩しましたが、特徴の表現、実用化、およびアノテーションのコストによる制限に依然として直面しています。このタスクには 3 つの重要な課題があります。 (1) 2D ビジュアル入力から完璧な 3D 特徴を取得することは困難です。ビジョンベースの 3D 占有予測の目標は、画像入力のみから 3D シーンの詳細な認識と理解を達成することです。ただし、画像に固有の深さと幾何学的情報が欠如しているため、画像から 3D 特徴表現を直接学習することは大きな課題となります。 (2) 3 次元空間での計算負荷が大きい。 3D 占有予測では通常、環境空間を表現するために 3D ボクセル特徴を使用する必要がありますが、これには必然的に特徴抽出のための 3D 畳み込みなどの操作が含まれ、これにより計算量とメモリのオーバーヘッドが大幅に増加し、実際の展開が妨げられます。 (3) 高価なきめの細かい注釈。 3D 占有予測には、高解像度ボクセルの占有ステータスとセマンティック カテゴリの予測が含まれますが、これを達成するには、多くの場合、各ボクセルのきめ細かいセマンティック アノテーションが必要であり、時間とコストがかかり、このタスクのボトルネックとなっています。
これらの重要な課題に対応して、自動運転のためのビジョンベースの 3 次元占有予測に関する研究作業は、機能強化、展開の容易さ、およびラベル付けの効率という 3 つの主要な方針を徐々に形成してきました。特徴強化手法は、ネットワークの特徴表現機能を最適化することで、3D 空間出力と 2D 空間入力の間の差異を軽減します。導入に適したアプローチは、シンプルで効率的なネットワーク アーキテクチャを設計することでパフォーマンスを確保しながら、リソース消費を大幅に削減することを目的としています。効率的なラベル付け方法は、注釈が不十分または完全に存在しない場合でも、満足のいくパフォーマンスを達成することが期待されます。次に、これら 3 つの分野に関する現在のアプローチの包括的な概要を説明します。
特徴強化方法
ビジョンベースの 3D 占有予測のタスクには、2D 画像空間から 3D ボクセル空間の占有ステータスと意味情報を予測することが含まれます。これは、2D 視覚入力から完璧な 3D 特徴を取得するという重要な課題を引き起こします。この問題に対処するために、一部の方法では、鳥瞰図 (BEV)、三面図 (TPV)、および 3 次元ボクセル表現からの学習など、機能強化の観点から占有予測を改善しています。
BEV ベースの手法
占有を学習するための効果的な手法は、鳥瞰図 (BEV) に基づいており、オクルージョンの影響を受けず、特定の深さの幾何学的情報を含む特徴を提供します。強力な BEV 表現を学習することで、堅牢な 3D 占有シーンの再構築を実現できます。まず、2D バックボーン ネットワークを使用して視覚入力から画像特徴を抽出し、次に視点変換を通じて BEV 特徴を取得し、最後に BEV 特徴表現に基づいて 3D 占有予測を完了します。 BEV ベースの方法を図 5 に示します。
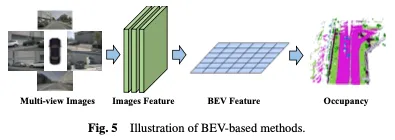
簡単なアプローチは、3D オブジェクト検出で BEVDet や BEVFormer などのメソッドを使用するなど、他のタスクからの BEV 学習を活用することです。これらの占有学習方法を拡張するために、トレーニング中に占有ヘッドを追加または交換して、最終結果を得ることができます。この適応により、占有推定を既存の BEV ベースのフレームワークに統合できるようになり、シーン内の 3D 占有の検出と再構築を同時に行うことが可能になります。強力なベースライン BEVFormer に基づいて、OccTransformer はデータ拡張を採用してトレーニング データの多様性を高め、モデルの一般化機能を向上させ、強力な画像バックボーンを活用して入力データからより有益な特徴を抽出します。また、シーンの空間情報をより適切にキャプチャするための 3D Unet Head と、モデルの最適化を改善するための追加の損失関数も導入されています。
TPV ベースの手法
BEV ベースの表現には、本質的に 3D 空間のトップダウン投影を提供するため、画像と比較して一定の利点がありますが、単一の平面を使用してオブジェクトを記述する機能が本質的に不足しています。シーンのきめの細かい 3D 構造。 3 つの視野角 (TPV) に基づく方法では、3 つの直交投影面を利用して 3D 環境をモデル化し、占有予測のための視覚的特徴の表現能力をさらに強化します。まず、2D バックボーン ネットワークを使用して視覚入力から画像の特徴が抽出されます。続いて、これらの画像特徴は 3 視点空間に変換され、最終的に 3 つの投影視点の特徴表現に基づいて 3D 占有率予測が実現されます。 BEV ベースの方法を図 7 に示します。
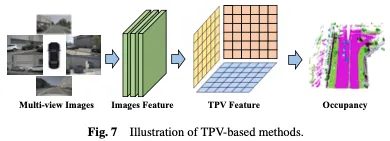
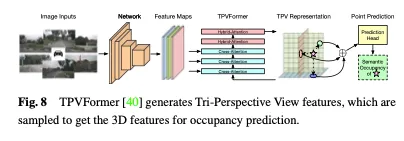
BEV フィーチャーに加えて、TPVFormer は同じ方法で正面ビューと側面ビューのフィーチャーも生成します。各平面は異なる視点から 3D 環境をモデル化し、それらの組み合わせにより 3D 構造全体の包括的な説明が提供されます。具体的には、3 次元空間内の点の特徴を取得するには、まずそれを 3 つの平面のそれぞれに投影し、双一次補間を使用して投影された各点の特徴を取得します。次に、3 つの投影特徴を 3D 点の合成特徴に要約します。したがって、TPV 表現は、任意の解像度で 3D シーンを記述し、3D 空間内の異なる点に異なる特徴を生成できます。さらに、2D 画像から TPV 特徴を効率的に取得し、TPV グリッド クエリと対応する 2D 画像特徴の間で画像クロスアテンションを実行するトランスベース エンコーダー (TPVFormer) を提案します。これにより、2D 情報が 3D 空間へのアップグレードに変換されます。最後に、TPV 機能間のクロスビュー ハイブリッド アテンションにより、3 つのプレーン間の相互作用が可能になります。 TPVFormer の全体的なアーキテクチャを図 8 に示します。
ボクセルベースのメソッド
3D 空間を投影されたパースペクティブ (BEV や TPV など) に変換することに加えて、3D ボクセル表現を直接操作するメソッドもあります。これらの方法の主な利点は、元の 3D 空間から直接学習できるため、情報の損失が最小限に抑えられることです。これらの方法では、生の 3 次元ボクセル データを活用することで、完全な空間情報を効果的にキャプチャして利用することができ、その結果、占有状況をより正確かつ包括的に理解することができます。まず、2D バックボーン ネットワークを使用して画像の特徴を抽出し、次に特別に設計された畳み込みベースのメカニズムを使用して 2D 表現と 3D 表現をブリッジするか、クエリベースのアプローチを使用して 3D 表現を直接取得します。最後に、3D 占有ヘッドを使用して、学習した 3D 表現に基づいて最終予測を完了します。ボクセルベースの方法を図 9 に示します。
畳み込みベースのメソッド
1 つのアプローチは、特別に設計された畳み込みアーキテクチャを活用して 2D から 3D へのギャップを埋め、3D 占有表現を学習することです。このアプローチの顕著な例は、機能ブリッジングのキャリアとして U-Net アーキテクチャを採用することです。 U-Net アーキテクチャは、アップサンプリング パスとダウンサンプリング パスの間にスキップ接続を備えたエンコーダ/デコーダ構造を採用し、低レベルと高レベルの機能情報を保持して情報損失を軽減します。 U-Net 構造は、さまざまな深さの畳み込み層を通じて、さまざまなスケールの特徴を抽出することができ、モデルが画像内のローカルな詳細とグローバルなコンテキスト情報をキャプチャできるようにすることで、複雑なシーンに対するモデルの理解を強化し、効果的な占有予測を実行します。
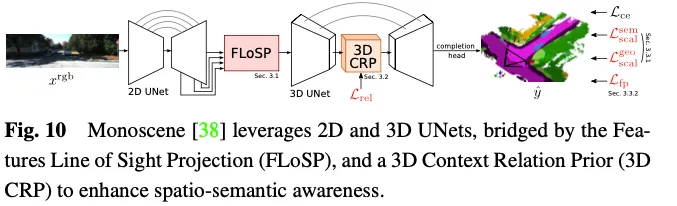
Monoscene は、ビジョンベースの 3D 占有予測に U-net を利用しています。これは、フィーチャ透視投影を使用して 2 次元フィーチャを 3 次元空間に投影し、2 次元フィーチャに基づいて 3 次元フィーチャ空間を計算する、2 次元フィーチャ視線投影 (FLoSP) と呼ばれるメカニズムを導入しています。イメージング原理とカメラ パラメータに関する 3 次元特徴空間内のサンプル特徴の各点の座標。この方法は、2D フィーチャを統合された 3D フィーチャ マップにプロモートし、2D と 3D U-net を接続する重要なコンポーネントとして機能します。 Monoscene は、3D UNet ボトルネックに挿入される 3D Contextual Relation Prior (3D CRP) レイヤーも提案しています。これは、n 方向のボクセル間のセマンティック シーン関係グラフを学習します。これにより、ネットワークにグローバルな受容野が提供され、関係発見メカニズムにより空間意味認識が向上します。 Monoscene の全体的なアーキテクチャを図 10 に示します。
クエリベースのメソッド
3D 空間から学習するもう 1 つの方法には、シーンの表現をキャプチャするための一連のクエリを生成することが含まれます。このアプローチでは、クエリベースの技術を使用してクエリ提案を生成し、それを使用して 3D シーンの包括的な表現を学習します。その後、画像に対するクロスアテンションとセルフアテンションのメカニズムが適用され、学習された表現が改良され強化されます。このアプローチにより、シーンの理解が強化されるだけでなく、3D 空間での正確な再構成と占有予測が可能になります。さらに、クエリベースのアプローチにより、さまざまなデータ ソースとクエリ戦略に基づいて調整および最適化する柔軟性が向上し、ローカルおよびグローバルのコンテキスト情報をより適切に取得して 3D 占有予測表現を容易にすることができます。
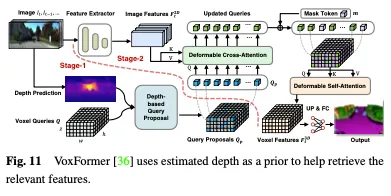
深度は、占有クエリを選択するための貴重な事前分布として使用できます。Voxformer では、推定深度は占有を予測し、関連するクエリを選択するための事前分布として使用されます。変形可能な注意を使用して画像から情報を収集するには、占有クエリのみが使用されます。次に、更新されたクエリ提案とマスクされたトークンが結合されて、ボクセル特徴が再構築されます。 Voxformer は、RGB 画像から 2D 特徴を抽出し、3D ボクセル クエリのまばらなセットを利用してこれらの 2D 特徴にインデックスを付け、カメラ投影行列を使用して 3D 位置を画像ストリームにリンクします。具体的には、ボクセル クエリは、アテンション メカニズムを使用して画像の特徴を 3D ボリュームにクエリするように設計された 3D メッシュ形状の学習可能なパラメータです。フレームワーク全体は、クラスに依存しない提案とクラス固有のセグメント化で構成される 2 段階のカスケードです。ステージ 1 ではクラスに依存しないクエリ提案が生成され、ステージ 2 では MAE のようなアーキテクチャが採用され、情報がすべてのボクセルに伝播されます。最後に、セマンティック セグメンテーションのためにボクセルの特徴がアップサンプリングされます。 VoxFormer の全体的なアーキテクチャを図 11 に示します。
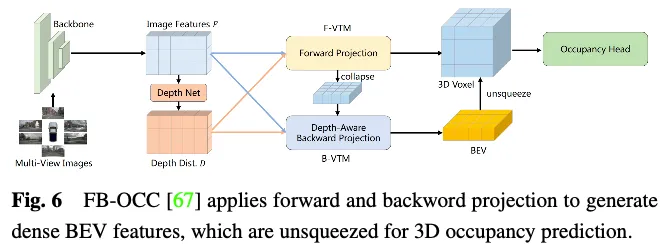
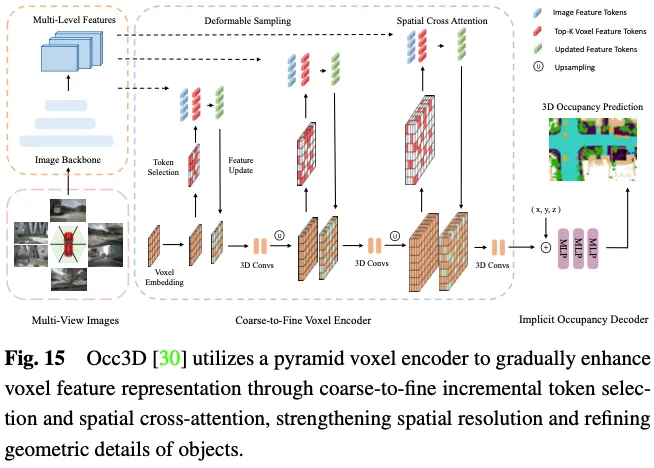
Occ3D nuScenes データセットでの機能拡張手法のパフォーマンスの比較を表 3 に示します。結果は、ボクセル表現を直接扱う手法は、計算中に重大な情報損失を受けないため、多くの場合、優れたパフォーマンスを達成することを示しています。さらに、BEV ベースの手法には、フィーチャ表現のための投影視点が 1 つしかありませんが、鳥瞰図に含まれる豊富な情報と、オクルージョンやスケールの変化に対する感度が低いため、同等のパフォーマンスを達成できます。さらに、複数の相補的なビューから 3D 情報を再構成することで、3 パースペクティブ ビュー (TPV) ベースの方法により、潜在的な幾何学的曖昧さを軽減し、より包括的なシーンのコンテキストをキャプチャできるため、効果的な 3D 占有予測が可能になります。特に、FB-OCC は前方ビュー変換モジュールと後方ビュー変換モジュールの両方を利用し、相互に強化して高品質の純粋な電気自動車の表現を取得し、優れたパフォーマンスを実現します。これは、BEV ベースの方法にも、効果的な機能強化を通じて 3D 占有予測を改善する大きな可能性があることが示されています。
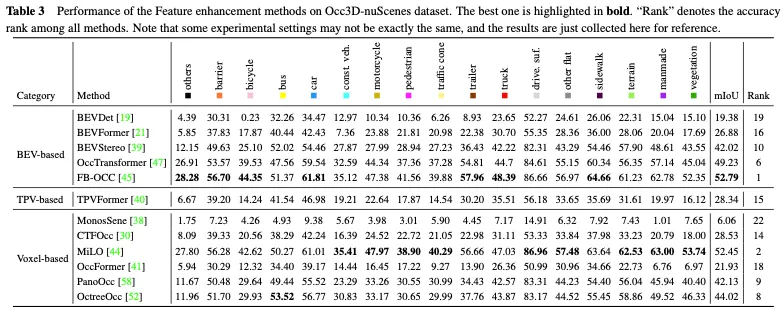
展開しやすい方法
3D 空間から直接占有表現を学習することは、その範囲が広く複雑なデータの性質のため、非常に困難です。 3D ボクセル表現に関連する高次元性と集中的な計算により、学習プロセスには非常に多くのリソースが必要となり、実際の展開アプリケーションには適していません。したがって、展開しやすい 3D 表現を設計する方法は、計算コストを削減し、学習効率を向上させることを目的としています。このセクションでは、3D 空間全体を直接処理するのではなく、正確で効率的な方法の開発に焦点を当て、3D シーンの占有推定における計算上の課題に対処する方法を紹介します。ここで説明する手法には、パースペクティブ分解と粗いものから細かいものへの精密化が含まれており、これらは 3D 占有予測の計算効率を向上させることが最近の研究で実証されています。
遠近法分解方法
3D シーンの特徴から視点情報を分離するか、それを統一表現空間に投影することにより、計算の複雑さが効果的に軽減され、モデルがより堅牢で一般化可能になります。この方法の核となる考え方は、3 次元シーンの表現を視点情報から切り離すことで、特徴学習プロセスで考慮する必要がある変数の数を減らし、計算の複雑さを軽減することです。視点情報を分離すると、モデル全体を再学習することなく、モデルをより適切に一般化し、さまざまな視点変換に適応できるようになります。
3D 空間全体から学習する計算負荷に対処するための一般的なアプローチは、Bird's Eye View (BEV) および Three View View (TPV) 表現を使用することです。 3D 空間をこれらの個別のビュー表現に分解することで、占有予測に不可欠な情報を取得しながら、計算の複雑さが大幅に軽減されます。重要なアイデアは、最初に BEV と TPV の観点から学習し、次にこれらの異なるビューから得られた洞察を組み合わせて完全な 3D 占有情報を復元することです。この透視分解戦略により、3D 空間全体から直接学習する場合と比較して、より効率的かつ効果的な占有率の推定が可能になります。
粗密メソッド
大規模な 3D 空間から直接、高解像度のきめ細かいグローバル ボクセル特徴を学習するのは、時間がかかり、困難です。したがって、いくつかの方法では、粗いものから細かいものへの特徴学習パラダイムを探求し始めています。具体的には、ネットワークは最初に画像から粗い表現を学習し、次にシーン全体のきめの細かい表現を調整して復元します。この 2 段階のプロセスは、シーンの占有率をより正確かつ効率的に予測するのに役立ちます。
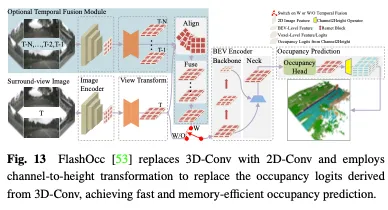
OpenOccupancy は、3D 空間での占有表現を学習するために 2 段階のアプローチを採用しています。図 14 に示すように。
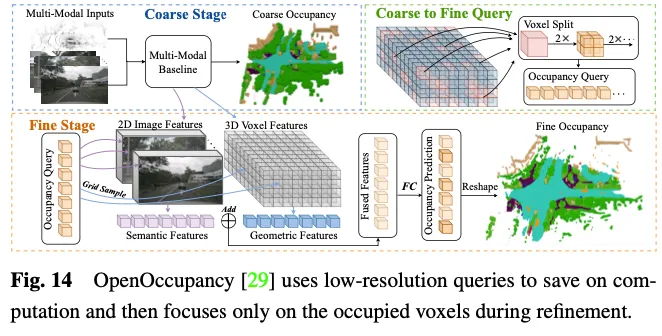
3D 占有率の予測には詳細な幾何学的表現が必要であり、すべての 3D ボクセル マーカーを利用してマルチビュー画像内の ROI を操作するには、多大な計算コストとメモリ コストが発生します。図 15 に示すように、Occ3D は、クロスアテンション計算プロセス中に前景および不確実なボクセル トークンを選択的に選択する増分トークン選択戦略を提案し、それによって効率的なコンピューティングの精度を犠牲にすることなく適応を実現します。具体的には、各ピラミッド層の開始時に、各ボクセルラベルがバイナリ分類器に入力され、分類器をトレーニングするためのバイナリグラウンドトゥルース占有マップによって監視され、ボクセルが空かどうかを予測します。 PanoOcc は、3D 環境のより包括的な理解を促進するために、共同学習フレームワーク内でオブジェクト検出とセマンティック セグメンテーションをシームレスに統合することを提案しています。この方法では、ボクセル クエリを利用してマルチフレームおよびマルチビューの画像から時空間情報を集約し、特徴学習とシーン表現を統合された占有表現に統合します。さらに、占有スパーシティ モジュールを導入することで 3D 空間のスパース性を調査します。これにより、粗いものから細かいものへのアップサンプリング プロセス中に占有率が徐々にスパース化され、ストレージ効率が大幅に向上します。
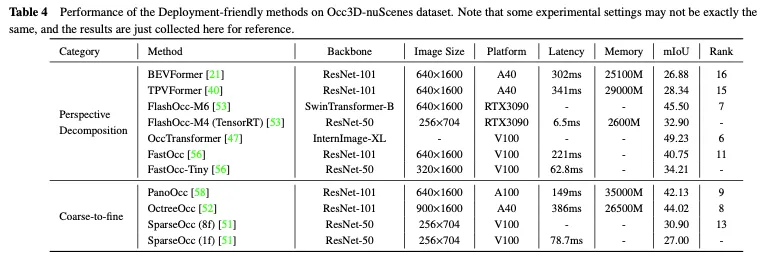
Occ3D nuScenes データセットでのデプロイメントに適したメソッドのパフォーマンスの比較を表 4 に示します。結果はバックボーン、画像サイズ、コンピューティング プラットフォームが異なるさまざまな論文から収集されたものであるため、いくつかの暫定的な結論しか導き出すことができません。一般に、同様の実験設定では、粗密法は情報損失が少ないため、パフォーマンスの点で遠近法分解法よりも優れていますが、通常、遠近法分解はより優れたリアルタイム パフォーマンスとメモリ使用量の削減を示します。さらに、より重いバックボーンを備え、より大きな画像を処理するモデルは、より高い精度を達成できますが、リアルタイム パフォーマンスも低下します。 FlashOcc や FastOcc などのメソッドの軽量バージョンは、実際の展開の要件に近いものですが、精度をさらに向上させる必要があります。展開しやすい手法を実現するために、パースペクティブ分解戦略と粗密戦略の両方が、3D 占有予測の精度を維持しながら計算負荷を継続的に削減するよう努めます。
ラベル効率の良い方法
正確な占有ラベルを作成する既存の方法には、2 つの基本的な手順があります。 1 つ目は、多視点画像に対応する LIDAR 点群を収集し、セマンティック セグメンテーションのためにそれらに注釈を付けることです。もう 1 つは、動的オブジェクトの追跡情報を使用して、複雑なアルゴリズムを通じてマルチフレームの点群を融合することです。どちらの手順も非常に高価であるため、自動運転シナリオで多数のマルチビュー画像を活用する占有ネットワークの機能が制限されます。近年、神経放射線場 (Nerf) が 2 次元画像レンダリングに広く使用されています。 Nerf のような方法で予測された 3D 占有率を 2D マップにプロットし、きめの細かいアノテーションや LIDAR 点群を使用せずに占有ネットワークをトレーニングする方法がいくつかあります。これにより、データ アノテーションのコストが大幅に削減されます。
アノテーション不要のメソッド
SimpleOccupancy は、まずビュー変換を介して画像特徴からシーンの明示的な 3D ボクセル特徴を生成し、次にそれらを Nerf スタイルの方法で 2D 深度マップにレンダリングします。 2D 深度マップは、LIDAR 点群から生成された疎な深度マップによって管理されます。深度マップは、自己監視用のサラウンド画像を合成するためにも使用されます。 UniOcc は 2 つの個別の MLP を使用して、3D ボクセル ロジットをボクセルの密度とボクセルのセマンティック ロジットに変換します。その後、UniOCC は一般的なボリューム レンダリングに従って、図 17 に示すように、マルチビュー デプス マップとセマンティック マップを取得します。これらの 2D マップは、セグメント化された LiDAR 点群から生成されたラベルによって管理されます。 RenderOcc は、マルチビュー画像から NeRF のような 3D ボリューム表現を構築し、2D セマンティックおよび深度ラベルのみを使用して直接 3D 監視を提供できる高度なボリューム レンダリング技術を使用して 2D レンダリングを生成します。この 2D レンダリング監視により、モデルはさまざまなカメラ錐台からの光線の交差を分析することでマルチビューの一貫性を学習し、3D 空間の幾何学的関係をより深く理解します。さらに、隣接するフレームからのレイを利用して現在のフレームのマルチビュー一貫性制約を強化する補助レイの概念を導入し、位置ずれしたレイをフィルタリングするための動的サンプリング トレーニング戦略を開発します。動的カテゴリと静的カテゴリ間の不均衡の問題を解決するために、OccFlowNet はさらに、3D バウンディング ボックスに基づいて各動的ボクセルのシーン フローを予測する占有フローを導入します。ボクセル ストリーミングを使用すると、動的ボクセルを時間フレーム内の正しい位置に移動できるため、レンダリング中に動的オブジェクト フィルタリングを行う必要がなくなります。トレーニング中に、正しく予測されたボクセルと境界ボックス内のボクセルがフローを使用して変換され、時間フレーム内のターゲット位置に位置合わせされ、続いて距離ベースの加重補間を使用してグリッド位置合わせが行われます。
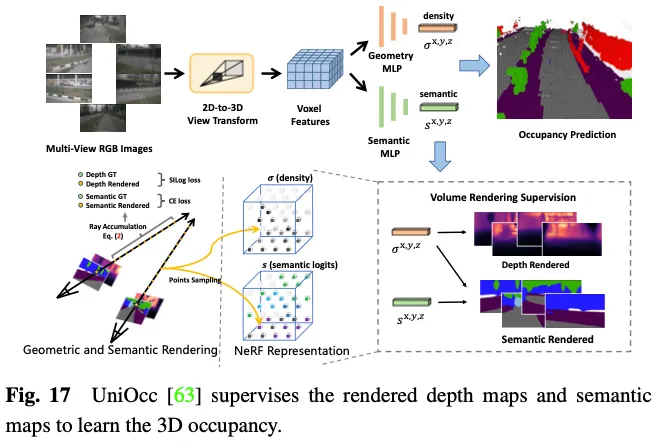
上記のアプローチにより、明示的な 3D 占有注釈の必要性がなくなり、手動注釈の負担が大幅に軽減されます。ただし、レンダリングされたマップを監視するための深度またはセマンティック ラベルを提供するために LIDAR 点群に依然として依存しており、3D 占有予測のための完全に自己監視されたフレームワークをまだ実現できません。
LiDAR フリーのメソッド
OccNerf は、深さとセマンティック ラベルを提供するために LiDAR 点群を利用しません。代わりに、図 18 に示すように、パラメータ化された占有フィールドを使用して無限の屋外シーンを処理し、サンプリング戦略を再編成し、ボリューム レンダリングを使用して占有フィールドをマルチカメラ深度マップに変換します。このマップは最終的にマルチフレームによって管理されます。測光の一貫性。さらに、この方法は、事前にトレーニングされたオープン語彙セマンティック セグメンテーション モデルを利用して 2D セマンティック ラベルを生成し、占有フィールドにセマンティック情報を配信するようにモデルを監視します。舞台裏では、単一ビューの画像シーケンスを使用して運転シーンが再構築されます。入力イメージの錐台特徴を密度フィールドとして扱い、他のビューの合成をレンダリングします。モデル全体は、特別に設計された画像再構成損失を使用してトレーニングされます。 SelfOcc は、BEV または TPV フィーチャの符号付き距離フィールド値を予測して、2D 深度マップをレンダリングします。さらに、元のカラーおよびセマンティック マップもレンダリングされ、マルチビュー画像シーケンスから生成されたラベルによって管理されます。
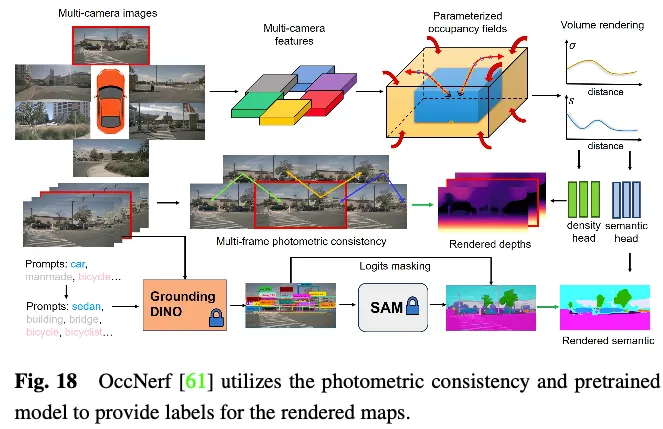
これらのメソッドは、LIDAR 点群からの深度またはセマンティック ラベルの必要性を回避します。代わりに、画像データまたは事前トレーニングされたモデルを活用してこれらのラベルを取得し、3D 占有予測のための真の自己教師型フレームワークを可能にします。これらの方法では、実際のアプリケーションの経験と最も一致するトレーニング パターンを実現できますが、満足のいくパフォーマンスを得るにはさらなる調査が必要です。
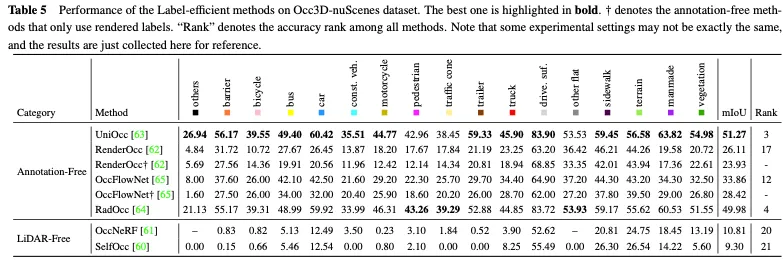
表 5 は、Occ3D nuScenes データセットでのラベル効率の高いメソッドのパフォーマンスの比較を示しています。ほとんどのアノテーションフリーのメソッドは、明示的な 3D 占有監視を補完するものとして 2D レンダリング監視を使用し、一定のパフォーマンス向上を実現します。中でも、UniOcc と RadOcc は、すべての手法の中でそれぞれ 3 位と 4 位という優れたランキングを獲得しており、アノテーション不要のメカニズムが追加の価値ある情報の抽出を促進できることを完全に証明しています。 2D レンダリング監視のみを使用する場合でも、同等の精度を達成でき、明示的な 3D 占有アノテーションのコストを節約できる可能性を示しています。 LIDAR を使用しないアプローチにより、3D 占有予測のための包括的な自己監視フレームワークが確立され、タグや LIDAR データの必要性がさらに排除されます。ただし、点群自体には正確な深さと幾何学的情報が欠けているため、そのパフォーマンスは大幅に制限されます。
将来の展望
上記のアプローチを動機として、私たちは現在の傾向を要約し、データ、方法、およびタスクの自動運転 3D 占有の観点から視覚ベースの視覚を大幅に進歩させる可能性のあるいくつかの重要な研究の方向性を提案します。予測フィールド。
データレベル
十分な実際の運転データを取得することは、自動運転認識システムの全体的な機能を向上させるために重要です。データ生成は、取得コストがかからず、必要に応じてデータの多様性を柔軟に操作できるため、有望なアプローチです。テキストなどの手がかりを利用して、生成される走行データの内容を制御する方法もありますが、空間情報の正確性は保証できません。対照的に、3D Occupancy は、シーンのきめ細かく実用的な表現を提供し、点群、マルチビュー画像、BEV レイアウトと比較して、制御可能なデータ生成と空間情報表示を容易にします。 WoVoGen は、3D 占有を現実的なマルチビュー画像にマッピングできるボリュームを意識した拡散を提案しています。木の追加や車の変更など、3D 占有空間に変更を加えた後、拡散モデルは対応する新しい運転シーンを合成します。修正された 3 次元占有は 3 次元位置情報を記録し、合成データの信頼性を保証します。
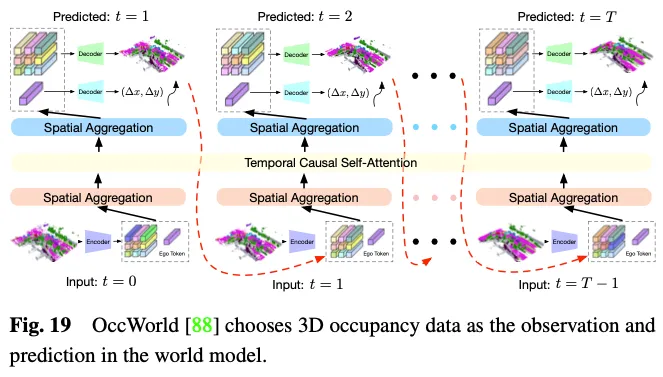
自動運転の世界モデルは、環境入力の観察に基づいてシーン全体を理解し、適切な動的シーン進化データを直接出力するモデルの能力を強化する、シンプルでエレガントなフレームワークを提供します。ワールド モデルでの環境観察として 3D 占有を活用すると、運転シーン データ全体を詳細に専門的に表現できるため、明らかな利点があります。図 19 に示すように、OccWorld はワールド モデルの入力として 3D 占有率を選択し、GPT のようなモジュールを使用して将来の 3D 占有率データがどのようになるかを予測します。 UniWorld は、既製の BEV ベースの 3D 占有モデルを活用していますが、過去のマルチビュー画像を処理して将来の 3D 占有データを予測することによって世界モデルも構築します。しかし、どのような仕組みであっても、生成されたデータと実際のデータの間には領域のギャップが必ず存在します。この問題を解決するために、実現可能なアプローチの 1 つは、3D 占有予測を新しい 3D 人工知能生成コンテンツ (3D AIGC) 手法と組み合わせて、より現実的なシーン データを生成することです。また、別のアプローチは、ドメイン適応手法を組み合わせてフィールド ギャップを狭めることです。
方法論レベル
3D 占有予測方法に関しては、機能強化方法、導入に適した方法、ラベル効率の良い方法など、以前に概説したカテゴリ内でさらなる注意を必要とする継続的な課題が存在します。機能強化方法は、コンピューティング リソースの制御可能な消費を維持しながら、パフォーマンスを大幅に向上させる方向で開発する必要があります。パフォーマンスの低下を最小限に抑えながら、メモリ使用量と遅延を削減するには、展開しやすいアプローチを念頭に置く必要があります。ラベル効率の良い方法は、満足のいくパフォーマンスを達成しながら、高価な注釈の必要性を減らす方向で開発される必要があります。最終的な目標は、機能強化、導入のしやすさ、ラベル付けの効率性を組み合わせて、現実世界の自動運転アプリケーションの期待に応える統一フレームワークを実現することかもしれません。
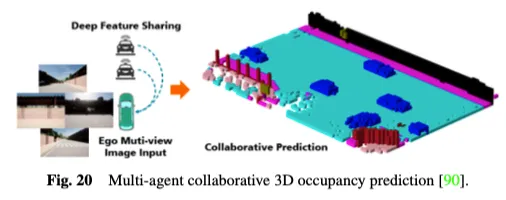
さらに、既存のシングルエージェント自動運転認識システムは、本質的に、オクルージョンに対する感度、長距離センシング能力の不足、視野の制限などの重要な問題を解決できず、包括的な環境認識の達成を困難にしています。シングルエージェントのボトルネックを克服するために、マルチエージェントの協調センシング手法は新たな次元を切り開き、車両が他の交通要素と補完的な情報を共有して周囲環境の全体的な認識を取得できるようになります。図 20 に示すように、マルチエージェント協調 3D 占有予測方法は、3D 占有予測に協調センシングと学習の力を利用し、接続された自動運転車両間で機能を共有することで、3D 道路環境をより深く理解できます。 CoHFF は、初の共同ビジョンベースのセマンティック占有予測フレームワークであり、セマンティック タスク機能と占有タスク機能のハイブリッド融合を通じてローカル 3D セマンティック占有予測を改善し、車両間で共有される圧縮直交注意機能によりパフォーマンスを大幅に向上させます。自転車システム。ただし、この方法では多くの場合、複数のエージェントと同時に通信する必要があり、精度と帯域幅との間の矛盾に直面します。したがって、どのエージェントが最も調整を必要とするかを判断し、精度と速度の最適なバランスを達成するためにコラボレーションが最も価値のある領域を特定することは、興味深い研究の方向性です。
タスクレベル
現在の 3D 占有ベンチマークでは、「自動車」、「歩行者」、「トラック」など、一部のカテゴリには明確なセマンティクスがあります。対照的に、「人工」や「植生」などの他のカテゴリの意味論は曖昧で一般的な傾向があります。これらのカテゴリには広範な未定義のセマンティクスが含まれているため、運転シナリオの詳細な説明を提供するには、より粒度の細かいカテゴリに再分割する必要があります。さらに、これまでに見たことのない未知のカテゴリについては、人間の手がかりに基づいて新しいカテゴリの認識を柔軟に拡張することに対する一般的な障壁とみなされることがよくあります。この問題に対して、オープンボキャブラリータスクは 2D 画像認識で優れたパフォーマンスを示しており、3D 占有予測タスクを改善するために拡張できます。 OVO は、オープンボキャブラリーの 3D 占有予測をサポートするフレームワークを提案しています。フリーズした 2D セグメンタとテキスト エンコーダを利用して、オープンな語彙の意味参照を取得します。次に、3 つの異なるレベルのアライメントを使用して 3D 占有モデルを抽出し、オープンワード予測を実行できるようにします。 POP-3D は、強力な事前トレーニング済み視覚言語モデルの助けを借りて 3 つのモダリティを組み合わせた自己監視型フレームワークを設計しました。ゼロショット占有セグメンテーションやテキストベースの 3D 検索などのオープン辞書タスクを容易にします。
周囲環境の動的な変化を認識することは、自動運転の下流タスクを安全かつ確実に実行するために非常に重要です。 3D 占有予測は、現在の観測に基づいて大規模シーンの高密度の占有表現を提供できますが、ほとんどが現在の 3D 空間を表すことに限定されており、タイムラインに沿った周囲のオブジェクトの将来の状態は考慮されていません。最近、時間情報をさらに考慮し、実際の自動運転シナリオでより実用的な 4D 占有予測タスクを導入するためのいくつかの方法が提案されています。 Cam4Occ は、広く使用されている nuScenes データセットを初めて使用して、4D 占有予測の新しいベンチマークを確立します。このベンチマークには、一般可動オブジェクト (GMO) と一般静的オブジェクト (GSO) の占有予測をそれぞれ評価するためのさまざまな指標が含まれています。さらに、4D 占有予測フレームワークの構築を示すいくつかのベースライン モデルを提供します。オープンボキャブラリーの 3D 占有率予測タスクと 4D 占有率予測タスクは、異なる観点からオープンな動的環境における自動運転の知覚能力を強化することを目的としていますが、依然として最適化のための独立したタスクとして考慮されています。複数のモジュールが一貫性のない最適化目標を持っているモジュール式のタスクベースのパラダイムでは、情報の損失やエラーの蓄積が発生する可能性があります。オープンセットの動的な占有予測とエンドツーエンドの自動運転タスクを組み合わせ、生のセンサー データを制御信号に直接マッピングすることは、有望な研究の方向性です。
以上がOccと自動運転の過去と現在を見てみよう!最初のレビューでは、機能強化/量産展開/アノテーションの効率化という 3 つの主要テーマを包括的にまとめています。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7468
7468
 15
1376
52
77
11
19
26
15
1376
52
77
11
19
26


 Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
Giteeページ静的なWebサイトの展開に失敗しました:単一のファイル404エラーをトラブルシューティングと解決する方法
Apr 04, 2025 pm 11:54 PM
GiteEpages静的Webサイトの展開が失敗しました:404エラーのトラブルシューティングと解像度Giteeを使用する
 H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトの実行方法
Apr 06, 2025 pm 12:21 PM
H5プロジェクトを実行するには、次の手順が必要です。Webサーバー、node.js、開発ツールなどの必要なツールのインストール。開発環境の構築、プロジェクトフォルダーの作成、プロジェクトの初期化、コードの書き込み。開発サーバーを起動し、コマンドラインを使用してコマンドを実行します。ブラウザでプロジェクトをプレビューし、開発サーバーURLを入力します。プロジェクトの公開、コードの最適化、プロジェクトの展開、Webサーバーの構成のセットアップ。
 GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
GOのどのライブラリが大企業によって開発されていますか、それとも有名なオープンソースプロジェクトによって提供されていますか?
Apr 02, 2025 pm 04:12 PM
大企業または有名なオープンソースプロジェクトによって開発されたGOのどのライブラリが開発されていますか? GOでプログラミングするとき、開発者はしばしばいくつかの一般的なニーズに遭遇します...
 Beego ormのモデルに関連付けられているデータベースを指定する方法は?
Apr 02, 2025 pm 03:54 PM
Beego ormのモデルに関連付けられているデータベースを指定する方法は?
Apr 02, 2025 pm 03:54 PM
Beegoormフレームワークでは、モデルに関連付けられているデータベースを指定する方法は?多くのBEEGOプロジェクトでは、複数のデータベースを同時に操作する必要があります。 Beegoを使用する場合...
 Redisストリームを使用してGO言語でメッセージキューを実装する場合、user_idタイプの変換の問題を解決する方法は?
Apr 02, 2025 pm 04:54 PM
Redisストリームを使用してGO言語でメッセージキューを実装する場合、user_idタイプの変換の問題を解決する方法は?
Apr 02, 2025 pm 04:54 PM
redisstreamを使用してGo言語でメッセージキューを実装する問題は、GO言語とRedisを使用することです...
 H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページの生産には継続的なメンテナンスが必要ですか?
Apr 05, 2025 pm 11:27 PM
H5ページは、コードの脆弱性、ブラウザー互換性、パフォーマンスの最適化、セキュリティの更新、ユーザーエクスペリエンスの改善などの要因のため、継続的に維持する必要があります。効果的なメンテナンス方法には、完全なテストシステムの確立、バージョン制御ツールの使用、定期的にページのパフォーマンスの監視、ユーザーフィードバックの収集、メンテナンス計画の策定が含まれます。
 海外バージョンの配送地域データを取得する方法は?利用可能な既製のリソースは何ですか?
Apr 01, 2025 am 08:15 AM
海外バージョンの配送地域データを取得する方法は?利用可能な既製のリソースは何ですか?
Apr 01, 2025 am 08:15 AM
質問の説明:海外バージョンの配送地域データを取得する方法は?既製のリソースはありますか?国境を越えた電子商取引またはグローバル化ビジネスで正確に入手してください...
