

2024 年に、中国ではエンドツーエンドの自動運転に大きな進歩と進歩が見られるでしょうか?

Tesla V12 が北米で広く普及しており、その優れたパフォーマンスによりユーザーの認知度がますます高まっていることを誰もが理解できるわけではありませんが、エンドツーエンドの自動運転は誰もが最も懸念している技術的方向でもあります。自動運転産業。最近、さまざまな業界の一流のエンジニア、プロダクトマネージャー、投資家、メディア関係者と交流する機会があり、誰もがエンドツーエンドの自動運転に非常に興味を持っていることがわかりました。エンドツーエンドの自動運転に対する基本的な理解については、この種の誤解が依然として存在します。国内一流ブランドの写真ありとなしの都市機能、および FSD V11 と V12 の 2 つのバージョンを経験する幸運に恵まれた者として、ここでは私の考えに基づいて現在の開発についていくつかお話したいと思います。この段階では、全員がエンドツーエンドの自動運転に関するよくある誤解について話し合い、これらの問題について私なりの解釈を述べました。
疑問 1: エンドツーエンドの認識、エンドツーエンドの意思決定と計画は、エンドツーエンドの自動運転としてカウントされますか?
センサー入力から計画、その後の制御信号出力までのすべてのステップはエンドツーエンドで導出可能であるため、モデルのトレーニング中に、勾配降下トレーニングや勾配逆伝播を通じてシステム全体を大規模なモデルとしてトレーニングできます。入力から出力までモデルのあらゆる側面で更新および最適化されるため、システム全体の運転挙動は、ユーザーが直接知覚する運転決定軌道に合わせて最適化できます。最近、エンドツーエンドの自動運転を推進する際に、エンドツーエンドのセンシングやエンドツーエンドの意思決定を行っていると主張する友人もいます。実際、これらは両方ともエンドツーエンドとして数えることはできないと思います。これは、純粋なデータ駆動型の認識および純粋なデータ駆動型の意思決定計画と呼ばれるものであり、エンドツーエンドの自動運転とのみ見なされます。
エンドツーエンド計画とも呼ばれる、セキュリティ チェックサム軌道最適化のための従来の方法のハイブリッド戦略と組み合わせた特定のモデルに基づいて意思決定を行う人もいます。さらに、Tesla V12 は純粋に正確なモデル出力制御信号ではなく、いくつかのルール手法を組み合わせたハイブリッド戦略であると信じている人もいます。 http://X.com の有名な Green 氏によると、彼は少し前に、ルールのコードがまだ V12 テクノロジー スタックに存在するというツイートを投稿しました。これについての私の理解は、Green によって発見されたコードは、V12 高速テクノロジー スタックによって保持されている V11 バージョン コードである可能性が高いということです。なぜなら、現在 V12 は実際には元の都市テクノロジー スタックをエンドツーエンドで置き換えるだけであることがわかっているからです。高速では依然として V11 ソリューションが使用されるため、解明されたコード内で通常のコードの一部が見つかっても、V12 が「エンドツーエンド」で間違っていることを意味するわけではありませんが、見つかったコードは高速である可能性があります。コード。実際、2022 年の AI+Day からは、V11 とそれ以前のバージョンがすでにハイブリッド ソリューションであることがわかります。したがって、V12 がすぐに完成したモデルでない場合、ソリューションは以前のバージョンとそれほど変わりません。このように、V12 のパフォーマンスが飛躍的に向上する合理的な説明はありません。テスラのこれまでの計画については、AI+Day での EatElephant の私の解釈を参照してください: Tesla AI Day 2022 -- 世界の言葉の解釈: 彼は自動運転春祭りを分散型 R&D チームと呼び、 AIテクノロジー企業。
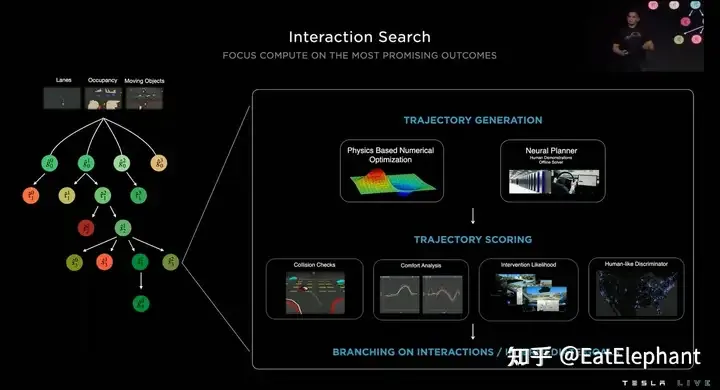
2022 AI Day から判断すると、V11 はすでに NN Planner と混合された計画ソリューションです
一般に、認識の後処理コードであっても、ルール候補の軌道スコアリングであっても、あるいは安全ポケット戦略であっても、ルールが確立されれば、コードが導入され、if else 分岐があると、システム全体の安定した伝送が切り詰められ、トレーニングを通じて全体的な最適化を実現するというエンドツーエンド システムの最大の利点も失われます。
疑問 2: エンドツーエンドは以前のテクノロジーの再発明でしょうか?
もう一つのよくある誤解は、エンドツーエンドとは、これまで蓄積してきた技術を覆し、徹底的に新しい技術革新を行うことであり、テスラがエンドツーエンドの自動運転システムのユーザープッシュを達成したばかりなので、そう思っている人が多いということです。他のメーカーはそれを実装することができません。認識、予測、計画の元のモジュール技術スタックを反復する必要はなく、代わりにエンドツーエンドのシステムに直接入力できます。後発企業の利点から、テスラにすぐに追いつき、さらには追い越すこともできます。確かに、大規模なモデルを使用してセンサー入力から制御信号の計画までのマッピングを完了するのが最も徹底したエンドツーエンドのアプローチです。たとえば、Nvidia の DAVE-2 や Wayve も同様の方法を長い間試してきました。同様の方法を使用しました。この徹底的なエンドツーエンド技術は実際にはブラックボックスに近く、画像や点群などのセンサー入力信号は非常に高次元の入力空間であるため、デバッグや反復的な最適化が困難です。ハンドル角やスロットル制御などの可動ペダルは比較的低次元の出力空間であり、実車試験には全く使用できません。
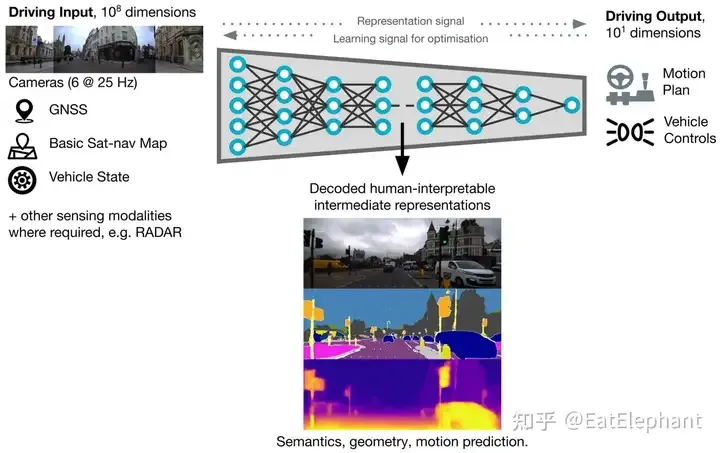
徹底的なエンドツーエンド システムは、モデルの収束とデバッグを支援するために、セマンティック セグメンテーションや深度推定などのいくつかの一般的な補助タスクも使用します
つまり、私たちが実際に見た FSD V12 は、以前の視覚化コンテンツのほぼすべてを保持しており、これは、FSD V12 が元の強力な知覚基盤に基づいてエンドツーエンドでトレーニングされていること、および 2020 年 10 月から始まる FSD の反復が放棄されていないことを示しています。 、V12 の強固な技術基盤となっています。 Andrej Karparthy 氏は以前にも同様の質問に答えていますが、V12 の開発には関与していませんでしたが、これまでの技術の蓄積はすべて放棄されたわけではなく、表舞台から舞台裏に移されただけだと考えています。したがって、ルールコードの一部を段階的に削除することで、独自の技術に基づいてエンドツーエンドのナビゲーションが徐々に実現されます。
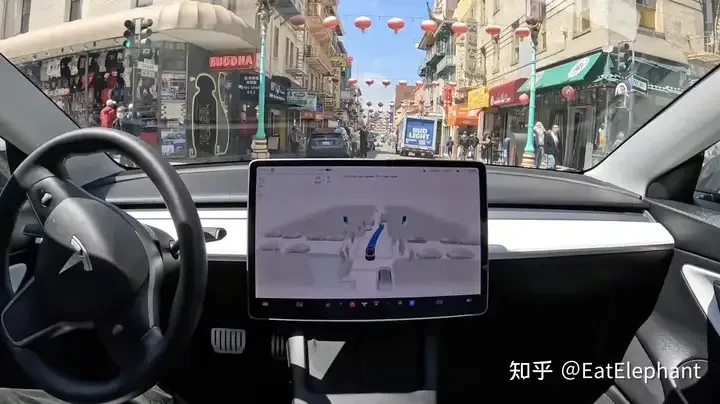
V12 は、FSD のほぼすべての認識を保持し、コーン バレルなどの限られたビジュアル コンテンツのみをキャンセルします
疑問 3: 学術論文のエンドツーエンドを実際の製品に移行できるか?
UniAD が 2023 CVPR Best Paper となったことは、間違いなく、エンドツーエンドの自動運転システムに対する学術コミュニティの高い期待を表しています。テスラが 2021 年に革新的な BEV 視覚認識技術を導入して以来、国内の学術コミュニティは自動運転 BEV 認識に多大な熱意を注ぎ、BEV 手法の性能最適化と実装展開を促進する一連の研究が生まれました。では、エンドツーエンドも、学術界が主導し、産業界が後追いするという同様のルートをたどって、製品へのエンドツーエンドテクノロジーの迅速な反復実装を促進できるでしょうか?比較的難しいと思います。まず第一に、BEV センシングは依然として比較的モジュール化されたテクノロジーであり、よりアルゴリズム レベルであり、エントリー レベルのパフォーマンスにはそれほど大量のデータは必要ありません。高品質の学術オープンソース データ セット Nuscenes のリリースは、BEV センシングに便利な前駆体を提供します。多くの BEV 研究の状況では、Nuscenes で反復された BEV センシング ソリューションは製品レベルの性能要件を満たすことはできませんが、概念実証とモデル選択として非常に参考になります。しかし、学術界には、利用可能な大規模なエンドツーエンドのデータが不足しています。現在、Nuplan の最大のデータセットには 4 都市での 1,200 時間分の実際の車両収集データが含まれていますが、2023 年の財務報告会議でマスク氏は、エンドツーエンドの自動運転について「100 万件のビデオ ケースがトレーニングされており、ほとんど機能しません。」 ; 200 万では少し良くなります; 300 万では「すごい」と感じるでしょう; 1,000 万に達すると、そのパフォーマンスは信じられないほどになります。 Tesla の Autopilot リターン データは一般に 1 分のセグメントであると考えられているため、エントリーレベルの 100 万ビデオのケースは約 16,000 時間であり、これは最大の学術データセットよりも少なくとも 1 桁多いことに注意する必要があります。 nuplan は継続的にデータを収集するため、データの分布と多様性に致命的な欠陥があり、データの大部分は単純なシーンであり、nuplan のような学術的なデータセットを使用しても、かろうじて取得できるバージョンさえ取得できません。電車。
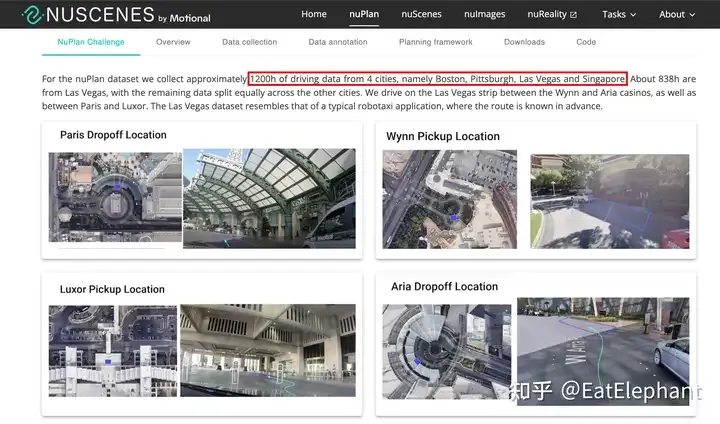
Nuplan データセットはすでに非常に大規模な学術データセットですが、エンドツーエンドのソリューションとしての探索だけでは十分ではない可能性があります
そのため、エンドツーエンドの自律型データセットの大部分が見られます。 UniAD を含む運転 どのソリューションも実際の車両で実行できず、次善の選択肢として開ループ評価に頼るしかありません。開ループ評価指標の信頼性は非常に低く、開ループ評価ではモデルの混乱や因果関係の問題を特定できないため、モデルが履歴パス外挿の使用のみを学習した場合でも、非常に良好な開ループを得ることができます。 2023 年に、Baidu はオープンループ計画評価指標の欠点について議論する AD-MLP (https://arxiv.org/pdf/2305.10430) という論文を発表しました。論文は過去の情報のみを使用し、認識を導入せずに、現在の SOTA の研究に近い非常に優れた開ループ評価指標を取得しました。しかし、誰も目を閉じて車をうまく運転できないことは明らかです。
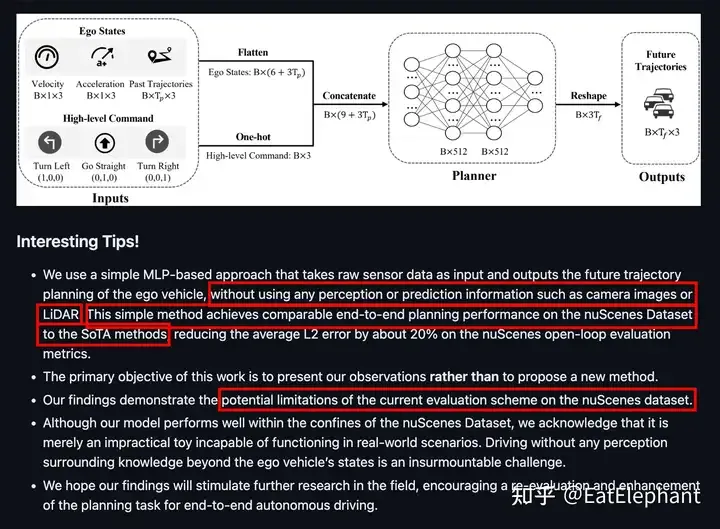
AD MLP は、感覚入力に依存しないことで優れた開ループ指標を実現します。これは、開ループ指標を基準として使用することは実用上ほとんど意味がないことを示しています
それでは、閉ループポリシー検証は次の問題を解決できるでしょうか?オープンループの模倣学習?少なくとも現時点では、学術コミュニティは一般的にエンドツーエンドの研究開発のためにCARLA閉ループシミュレーションシステムに依存していますが、ゲームエンジンに基づいてCARLAによって取得されたモデルも現実世界に転送するのが困難です。
疑問4: エンドツーエンドの自動運転は単なるアルゴリズムの革新なのでしょうか?
結局のところ、エンドツーエンドは単なる新しいアルゴリズムではありません。モジュール式自動運転システムのさまざまなモジュールのモデルは、それぞれのタスクのデータを使用して個別に反復的にトレーニングできますが、エンドツーエンド システムの各機能は同時にトレーニングされるため、トレーニング データが必要になります。非常に一貫性があり、各データは正確でなければなりません。タスクのラベル付けが失敗すると、そのデータをエンドツーエンドのトレーニング タスクで使用することが困難になります。自動ラベル付けパイプラインの速度とパフォーマンス。第 2 に、エンドツーエンド システムでは、エンドツーエンドの意思決定計画出力タスクでより良い結果を達成するために、すべてのモジュールが高いパフォーマンス レベルに達する必要があります。したがって、一般に、エンドツーエンドのデータしきい値は、エンドシステムの要求は個々のモジュールのデータよりもはるかに高く、データのしきい値は絶対量の要件だけでなく、データの分布と多様性も完全に制御できないことを意味します。エンドツーエンドのシステムを開発する場合、さまざまなモデルの顧客を持つ複数のサプライヤーに適応する必要があります。計算能力の限界について、マスク氏は今年 3 月初旬に X.com で、FSD の最大の制限要因は計算能力であると述べ、最近、ほぼ同時に、ボス・マー氏も計算能力の問題が大幅に改善されたと述べました。 , 2024年第1四半期の財務報告会議で、テスラは現在35,000のH100コンピューティングリソースを保有していることを明らかにし、この数が2024年末までに85,000に達することを明らかにしました。 Tesla が非常に強力なコンピューティング パワー エンジニアリング最適化機能を備えていることは疑いの余地がありません。つまり、FSD V12 の現在のレベルに到達するには、35,000 H100 と数十億ドルのインフラ設備投資が必要な前提条件となる可能性が高くなります。テスラほど効率的ではない場合、このしきい値はさらに引き上げられる可能性があります。
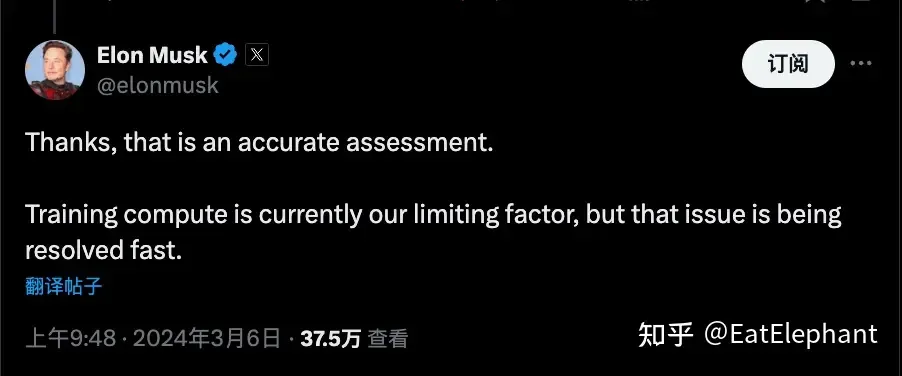
3月初旬、マスク氏は、FSDの反復における主な制限要因はコンピューティングパワーであると述べた

4月初旬、マスク氏は、テスラの今年のコンピューティングパワーへの総投資額は100億米ドルを超えるだろうと述べた
http://X.com にもあります。あるネチズンは、今年の会議で Nvidia 自動車業界幹部の Norm Marks のスクリーンショットを共有しました。そこから、2023 年末までに Nvidia が所有する NV グラフィックス カードの数が増加することがわかります。ヒストグラムでは Tesla が完全に圧倒しています (左の図の右端にある緑色の矢印。中央のテキストでは、この No.1 OEM が所有する NV グラフィックス カードの数が 7,000 DGX ノードを超えていることが説明されています。この OEM は明らかに Tesla です。各ノードは 8 枚のカードとして計算され、23 年末までに、Tesla はおそらく 56,000 枚以上の A100 グラフィックス カードを搭載することになるでしょう。これは、2 位の OEM の 4 倍以上になります。 2024 年に 35,000 枚の新しい H100 カードが購入される)、中国製グラフィックス カードの輸出に対する米国の制限政策と相まって、このコンピューティング能力に追いつくことはさらに困難になります。

Norm Marks が社内でスクリーンショットを共有しました。出典: 、問題をできるだけ早く検出し、データ駆動型の方法で解決し、ルール コードを使用できない場合に迅速に反復する方法は、現在、ほとんどの自律型システムにとって未知の課題です。研究開発チームを推進します。
最後のエンドツーエンドは、現在の自動運転研究開発チームにとって依然として組織変更です。L4 自動運転以降、ほとんどの自動運転チームの組織構造はモジュール化されており、認識グループ、予測グループ、位置決めグループ、計画制御グループ、さらには知覚グループが視覚知覚、レーザー知覚などに分かれています。エンドツーエンドの技術アーキテクチャでは、異なるモジュール間のインターフェイスの障壁が直接取り除かれるため、エンドツーエンドの研究開発チームは新しいテクノロジー パラダイムに適応するためにすべての人的資源を統合する必要があり、これは柔軟性のないチーム組織にとって大きな課題となります。文化。
以上が2024 年に、中国ではエンドツーエンドの自動運転に大きな進歩と進歩が見られるでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1662
1662
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
なぜ自動運転ではガウス スプラッティングが非常に人気があるのに、NeRF は放棄され始めているのでしょうか?
Jan 17, 2024 pm 02:57 PM
上記と著者の個人的な理解 3 次元ガウシアンプラッティング (3DGS) は、近年、明示的な放射線フィールドとコンピューター グラフィックスの分野で出現した革新的なテクノロジーです。この革新的な方法は、数百万の 3D ガウスを使用することを特徴とし、主に暗黙的な座標ベースのモデルを使用して空間座標をピクセル値にマッピングする神経放射線場 (NeRF) 方法とは大きく異なります。明示的なシーン表現と微分可能なレンダリング アルゴリズムにより、3DGS はリアルタイム レンダリング機能を保証するだけでなく、前例のないレベルの制御とシーン編集も導入します。これにより、3DGS は、次世代の 3D 再構築と表現にとって大きな変革をもたらす可能性のあるものとして位置付けられます。この目的を達成するために、私たちは 3DGS 分野における最新の開発と懸念について初めて体系的な概要を提供します。
 自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
自動運転シナリオにおけるロングテール問題を解決するにはどうすればよいでしょうか?
Jun 02, 2024 pm 02:44 PM
昨日の面接で、ロングテール関連の質問をしたかと聞かれたので、簡単にまとめてみようと思いました。自動運転のロングテール問題とは、自動運転車におけるエッジケース、つまり発生確率が低い考えられるシナリオを指します。認識されているロングテール問題は、現在、単一車両のインテリジェント自動運転車の運用設計領域を制限している主な理由の 1 つです。自動運転の基礎となるアーキテクチャとほとんどの技術的問題は解決されており、残りの 5% のロングテール問題が徐々に自動運転の開発を制限する鍵となってきています。これらの問題には、さまざまな断片的なシナリオ、極端な状況、予測不可能な人間の行動が含まれます。自動運転におけるエッジ シナリオの「ロング テール」とは、自動運転車 (AV) におけるエッジ ケースを指します。エッジ ケースは、発生確率が低い可能性のあるシナリオです。これらの珍しい出来事
 カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
カメラかライダーを選択しますか?堅牢な 3D オブジェクト検出の実現に関する最近のレビュー
Jan 26, 2024 am 11:18 AM
0.前面に書かれています&& 自動運転システムは、さまざまなセンサー (カメラ、ライダー、レーダーなど) を使用して周囲の環境を認識し、アルゴリズムとモデルを使用することにより、高度な知覚、意思決定、および制御テクノロジーに依存しているという個人的な理解リアルタイムの分析と意思決定に。これにより、車両は道路標識の認識、他の車両の検出と追跡、歩行者の行動の予測などを行うことで、安全な運行と複雑な交通環境への適応が可能となり、現在広く注目を集めており、将来の交通分野における重要な開発分野と考えられています。 。 1つ。しかし、自動運転を難しくしているのは、周囲で何が起こっているかを車に理解させる方法を見つけることです。これには、自動運転システムの 3 次元物体検出アルゴリズムが、周囲環境にある物体 (位置を含む) を正確に認識し、記述することができる必要があります。
 座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
座標系の変換を本当にマスターしましたか?自動運転と切り離せないマルチセンサーの問題
Oct 12, 2023 am 11:21 AM
最初のパイロットおよび重要な記事では、主に自動運転技術で一般的に使用されるいくつかの座標系と、それらの間の相関と変換を完了し、最終的に統合環境モデルを構築する方法を紹介します。ここでの焦点は、車両からカメラの剛体への変換 (外部パラメータ)、カメラから画像への変換 (内部パラメータ)、および画像からピクセル単位への変換を理解することです。 3D から 2D への変換には、対応する歪み、変換などが発生します。要点:車両座標系とカメラ本体座標系を平面座標系とピクセル座標系に書き換える必要がある 難易度:画像の歪みを考慮する必要がある 歪み補正と歪み付加の両方を画面上で補正する2. はじめに ビジョンシステムには、ピクセル平面座標系 (u, v)、画像座標系 (x, y)、カメラ座標系 ()、世界座標系 () の合計 4 つの座標系があります。それぞれの座標系には関係性があり、
 SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
SIMPL: 自動運転向けのシンプルで効率的なマルチエージェント動作予測ベンチマーク
Feb 20, 2024 am 11:48 AM
原題: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving 論文リンク: https://arxiv.org/pdf/2402.02519.pdf コードリンク: https://github.com/HKUST-Aerial-Robotics/SIMPL 著者単位: 香港科学大学DJI 論文のアイデア: この論文は、自動運転車向けのシンプルで効率的な動作予測ベースライン (SIMPL) を提案しています。従来のエージェントセントとの比較
 自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転と軌道予測についてはこの記事を読めば十分です!
Feb 28, 2024 pm 07:20 PM
自動運転では軌道予測が重要な役割を果たしており、自動運転軌道予測とは、車両の走行過程におけるさまざまなデータを分析し、将来の車両の走行軌跡を予測することを指します。自動運転のコアモジュールとして、軌道予測の品質は下流の計画制御にとって非常に重要です。軌道予測タスクには豊富な技術スタックがあり、自動運転の動的/静的知覚、高精度地図、車線境界線、ニューラル ネットワーク アーキテクチャ (CNN&GNN&Transformer) スキルなどに精通している必要があります。始めるのは非常に困難です。多くのファンは、できるだけ早く軌道予測を始めて、落とし穴を避けたいと考えています。今日は、軌道予測に関するよくある問題と入門的な学習方法を取り上げます。関連知識の紹介 1. プレビュー用紙は整っていますか? A: まずアンケートを見てください。
 エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
エンドツーエンドおよび次世代の自動運転システムと、エンドツーエンドの自動運転に関する誤解について話しましょう。
Apr 15, 2024 pm 04:13 PM
この 1 か月間、いくつかのよく知られた理由により、私は業界のさまざまな教師やクラスメートと非常に集中的な交流をしてきました。この交換で避けられない話題は当然、エンドツーエンドと人気の Tesla FSDV12 です。この機会に、現時点での私の考えや意見を整理し、皆様のご参考とご議論に役立てたいと思います。エンドツーエンドの自動運転システムをどのように定義するか、またエンドツーエンドで解決することが期待される問題は何でしょうか?最も伝統的な定義によれば、エンドツーエンド システムとは、センサーから生の情報を入力し、関心のある変数をタスクに直接出力するシステムを指します。たとえば、画像認識では、従来の特徴抽出 + 分類子方式と比較して、CNN はエンドツーエンドと言えます。自動運転タスクでは、各種センサー(カメラ/LiDAR)からのデータを入力
 FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: 魚眼カメラに基づいた最初のターゲット検出アルゴリズム
Apr 26, 2024 am 11:37 AM
目標検出は自動運転システムにおいて比較的成熟した問題であり、その中でも歩行者検出は最も初期に導入されたアルゴリズムの 1 つです。ほとんどの論文では非常に包括的な研究が行われています。ただし、サラウンドビューに魚眼カメラを使用した距離認識については、あまり研究されていません。放射状の歪みが大きいため、標準のバウンディング ボックス表現を魚眼カメラに実装するのは困難です。上記の説明を軽減するために、拡張バウンディング ボックス、楕円、および一般的な多角形の設計を極/角度表現に探索し、これらの表現を分析するためのインスタンス セグメンテーション mIOU メトリックを定義します。提案された多角形モデルの FisheyeDetNet は、他のモデルよりも優れたパフォーマンスを示し、同時に自動運転用の Valeo 魚眼カメラ データセットで 49.5% の mAP を達成しました。
