

170 の「自己教師あり学習」推奨アルゴリズムをレビューし、HKU が SSL4Rec をリリース: コードとデータベースは完全にオープンソースです。

レコメンデーション システムは、ユーザーの個人的な好みに基づいてカスタマイズされたレコメンデーションを提供するため、情報過多の課題に対処するために重要です。近年、深層学習テクノロジーにより、レコメンデーション システムの開発が大幅に促進され、ユーザーの行動や好みに関する洞察が向上しました。
しかし、従来の教師あり学習手法は、データの疎性の問題により、実際のアプリケーションでは課題に直面しており、ユーザーのパフォーマンスを効果的に学習する能力が制限されています。
この問題を保護し、克服するために、自己教師あり学習 (SSL) テクノロジーが生徒に適用されます。このテクノロジーは、データの固有の構造を使用して監視信号を生成し、ラベル付きデータに完全には依存しません。
この方法では、ラベルのないデータから意味のある情報を抽出し、データが不足している場合でも正確な予測と推奨を行うことができる推奨システムを使用します。

記事アドレス: https://arxiv.org/abs/2404.03354
オープンソースデータベース: https://github.com/HKUDS/Awesome-SSLRec-Papers
オープンソースコード ライブラリ: https://github.com/HKUDS/SSLRec
この記事では、レコメンダー システム用に設計された自己教師あり学習フレームワークをレビューし、170 以上の関連論文の詳細な分析を実施します。私たちは、SSL がさまざまなシナリオでレコメンデーション システムをどのように強化できるかを包括的に理解するために、9 つの異なるアプリケーション シナリオを調査しました。
各ドメインについて、対照学習、生成学習、敵対的学習など、さまざまな自己教師あり学習パラダイムについて詳しく説明し、SSL がさまざまな状況でレコメンデーション システムのパフォーマンスをどのように向上できるかを示します。
1 推奨システム
レコメンダー システムに関する研究では、協調フィルタリング、シーケンス推奨、複数動作推奨など、さまざまなシナリオのさまざまなタスクをカバーしています。これらのタスクには、さまざまなデータ パラダイムと目標があります。ここでは、さまざまなレコメンデーション タスクの具体的なバリエーションには触れずに、まず一般的な定義を示します。レコメンデーション システムには、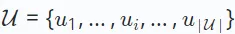 で示されるユーザー セットと
で示されるユーザー セットと 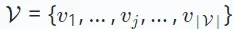 で示されるアイテム セットの 2 つの主要なセットがあります。
で示されるアイテム セットの 2 つの主要なセットがあります。
次に、インタラクション行列 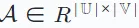 を使用して、ユーザーとアイテムの間の記録されたインタラクションを表します。この行列では、ユーザー ui が項目 vj と対話した場合、行列のエントリ Ai,j には値 1 が割り当てられ、それ以外の場合は 0 が割り当てられます。
を使用して、ユーザーとアイテムの間の記録されたインタラクションを表します。この行列では、ユーザー ui が項目 vj と対話した場合、行列のエントリ Ai,j には値 1 が割り当てられ、それ以外の場合は 0 が割り当てられます。
インタラクションの定義は、さまざまなコンテキストやデータセット (映画の視聴、電子商取引サイトのクリック、購入など) に適応させることができます。
さらに、さまざまな推奨タスクには、対応する関係として記録されるさまざまな補助観察データがあります。
そして、ソーシャルレコメンデーションでは、X には友情などのユーザーレベルの関係が含まれます。上記の定義に基づいて、推奨モデルは、任意のユーザー u とアイテム v の間の嗜好スコアを正確に推定することを目的として、予測関数 f(⋅) を最適化します。
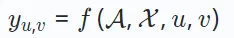
嗜好スコア yu,v は、ユーザー u とitem v 相互作用の可能性。
このスコアに基づいて、レコメンダー システムは、推定された嗜好スコアに基づいてアイテムのランク付けされたリストを提供することにより、インタラクションされていないアイテムを各ユーザーに推奨できます。このレビューでは、さまざまな推奨シナリオにおける (A,X) のデータ形式と、その中での自己教師あり学習の役割をさらに調査します。
2 レコメンダー システムにおける自己教師あり学習
ここ数年、ディープ ニューラル ネットワークは教師あり学習で優れたパフォーマンスを発揮し、コンピューター ビジョン、自然言語処理、レコメンデーション システムなどのさまざまな分野に反映されています。ただし、ラベル付きデータへの依存度が高いため、教師あり学習はラベルのスパース性への対処という課題に直面しており、これはレコメンダー システムでよく見られる問題でもあります。
この制限に対処するために、データ自体を学習ラベルとして利用する自己教師あり学習が有望な方法として登場しました。レコメンダー システムにおける自己教師あり学習には、対照学習、生成学習、敵対的学習という 3 つの異なるパラダイムが含まれます。
2.1 対照学習
優れた自己教師あり学習方法である対照学習の主な目標は、データから強化されたさまざまなビュー間の一貫性を最大化することです。レコメンデーション システムの対比学習では、次の損失関数を最小限に抑えることが目標です:
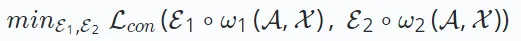
E∗∘ω∗ は対比ビュー作成操作を表し、対比学習に基づくさまざまなレコメンデーション アルゴリズム作成プロセスが異なります。各ビューの構築は、データ拡張プロセス ω∗ (拡張グラフ内のノード/エッジが含まれる場合があります) と埋め込みエンコード プロセス E∗ で構成されます。
を最小化する の目標は、ビュー間の一貫性を最大化する堅牢なエンコード関数を取得することです。ビュー間のこの一貫性は、相互情報の最大化やインスタンスの識別などの方法によって実現できます。
の目標は、ビュー間の一貫性を最大化する堅牢なエンコード関数を取得することです。ビュー間のこの一貫性は、相互情報の最大化やインスタンスの識別などの方法によって実現できます。
2.2 生成学習
生成学習の目標は、データの構造とパターンを理解して意味のある表現を学習することです。欠落または破損した入力データを再構築するディープ エンコーダー デコーダー モデルを最適化します。
エンコーダー  は入力から潜在表現を作成し、デコーダー
は入力から潜在表現を作成し、デコーダー 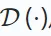 はエンコーダー出力から元のデータを再構築します。目標は、次のように、再構成されたデータと元のデータの差を最小限に抑えることです:
はエンコーダー出力から元のデータを再構築します。目標は、次のように、再構成されたデータと元のデータの差を最小限に抑えることです:
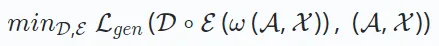
ここで、 ω はマスキングや摂動などの操作を表します。 D∘E は、出力を再構築するためのエンコードおよびデコードのプロセスを表します。最近の研究では、エンコーダとデコーダをセットアップせずにデータを効率的に再構築するデコーダのみのアーキテクチャも導入されました。このアプローチは、再構成に単一のモデル (Transformer など) を使用し、通常、生成学習に基づいてシリアル化された推奨事項に適用されます。損失関数 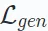 の形式は、連続データの平均二乗誤差やカテゴリデータのクロスエントロピー損失などのデータ型によって異なります。
の形式は、連続データの平均二乗誤差やカテゴリデータのクロスエントロピー損失などのデータ型によって異なります。
2.3 敵対的学習
敵対的学習は、ジェネレーター G(⋅) を使用して高品質の出力を生成し、識別子 Ω(⋅) を含むトレーニング方法です。本物か生成されたものです。生成学習とは異なり、敵対的学習は、ディスクリミネーターをだますために高品質の出力を生成するジェネレーターの能力を向上させるために競合的相互作用を使用するディスクリミネーターを含む点で異なります。
したがって、敵対的学習の学習目標は次のように定義できます:
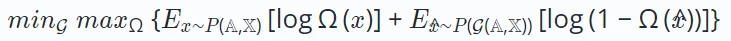
ここで、変数 x は基礎となるデータ分布から取得された実際のサンプルを表し、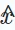 はジェネレーター G(⋅) によって生成された合成サンプルを表します。トレーニング中に、ジェネレーターとディスクリミネーターの両方が競争的な相互作用を通じて能力を向上させます。最終的に、ジェネレーターは下流のタスクに有益な高品質の出力を生成するよう努めます。
はジェネレーター G(⋅) によって生成された合成サンプルを表します。トレーニング中に、ジェネレーターとディスクリミネーターの両方が競争的な相互作用を通じて能力を向上させます。最終的に、ジェネレーターは下流のタスクに有益な高品質の出力を生成するよう努めます。
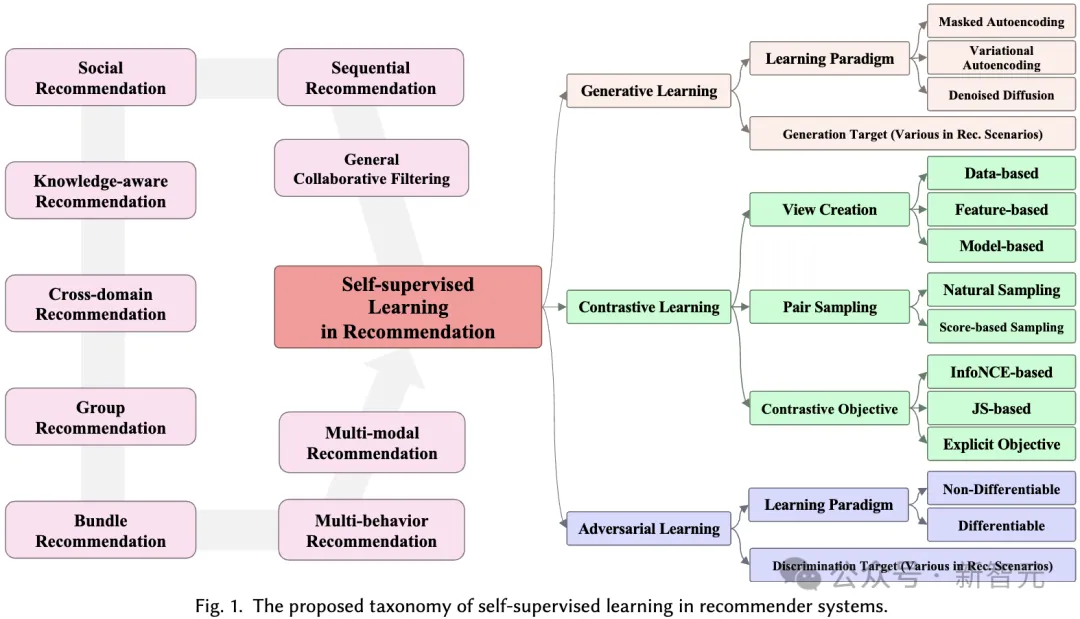
3 分類法
このセクションでは、推奨システムにおける自己教師あり学習の応用のための包括的な分類システムを提案します。前述したように、自己教師あり学習パラダイムは、対照学習、生成学習、敵対学習の 3 つのカテゴリに分類できます。したがって、私たちの分類システムはこれら 3 つのカテゴリに基づいて構築されており、各カテゴリについてより深い洞察を提供します。
3.1 レコメンデーションシステムにおける対照学習
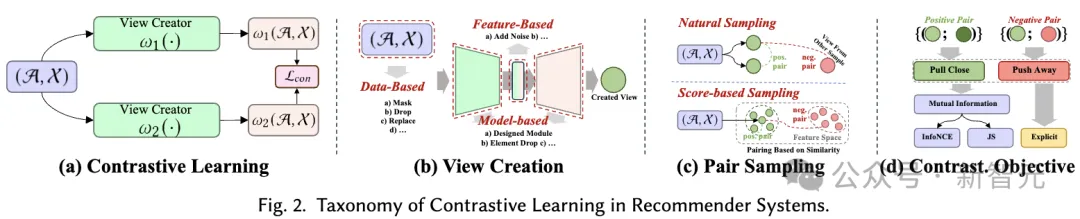
対照学習 (CL) の基本原理は、異なるビュー間の一貫性を最大化することです。したがって、対比学習を適用する際に考慮すべき 3 つの主要なコンポーネント (ビューの作成、一貫性を最大化するためのビューのペアリング、および一貫性の最適化) で構成されるビュー中心の分類法を提案します。
ビューの作成。 モデルが焦点を当てているさまざまなデータの側面を強調するビューを作成します。グローバルな協調情報を組み合わせてグローバルな関係を処理するレコメンデーション システムの能力を向上させたり、ランダム ノイズを導入してモデルの堅牢性を強化したりできます。
入力データ (グラフ、シーケンス、入力特徴など) の強化はデータレベルのビューの作成と見なされますが、推論中の潜在特徴の強化は特徴レベルのビューの作成と見なされます。我々は、基本データレベルからニューラルモデルレベルまでのビュー作成手法を含む階層分類システムを提案します。
- データレベル データベース: 対照学習に基づく推奨システムでは、入力データを強化することによって多様なビューが作成されます。これらの強化されたデータ ポイントは、モデルを通じて処理されます。さまざまなビューから取得された出力埋め込みは最終的にペアになり、比較学習に使用されます。強化方法は推奨シナリオによって異なります。たとえば、グラフ データはノード/エッジ ドロップを使用して強化でき、シーケンスはマスキング、クロッピング、置換を使用して強化できます。
- 特徴ベース: データからビューを直接生成することに加えて、一部のメソッドでは、モデル転送プロセスでエンコードされた隠れた特徴の強化も考慮されます。これらの隠れた特徴には、Transformer のグラフ ニューラル ネットワーク レイヤーまたはトークン ベクトルのノード埋め込みが含まれる場合があります。さまざまな強化手法を複数回適用したり、ランダムな摂動を導入したりすることで、モデルの最終出力をさまざまなビューとして表示できます。
- モデルベース: データレベルおよび機能レベルの拡張機能はノンパラメトリックであるため、非適応的です。したがって、モデルを使用してさまざまなビューを生成する方法もあります。これらのビューには、モデル設計に基づいた特定の情報が含まれています。たとえば、インテント分離ニューラル モジュールはユーザーの意図をキャプチャでき、ハイパーグラフ モジュールはグローバルな関係をキャプチャできます。
ペアサンプリング。 ビュー作成プロセスでは、データ内のサンプルごとに少なくとも 2 つの異なるビューが生成されます。対照学習の核心は、他のビューを遠ざけながら、特定のビューの調整を最大化する (つまり、それらを近づける) ことです。
これを行うために重要なのは、近づけるべき肯定的なサンプルのペアを特定し、否定的なサンプルのペアを形成する他のビューを特定することです。この戦略はペア サンプリングと呼ばれ、主に 2 つのペア サンプリング方法で構成されます:
- 自然サンプリング: ペア サンプリングの一般的な方法は、ヒューリスティックではなく直接的な方法であり、これを自然サンプリングと呼びます。ポジティブ サンプル ペアは同じデータ サンプルによって生成された異なるビューから形成され、ネガティブ サンプル ペアは異なるデータ サンプルのビューから形成されます。グラフ全体から派生したグローバル ビューなどの中心ビューが存在する場合、ローカルとグローバルの関係により、正のサンプル ペアが自然に形成されることもあります。この方法は、ほとんどの対照学習推奨システムで広く使用されています。
- スコアベースのサンプリング: ペア サンプリングのもう 1 つの方法は、スコアベースのサンプリングです。このアプローチでは、モジュールがサンプル ペアのスコアを計算して、陽性または陰性のサンプル ペアを決定します。たとえば、2 つのビュー間の距離を使用して、正のサンプルと負のサンプルのペアを決定できます。あるいは、ビューにクラスタリングを適用することもできます。この場合、正のペアは同じクラスタ内にあり、負のペアは異なるクラスタ内にあります。アンカー ビューの場合、ポジティブ サンプル ペアが決定されると、残りのビューは当然ネガティブ ビューとみなされ、指定されたビューと組み合わせてネガティブ サンプル ペアを作成し、押しのけることができます。
対照的な目標。 対照学習の学習目標は、陽性サンプルのペア間の相互情報を最大化することであり、これにより学習推奨モデルのパフォーマンスを向上させることができます。相互情報量を直接計算することは現実的ではないため、通常、対照学習では実現可能な下限が学習目標として使用されます。ただし、ポジティブペアを近づけるという明確な目標もあります。
- InfoNCE ベース: InfoNCE はノイズ対比推定の変形です。その最適化プロセスは、ポジティブなサンプル ペアを近づけ、ネガティブなサンプル ペアを遠ざけることを目的としています。
- JS ベース: InfoNCE を使用して相互情報量を推定することに加えて、Jensen-Shannon 発散を使用して下限を推定することもできます。導出された学習目標は、InfoNCE と標準バイナリ クロスエントロピー損失を組み合わせたものに似ており、正と負のサンプルのペアに適用されます。
- 明示的な目標: InfoNCE ベースと JS ベースの目標は両方とも、理論的に保証されている相互情報量自体を最大化するために、相互情報量の推定下限を最大化することを目的としています。さらに、陽性サンプルのペアを直接整列させるための、サンプル ペア内の平均二乗誤差の最小化やコサイン類似度の最大化などの明確な目的もあります。これらの目標は明示的な目標と呼ばれます。
3.2 レコメンダーシステムにおける生成学習

生成自己教師あり学習では、主な目標は実際のデータ分布の尤度推定を最大化することです。これにより、学習された意味のある表現でデータ内の基礎となる構造とパターンをキャプチャできるようになり、下流のタスクで使用できるようになります。私たちの分類システムでは、さまざまな生成学習ベースの推奨方法を区別するために、生成学習パラダイムと生成目標という 2 つの側面を考慮します。
生成学習パラダイム。 推奨の文脈では、生成学習を使用した自己教師あり手法は 3 つのパラダイムに分類できます:
- マスクされた自動エンコーディング: マスクされた自動エンコーダーでは、学習手順はマスク再構成アプローチに従います。モデルは部分的な観測から完全なデータを再構築します。
- 変分オートエンコーダ: 変分オートエンコーダは、尤度推定を最大化し、理論的な保証を持つ別の 生成方法です。通常、正規ガウス分布に従う潜在因子に入力データをマッピングすることが含まれます。次にモデルは、サンプリングされた潜在因子に基づいて入力データを再構築します。
- ノイズ除去拡散: ノイズ除去拡散は、ノイズプロセスを反転することによって新しいデータサンプルを生成する生成モデルです。順方向プロセスでは、ガウス ノイズが元のデータに追加され、複数のステップを経て、一連のノイズのあるバージョンが作成されます。逆のプロセス中に、モデルはノイズの多いバージョンからノイズを除去することを学習し、徐々に元のデータを復元します。
世代ターゲット。 生成学習では、どのデータのパターンが生成されたラベルとしてみなされるかは、意味のある補助的な自己教師あり信号をもたらすために考慮する必要があるもう 1 つの問題です。一般に、生成目標は方法や推奨シナリオによって異なります。たとえば、シーケンスの推奨では、シーケンス内のアイテム間の関係をシミュレートすることを目的として、シーケンス内のアイテムを生成ターゲットにすることができます。インタラクティブなグラフ推奨では、グラフ内の高レベルのトポロジー相関を取得することを目的として、生成ターゲットをグラフ内のノード/エッジにすることができます。
3.3 レコメンドシステムにおける敵対的学習
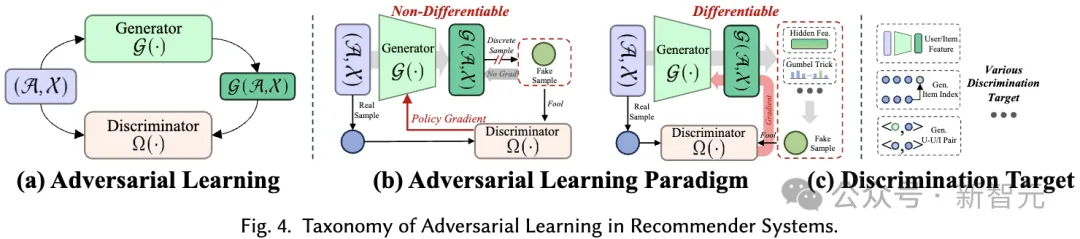
レコメンダーシステムの敵対的学習において、弁別器は、生成された偽サンプルを本物のサンプルから区別する上で重要な役割を果たします。生成学習と同様に、私たちが提案する分類システムは、学習パラダイムと識別目標:
敵対的学習パラダイムの 2 つの観点からレコメンダー システムにおける敵対的学習方法をカバーします。 レコメンダー システムでは、識別器の識別損失を微分可能な方法で生成器に逆伝播できるかどうかに応じて、敵対的学習は 2 つの異なるパラダイムで構成されます。
- 微分可能な敵対的学習 (微分可能 AL): 最初の方法には、連続空間で表現されたオブジェクトが含まれ、弁別器の勾配は最適化のためにジェネレーターに自然に逆伝播できます。このアプローチは、微分可能な敵対的学習と呼ばれます。
- 非微分可能敵対学習 (非微分可能 AL): 別の方法には、レコメンデーション システムの出力、特に推奨される製品の特定が含まれます。ただし、推奨結果は離散的であるため、逆伝播が困難になり、識別器の勾配を生成器に直接伝播できない微分不可能なケースが形成されます。この問題を解決するために、強化学習とポリシー勾配が導入されます。この場合、ジェネレーターは、以前のインタラクションに基づいて商品を予測することにより、環境とインタラクションするエージェントとして機能します。ディスクリミネーターは報酬関数として機能し、ジェネレーターの学習をガイドする報酬信号を提供します。ディスクリミネーターの報酬は、レコメンデーションの品質に影響を与えるさまざまな要素を強調するように定義されており、生成されたサンプルではなく実際のサンプルに高い報酬を割り当てるように最適化されており、ジェネレーターが高品質のレコメンデーションを生成するように導きます。
差別の対象。 異なる推奨アルゴリズムにより、ジェネレーターは異なる入力を生成し、それが識別のためにディスクリミネーターに供給されます。このプロセスは、現実に近い高品質のコンテンツを生成するジェネレーターの能力を強化することを目的としています。特定の識別目標は、特定の推奨タスクに基づいて設計されます。
3.4 多様な推奨シナリオ
このレビューでは、9 つの異なる推奨シナリオからのさまざまな自己教師あり学習方法の設計について詳しく説明します。これらの 9 つの推奨シナリオは次のとおりです。詳細については記事をお読みください):
- 一般協調フィルタリング (一般協調フィルタリング) - これはレコメンデーション システムの最も基本的な形式であり、主にユーザーとアイテムの間のインタラクション データに依存してパーソナリティの推奨事項を生成します。
- 逐次推奨 (逐次推奨) - ユーザーの次に考えられるインタラクティブなアイテムを予測することを目的として、アイテムとユーザーのインタラクションの時系列を考慮します。
- ソーシャルレコメンデーション - ソーシャルネットワーク内のユーザー関係情報を組み合わせて、よりパーソナライズされたレコメンデーションを提供します。
- 知識を意識した推奨 - ナレッジ グラフなどの構造化された知識を使用して、推奨システムのパフォーマンスを強化します。
- クロスドメインレコメンデーション - あるドメインから学習したユーザー設定を別のドメインに適用して、レコメンデーションの結果を向上させます。
- グループのおすすめ - 個々のユーザーではなく、共通の特性や興味を持つグループにおすすめを提供します。
- バンドルの推奨 - 通常、プロモーションやパッケージサービスのために、アイテムのグループを全体として推奨します。
- 複数の行動の推奨事項 (複数の行動の推奨事項) - 閲覧、購入、評価など、アイテムに対するユーザーの複数のインタラクティブな行動を考慮します。
- マルチモーダルレコメンデーション - テキスト、画像、サウンドなどのアイテムの複数のモーダル情報を組み合わせて、より豊富なレコメンデーションを提供します。
4 結論
この記事では、170 を超える論文の詳細な分析を用いて、レコメンデーション システムにおける自己教師あり学習 (SSL) の応用についての包括的なレビューを提供します。この記事では、9 つの推奨シナリオをカバーする自己教師あり分類システムを提案し、対照学習、生成学習、敵対学習の 3 つの SSL パラダイムについて詳細に説明し、将来の研究の方向性について説明しました。
私たちは、データ疎性の処理とレコメンデーション システムのパフォーマンス向上における SSL の重要性を強調し、大規模な言語モデルをレコメンデーション システム、適応型動的レコメンデーション環境に統合し、SSL パラダイムの理論的基盤を確立する可能性を指摘します。 . 研究の方向性。このレビューが研究者に貴重なリソースを提供し、新しい研究アイデアを刺激し、推奨システムのさらなる開発を促進することを願っています。
以上が170 の「自己教師あり学習」推奨アルゴリズムをレビューし、HKU が SSL4Rec をリリース: コードとデータベースは完全にオープンソースです。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのストリングをオブジェクトに変換するためにどのような方法が使用されますか?
Apr 07, 2025 pm 09:39 PM
vue.jsのオブジェクトに文字列を変換する場合、標準のjson文字列にはjson.parse()が推奨されます。非標準のJSON文字列の場合、文字列は正規表現を使用して処理し、フォーマットまたはデコードされたURLエンコードに従ってメソッドを削減できます。文字列形式に従って適切な方法を選択し、バグを避けるためにセキュリティとエンコードの問題に注意してください。
 Vue Paginationの使用方法
Apr 08, 2025 am 06:45 AM
Vue Paginationの使用方法
Apr 08, 2025 am 06:45 AM
ページネーションは、パフォーマンスとユーザーエクスペリエンスを向上させるために、大きなデータセットを小さなページに分割するテクノロジーです。 VUEでは、次の組み込みメソッドを使用してページを使用できます。ページの総数を計算します。TotalPages()トラバーサルページ番号:V-For Directive on Currentページを設定します。
 MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLインストール後にデータベースのパフォーマンスを最適化する方法
Apr 08, 2025 am 11:36 AM
MySQLパフォーマンスの最適化は、インストール構成、インデックス作成、クエリの最適化、監視、チューニングの3つの側面から開始する必要があります。 1。インストール後、INNODB_BUFFER_POOL_SIZEパラメーターやclose query_cache_sizeなど、サーバーの構成に従ってmy.cnfファイルを調整する必要があります。 2。過度のインデックスを回避するための適切なインデックスを作成し、説明コマンドを使用して実行計画を分析するなど、クエリステートメントを最適化します。 3. MySQL独自の監視ツール(ShowProcessList、ShowStatus)を使用して、データベースの健康を監視し、定期的にデータベースをバックアップして整理します。これらの手順を継続的に最適化することによってのみ、MySQLデータベースのパフォーマンスを改善できます。
 インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
インストール後にMySQLの使用方法
Apr 08, 2025 am 11:48 AM
この記事では、MySQLデータベースの操作を紹介します。まず、MySQLWorkBenchやコマンドラインクライアントなど、MySQLクライアントをインストールする必要があります。 1. mysql-uroot-pコマンドを使用してサーバーに接続し、ルートアカウントパスワードでログインします。 2。CreatedAtaBaseを使用してデータベースを作成し、データベースを選択します。 3. createTableを使用してテーブルを作成し、フィールドとデータ型を定義します。 4. INSERTINTOを使用してデータを挿入し、データをクエリし、更新することでデータを更新し、削除してデータを削除します。これらの手順を習得することによってのみ、一般的な問題に対処することを学び、データベースのパフォーマンスを最適化することでMySQLを効率的に使用できます。
 Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
Laravelの地理空間:インタラクティブマップと大量のデータの最適化
Apr 08, 2025 pm 12:24 PM
700万のレコードを効率的に処理し、地理空間技術を使用したインタラクティブマップを作成します。この記事では、LaravelとMySQLを使用して700万を超えるレコードを効率的に処理し、それらをインタラクティブなマップの視覚化に変換する方法について説明します。最初の課題プロジェクトの要件:MySQLデータベースに700万のレコードを使用して貴重な洞察を抽出します。多くの人は最初に言語をプログラミングすることを検討しますが、データベース自体を無視します。ニーズを満たすことができますか?データ移行または構造調整は必要ですか? MySQLはこのような大きなデータ負荷に耐えることができますか?予備分析:キーフィルターとプロパティを特定する必要があります。分析後、ソリューションに関連している属性はわずかであることがわかりました。フィルターの実現可能性を確認し、検索を最適化するためにいくつかの制限を設定しました。都市に基づくマップ検索
 MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLを解決する方法は開始できません
Apr 08, 2025 pm 02:21 PM
MySQLの起動が失敗する理由はたくさんあり、エラーログをチェックすることで診断できます。一般的な原因には、ポートの競合(ポート占有率をチェックして構成の変更)、許可の問題(ユーザー許可を実行するサービスを確認)、構成ファイルエラー(パラメーター設定のチェック)、データディレクトリの破損(テーブルスペースの復元)、INNODBテーブルスペースの問題(IBDATA1ファイルのチェック)、プラグインロード障害(エラーログのチェック)が含まれます。問題を解決するときは、エラーログに基づいてそれらを分析し、問題の根本原因を見つけ、問題を防ぐために定期的にデータをバックアップする習慣を開発する必要があります。
 リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニア(プラットフォーム)がサークルが必要です
Apr 08, 2025 pm 12:27 PM
リモートシニアバックエンジニアの求人事業者:サークル場所:リモートオフィスジョブタイプ:フルタイム給与:$ 130,000- $ 140,000職務記述書サークルモバイルアプリケーションとパブリックAPI関連機能の研究開発に参加します。ソフトウェア開発ライフサイクル全体をカバーします。主な責任は、RubyonRailsに基づいて独立して開発作業を完了し、React/Redux/Relay Front-Endチームと協力しています。 Webアプリケーションのコア機能と改善を構築し、機能設計プロセス全体でデザイナーとリーダーシップと緊密に連携します。肯定的な開発プロセスを促進し、反復速度を優先します。 6年以上の複雑なWebアプリケーションバックエンドが必要です
 MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLの主な鍵はヌルにすることができます
Apr 08, 2025 pm 03:03 PM
MySQLプライマリキーは、データベース内の各行を一意に識別するキー属性であるため、空にすることはできません。主キーが空になる可能性がある場合、レコードを一意に識別することはできません。これにより、データの混乱が発生します。一次キーとして自己挿入整数列またはUUIDを使用する場合、効率やスペース占有などの要因を考慮し、適切なソリューションを選択する必要があります。
