

JavaScriptのデータ構造とアルゴリズムの詳しい説明 stack_javascriptスキル

前の記事 では、次のリストを紹介しました。このリストは最も単純な構造ですが、より複雑な構造を扱いたい場合は、リストが単純すぎるため、何らかの種類のリストが必要です。 of と List はスタックに似ていますが、より複雑なデータ構造です。データはスタックの最上部でのみ追加または削除できるため、スタックは効率的なデータ構造であり、この操作は高速かつ簡単に実装できます。
1: スタック上の操作。
スタックは特殊な種類のリストです。スタック内の要素には、リストの一方の端 (スタックの最上部) からのみアクセスできます。例えば、飲食店で食器を洗うときは、まず天板を洗ってから、山盛りのお皿の上にネジを締めるだけです。スタックは、「後入れ先出し」(LIFO) と呼ばれるデータ構造です。
スタックは後入れ先出しの性質を持っているため、スタックの最上位にない要素にはアクセスできません。スタックの最下位の要素を取得するには、上の要素を取得する必要があります。最初に削除されました。スタック上で実行できる 2 つの主な操作は、要素をスタックにプッシュすることと、要素をスタックからポップすることです。 Push() メソッドを使用してスタックにプッシュし、pop() メソッドを使用してスタックからポップアウトできます。 Pop() メソッドはスタックの最上位の要素にアクセスできますが、このメソッドを呼び出した後、スタックの最上位の要素はスタックから完全に削除されます。よく使用されるもう 1 つのメソッドは、スタックの最上位要素のみを削除せずに返す Peak() です。
スタックへのプッシュとポップの実際の図は次のとおりです:
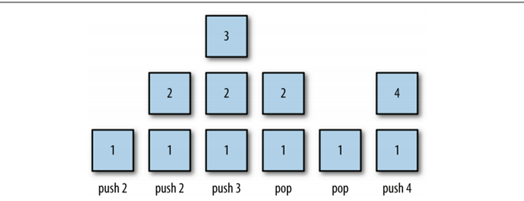
push()、pop()、peek() がスタックの 3 つの主要なメソッドですが、スタックには他のメソッドとプロパティもあります。以下のように:
clear(): スタック内のすべての要素をクリアします。
length(): スタック内の要素の数を記録します。
2: スタックの実装は次のとおりです:
次のようにスタック クラスのメソッドを実装することから始めます。
This.dataStore = [];
This.top = 0;
}
次のメソッドもあります:push()、pop()、peek()、clear()、length();
1. Push() メソッド; 新しい要素をスタックにプッシュするときは、配列内の変数の先頭に対応する位置に保存する必要があり、その後、先頭の値が次の値を指すように 1 増加されます。配列内の位置。次のコード:
This.dataStore[this.top] = 要素;
}
return this.dataStore[--this.top];
}
}
4. length() メソッド 場合によっては、スタック内に要素がいくつあるかを知る必要があります。次のコードに示すように、変数 top の値を返すことでスタック内の要素の数を返すことができます。
5. clear(); 場合によっては、スタックをクリアしたい場合は、次のコードを使用して変数の先頭の値を 0 に設定します。
コードをコピー
関数クリア() {
this.top = 0;
}
以下のすべてのコード:
関数 Stack() {
This.dataStore = [];
This.top = 0;
}
Stack.prototype = {
//新しい要素をスタックにプッシュします
プッシュ: function(element) {
This.dataStore[this.top] = 要素;
}、
// スタックの最上位要素にアクセスすると、スタックの最上位要素は完全に削除されます
ポップ: function(){
return this.dataStore[--this.top];
}、
// 配列の先頭から 1 番目の要素、つまりスタックの先頭の要素を返します
ピーク: function(){
return this.dataStore[this.top - 1];
}、
//スタックに格納される要素の数
長さ: function(){
return this.top;
}、
//スタックをクリア
; クリア: function(){
This.top = 0;
}
};
デモの例は次のとおりです:
var stack = new Stack();
stack.push("a");
stack.push("b");
stack.push("c");
console.log(stack.length()) // 3
console.log(stack.peek()); // c
var Popped = stack.pop();
console.log(ポップ); // c
console.log(stack.peek()) // b
stack.push("d");
console.log(stack.peek()); // d
stack.clear();
console.log(stack.length()) // 0
console.log(stack.peek()) // 未定義
以下では、5! などの階乗関数の再帰定義を実装できます。 5の階乗です! = 5 * 4 * 3 * 2 * 1;
次のコード:
var s = 新しいスタック();
; while(n > 1) {
s.push(n--);
}
var product = 1;
While(s.length() > 0) {
製品 *= s.pop();
}
製品を返品する;
}
console.log(fact(5));

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7625
7625
 15
1389
52
89
11
31
138
15
1389
52
89
11
31
138

 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 Java 関数比較を使用して複雑なデータ構造を比較する
Apr 19, 2024 pm 10:24 PM
Java 関数比較を使用して複雑なデータ構造を比較する
Apr 19, 2024 pm 10:24 PM
Java で複雑なデータ構造を使用する場合、Comparator を使用して柔軟な比較メカニズムを提供します。具体的な手順には、コンパレータ クラスの定義、比較ロジックを定義するための比較メソッドの書き換えが含まれます。コンパレータインスタンスを作成します。 Collections.sort メソッドを使用して、コレクションとコンパレータのインスタンスを渡します。
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 Javaのデータ構造とアルゴリズム: 詳細な説明
May 08, 2024 pm 10:12 PM
Javaのデータ構造とアルゴリズム: 詳細な説明
May 08, 2024 pm 10:12 PM
データ構造とアルゴリズムは Java 開発の基礎です。この記事では、Java の主要なデータ構造 (配列、リンク リスト、ツリーなど) とアルゴリズム (並べ替え、検索、グラフ アルゴリズムなど) について詳しく説明します。これらの構造は、スコアを保存するための配列、買い物リストを管理するためのリンク リスト、再帰を実装するためのスタック、スレッドを同期するためのキュー、高速検索と認証のためのツリーとハッシュ テーブルの使用など、実際の例を通じて説明されています。これらの概念を理解すると、効率的で保守しやすい Java コードを作成できるようになります。
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
 PHP データ構造: AVL ツリーのバランス、効率的で秩序あるデータ構造の維持
Jun 03, 2024 am 09:58 AM
PHP データ構造: AVL ツリーのバランス、効率的で秩序あるデータ構造の維持
Jun 03, 2024 am 09:58 AM
AVL ツリーは、高速かつ効率的なデータ操作を保証するバランスのとれた二分探索ツリーです。バランスを達成するために、左回転と右回転の操作を実行し、バランスに反するサブツリーを調整します。 AVL ツリーは高さバランシングを利用して、ツリーの高さがノード数に対して常に小さくなるようにすることで、対数時間計算量 (O(logn)) の検索操作を実現し、大規模なデータ セットでもデータ構造の効率を維持します。
 グローバルグラフ強化に基づくニュース推奨アルゴリズム
Apr 08, 2024 pm 09:16 PM
グローバルグラフ強化に基づくニュース推奨アルゴリズム
Apr 08, 2024 pm 09:16 PM
著者 | Wang Hao によるレビュー | Chonglou ニュース アプリは、人々が日常生活で情報ソースを入手する重要な方法です。 2010年頃、海外ニュースアプリの人気はZiteやFlipboardなどがあり、国内ニュースアプリの人気は主に4大ポータルでした。 Toutiaoに代表される新時代のニュースレコメンド商品の人気により、ニュースアプリは新時代を迎えました。テクノロジー企業に関しては、どの企業であっても、高度なニュース推奨アルゴリズム技術を習得していれば、基本的に技術レベルでの主導権と発言権を握ることになる。今日は、RecSys2023 Best Long Paper Nomination Award の論文、GoingBeyondLocal:GlobalGraph-EnhancedP を見てみましょう。
