

python抓取到的网页源代码有类似\u51a0\u7434,请问如何转换成中文?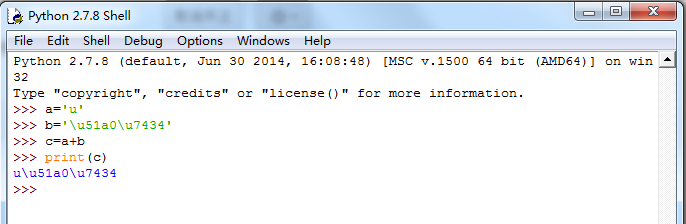
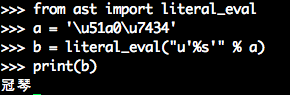
 谢邀,多熟悉下标准库(7.8. codecs)吧:
谢邀,多熟悉下标准库(7.8. codecs)吧:>>> s = r'\u51a0\u7434'
>>> print s
\u51a0\u7434
>>> s.decode('unicode_escape')
u'\u51a0\u7434'
>>> print s.decode('unicode_escape')
冠琴
'u\u51a0\u7434'可不是u'\u51a0\u7434',题主自己不明白自己搜到的东西的意思, @刘项 也不知道题主在问什么(发现经提示后已经知道题主在问什么了)。这个51a0和7434代表16进制的4个字节,这是unicode编码,python肯定有提供数字到字符或者字节数组到字符串的函数,你得先把他们处理成数字,然后再转。
Javascript: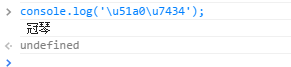 这个实际上是Unicode码。Unicode用16位整数表示世界上存在的任何一种字符,即任何一个能显示的字符都对应Unicode中的一个整数。
这个实际上是Unicode码。Unicode用16位整数表示世界上存在的任何一种字符,即任何一个能显示的字符都对应Unicode中的一个整数。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



