

解决进程间共享内存,由于某个进程异常退出导致死锁问题

发现问题 继这篇Blog 解决Nginx和Fpm-Php等内部多进程之间共享数据问题 发完后,进程间共享内存又遇到了新的问题 昨天晚上QP同学上线后,早上看超时报表发现有一台前端机器访问QP超时,比其他前端机器高出了几个数量级,前端的机器都是同构的 难道是这台机器
发现问题
继这篇Blog 解决Nginx和Fpm-Php等内部多进程之间共享数据问题 发完后,进程间共享内存又遇到了新的问题
昨天晚上QP同学上线后,早上看超时报表发现有一台前端机器访问QP超时,比其他前端机器高出了几个数量级,前端的机器都是同构的
难道是这台机器系统不正常?查看系统状态也没有任何异常,统计了一下超时日志,发现超时都发生在早上QP服务重启的过程中,正常情况下服务重启时,ClusterMap 会保证流量的正常分配
难道是ClusterMap有问题?去ClusterMap Server端看了一下,一切正常
难道是订阅者客户端有问题吗?随便找了一台正常的机器和有问题的这台机器对比,查看下日志也没有发现问题,使用查询工具检查这两台机器订阅者代理写的共享内存,发现工具读取共享内存返回的结果不一致,这就更奇怪了,都是相同的订阅者,一台机器有问题一台没问题
难道Server端给他们的消息不一致?去Server端把订阅者的机器列表都打了出来,发现了有问题的机器根本不在订阅者列表里面,说明这台机器没有订阅,貌似有点线索了,我下线了一台它订阅的QP机器验证,发现共享内部数据没有更新,pstack一下这个进程,发现内部的更新线程一直在等锁,导致共享内存数据一直无法更新,gdb跟进去之后,_lock.data.nr_readers一直为1,说明一直有一个读进程占着锁导致写进程无法进入,遍历了所有fpm-php的读进程发现都没有占着锁,这说明在读进程在获得锁后没来得及释放就挂掉了
测试
现在问题已经确认就是获得读锁后进程异常退出导致的,我写个测试程序复现这个问题
(! 2293)-> cat test/read_shared.cpp
#include
SharedUpdateData* _sharedUpdateData = NULL;
cm_sub::CMMapFile* _mmapFile = NULL;
int32_t initSharedMemRead(const std::string& mmap_file_path)
{
_mmapFile = new (std::nothrow) cm_sub::CMMapFile();
if (_mmapFile == NULL || !_mmapFile->open(mmap_file_path.c_str(), FILE_OPEN_WRITE) )
{
return -1;
}
_sharedUpdateData = (SharedUpdateData*)_mmapFile->offset2Addr(0);
return 0;
}
int main(int argc, char** argv)
{
if (initSharedMemRead(argv[1]) != 0) return -1;
int cnt = 100;
while (cnt > 0)
{
pthread_rwlock_rdlock( &(_sharedUpdateData->_lock));
fprintf(stdout, "version = %ld, readers = %u\n",
_sharedUpdateData->_version, _sharedUpdateData->_lock.__data.__nr_readers);
if (cnt == 190)
{
exit(0);
}
sleep(1);
pthread_rwlock_unlock( &(_sharedUpdateData->_lock));
-- cnt;
usleep(100*1000);
}
delete _mmapFile;
}
(! 2293)-> cat test/write_shared.cpp
#include
SharedUpdateData* _sharedUpdateData = NULL;
cm_sub::CMMapFile* _mmapFile = NULL;
int32_t initSharedMemWrite(const char* mmap_file_path)
{
_mmapFile = new (std::nothrow) cm_sub::CMMapFile();
if ( _mmapFile == NULL || !_mmapFile->open(mmap_file_path, FILE_OPEN_WRITE, 1024) )
{
return -1;
}
_sharedUpdateData = (SharedUpdateData *)_mmapFile->offset2Addr(0);
madvise(_sharedUpdateData, 1024, MADV_SEQUENTIAL);
pthread_rwlockattr_t attr;
memset(&attr, 0x0, sizeof(pthread_rwlockattr_t));
if (pthread_rwlockattr_init(&attr) != 0 || pthread_rwlockattr_setpshared(&attr, PTHREAD_PROCESS_SHARED) != 0)
{
return -1;
}
pthread_rwlock_init( &(_sharedUpdateData->_lock), &attr);
_sharedUpdateData->_updateTime = autil::TimeUtility::currentTime();
_sharedUpdateData->_version = 0;
return 0;
}
int main()
{
if (initSharedMemWrite("data.mmap") != 0) return -1;
int cnt = 200;
while (cnt > 0)
{
pthread_rwlock_wrlock( &(_sharedUpdateData->_lock));
++ _sharedUpdateData->_version;
fprintf(stdout, "version = %ld, readers = %u\n",
_sharedUpdateData->_version, _sharedUpdateData->_lock.__data.__nr_readers);
sleep(1);
pthread_rwlock_unlock( &(_sharedUpdateData->_lock));
-- cnt;
usleep(100*1000);
}
delete _mmapFile;
}
无论是读进程还是写进程,获取锁后来不及释放就挂掉都会有这样的问题
如何解决
问题已经复现,想想如何用一个好的办法解决,在网上找了一遍,针对读写锁没有什么好的解决办法,只能在逻辑上自己解决,能想到的是使用超时机制,即写进程内部增加一个超时时间,如果写进程到了这个时间还是不能获得锁,就认为死锁,将读进程的计数减1,这是一个暴力的解决办法,不解释了,如果谁有好的解决办法指导我下
看下读写锁的代码,读写锁和互斥锁相比,更适合用在读多写少的场景,如果读进程需要锁住时间久,就更合适使用读写锁了,我的应该场景是,读多写少,读写时间都非常短;暂时认为互斥锁和读写锁性能差别应该不大,其实读写锁内部同样使用了互斥锁,只不过是锁的时间比较短,锁住互斥区,进去看下是否有人正在写,然后就释放了,
需要注意的是,读写锁默认是写优先的,也就是说当正在写,或者进入写队列准备写时,读锁都是加不上的,需要等待
好,那我们看看互斥锁能否解决我们的问题,互斥锁内部有一个属性叫Robust锁
设置锁为Robust锁: pthread_mutexattr_setrobust_np
The robustness attribute defines the behavior when the owner
of a mutex dies. The value of robustness could be either
PTHREAD_MUTEX_ROBUST_NP or PTHREAD_MUTEX_STALLED_NP, which
are defined by the header . The default value of
the robustness attribute is PTHREAD_MUTEX_STALLED_NP.
When the owner of a mutex with the PTHREAD_MUTEX_STALLED_NP
robustness attribute dies, all future calls to
pthread_mutex_lock(3C) for this mutex will be blocked from
progress in an unspecified manner.
修复非一致的Robust锁: pthread_mutex_consistent_np
A consistent mutex becomes inconsistent and is unlocked if
its owner dies while holding it, or if the process contain-
ing the owner of the mutex unmaps the memory containing the
mutex or performs one of the exec(2) functions. A subsequent
owner of the mutex will acquire the mutex with
pthread_mutex_lock(3C), which will return EOWNERDEAD to
indicate that the acquired mutex is inconsistent.
The pthread_mutex_consistent_np() function should be called
while holding the mutex acquired by a previous call to
pthread_mutex_lock() that returned EOWNERDEAD.
Since the critical section protected by the mutex could have
been left in an inconsistent state by the dead owner, the
caller should make the mutex consistent only if it is able
to make the critical section protected by the mutex con-
sistent.
简单来说就是当发现EOWNERDEAD时,pthread_mutex_consistent_np函数内部会判断这个互斥锁是不是Robust锁,如果是,并且他OwnerDie了,那么他会把锁的owner设置成自己的进程ID,这样这个锁又可以恢复可用,很简单吧
锁释放是可以解决了,但是通过共享内存在进程间共享数据时,还有一点是需要注意的,就是数据的正确性,即完整性,进程共享不同与线程,如果是一个进程中的多个线程,那么进程异常退出了,其他线程也同时退出了,进程间共享都是独立的,如果一个写线程在写共享数据的过程中,异常退出,导致写入的数据不完整,读进程读取时就会有读到不完整数据的问题,其实数据完整性非常好解决,只需要在共享内存中加一个完成标记就好了,锁住共享区后,写数据,写好之后标记为完成,就可以了,读进程在读取时判断一下完成标记
测试代码见:
(! 2295)-> cat test/read_shared_mutex.cpp
#include
SharedUpdateData* _sharedUpdateData = NULL;
cm_sub::CMMapFile* _mmapFile = NULL;
int32_t initSharedMemRead(const std::string& mmap_file_path)
{
_mmapFile = new (std::nothrow) cm_sub::CMMapFile();
if (_mmapFile == NULL || !_mmapFile->open(mmap_file_path.c_str(), FILE_OPEN_WRITE) )
{
return -1;
}
_sharedUpdateData = (SharedUpdateData*)_mmapFile->offset2Addr(0);
return 0;
}
int main(int argc, char** argv)
{
if (argc != 2) return -1;
if (initSharedMemRead(argv[1]) != 0) return -1;
int cnt = 10000;
int ret = 0;
while (cnt > 0)
{
ret = pthread_mutex_lock( &(_sharedUpdateData->_lock));
if (ret == EOWNERDEAD)
{
fprintf(stdout, "%s: version = %ld, lock = %d, %u, %d\n",
strerror(ret),
_sharedUpdateData->_version,
_sharedUpdateData->_lock.__data.__lock,
_sharedUpdateData->_lock.__data.__count,
_sharedUpdateData->_lock.__data.__owner);
ret = pthread_mutex_consistent_np( &(_sharedUpdateData->_lock));
if (ret != 0)
{
fprintf(stderr, "%s\n", strerror(ret));
pthread_mutex_unlock( &(_sharedUpdateData->_lock));
continue;
}
}
fprintf(stdout, "version = %ld, lock = %d, %u, %d\n",
_sharedUpdateData->_version,
_sharedUpdateData->_lock.__data.__lock,
_sharedUpdateData->_lock.__data.__count,
_sharedUpdateData->_lock.__data.__owner);
sleep(5);
pthread_mutex_unlock( &(_sharedUpdateData->_lock));
usleep(500*1000);
-- cnt;
}
fprintf(stdout, "go on\n");
delete _mmapFile;
}
(! 2295)-> cat test/write_shared_mutex.cpp
#include
SharedUpdateData* _sharedUpdateData = NULL;
cm_sub::CMMapFile* _mmapFile = NULL;
int32_t initSharedMemWrite(const char* mmap_file_path)
{
_mmapFile = new (std::nothrow) cm_sub::CMMapFile();
if ( _mmapFile == NULL || !_mmapFile->open(mmap_file_path, FILE_OPEN_WRITE, 1024) )
{
return -1;
}
_sharedUpdateData = (SharedUpdateData *)_mmapFile->offset2Addr(0);
madvise(_sharedUpdateData, 1024, MADV_SEQUENTIAL);
pthread_mutexattr_t attr;
memset(&attr, 0x0, sizeof(pthread_mutexattr_t));
if (pthread_mutexattr_init(&attr) != 0 || pthread_mutexattr_setpshared(&attr, PTHREAD_PROCESS_SHARED) != 0)
{
return -1;
}
if (pthread_mutexattr_setrobust_np(&attr, PTHREAD_MUTEX_ROBUST_NP) != 0)
{
return -1;
}
pthread_mutex_init( &(_sharedUpdateData->_lock), &attr);
_sharedUpdateData->_version = 0;
return 0;
}
int main()
{
if (initSharedMemWrite("data.mmap") != 0) return -1;
int cnt = 200;
int ret = 0;
while (cnt > 0)
{
ret = pthread_mutex_lock( &(_sharedUpdateData->_lock));
if (ret == EOWNERDEAD)
{
fprintf(stdout, "%s: version = %ld, lock = %d, %u, %d\n",
strerror(ret),
_sharedUpdateData->_version,
_sharedUpdateData->_lock.__data.__lock,
_sharedUpdateData->_lock.__data.__count,
_sharedUpdateData->_lock.__data.__owner);
ret = pthread_mutex_consistent_np( &(_sharedUpdateData->_lock));
if (ret != 0)
{
fprintf(stderr, "%s\n", strerror(ret));
pthread_mutex_unlock( &(_sharedUpdateData->_lock));
continue;
}
}
++ _sharedUpdateData->_version;
fprintf(stdout, "version = %ld, lock = %d, %u, %d\n", _sharedUpdateData->_version,
_sharedUpdateData->_lock.__data.__lock,
_sharedUpdateData->_lock.__data.__count,
_sharedUpdateData->_lock.__data.__owner);
usleep(1000*1000);
pthread_mutex_unlock( &(_sharedUpdateData->_lock));
-- cnt;
usleep(500*1000);
}
delete _mmapFile;
}
BTW:我们都知道加锁是有开销的,不仅仅是互斥导致的等待开销,还有加锁过程都是有系统调用到内核态的,这个过程开销也很大,有一种互斥锁叫Futex锁(Fast User Mutex),Linux从2.5.7版本开始支持Futex,快速的用户层面的互斥锁,Fetux锁有更好的性能,是用户态和内核态混合使用的同步机制,如果没有锁竞争的时候,在用户态就可以判断返回,不需要系统调用,
当然任何锁都是有开销的,能不用尽量不用,使用双Buffer,释放链表,引用计数,都可以在一定程度上替代锁的使用
原文地址:解决进程间共享内存,由于某个进程异常退出导致死锁问题, 感谢原作者分享。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7348
7348
 15
1627
14
1352
52
1265
25
1214
29
15
1627
14
1352
52
1265
25
1214
29

 大規模なメモリの最適化。コンピュータが 16g/32g のメモリ速度にアップグレードしても変化がない場合はどうすればよいですか?
Jun 18, 2024 pm 06:51 PM
大規模なメモリの最適化。コンピュータが 16g/32g のメモリ速度にアップグレードしても変化がない場合はどうすればよいですか?
Jun 18, 2024 pm 06:51 PM
機械式ハード ドライブまたは SATA ソリッド ステート ドライブの場合、NVME ハード ドライブの場合は、ソフトウェアの実行速度の向上を感じられない場合があります。 1. レジストリをデスクトップにインポートし、新しいテキスト ドキュメントを作成し、次の内容をコピーして貼り付け、1.reg として保存し、右クリックしてマージしてコンピュータを再起動します。 WindowsRegistryEditorVersion5.00[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SessionManager\MemoryManagement]"DisablePagingExecutive"=d
 サムスン、HBM4メモリでの普及が期待される16層ハイブリッドボンディング積層プロセス技術検証完了を発表
Apr 07, 2024 pm 09:19 PM
サムスン、HBM4メモリでの普及が期待される16層ハイブリッドボンディング積層プロセス技術検証完了を発表
Apr 07, 2024 pm 09:19 PM
報告書によると、サムスン電子幹部のキム大宇氏は、2024年の韓国マイクロエレクトロニクス・パッケージング協会年次総会で、サムスン電子は16層ハイブリッドボンディングHBMメモリ技術の検証を完了すると述べた。この技術は技術検証を通過したと報告されています。同報告書では、今回の技術検証が今後数年間のメモリ市場発展の基礎を築くとも述べている。 DaeWooKim氏は、「サムスン電子がハイブリッドボンディング技術に基づいて16層積層HBM3メモリの製造に成功した。メモリサンプルは正常に動作する。将来的には、16層積層ハイブリッドボンディング技術がHBM4メモリの量産に使用されるだろう」と述べた。 ▲画像出典 TheElec、以下同 ハイブリッドボンディングは、既存のボンディングプロセスと比較して、DRAMメモリ層間にバンプを追加する必要がなく、上下層の銅と銅を直接接続する。
 関係者によると、サムスン電子とSKハイニックスは2026年以降に積層型モバイルメモリを商品化する予定
Sep 03, 2024 pm 02:15 PM
関係者によると、サムスン電子とSKハイニックスは2026年以降に積層型モバイルメモリを商品化する予定
Sep 03, 2024 pm 02:15 PM
9月3日の当ウェブサイトのニュースによると、韓国メディアetnewsは昨日(現地時間)、サムスン電子とSKハイニックスの「HBM類似」積層構造モバイルメモリ製品が2026年以降に商品化されると報じた。関係者によると、韓国のメモリ大手2社はスタック型モバイルメモリを将来の重要な収益源と考えており、エンドサイドAIに電力を供給するために「HBMのようなメモリ」をスマートフォン、タブレット、ラップトップに拡張する計画だという。このサイトの以前のレポートによると、Samsung Electronics の製品は LPwide I/O メモリと呼ばれ、SK Hynix はこのテクノロジーを VFO と呼んでいます。両社はほぼ同じ技術的ルート、つまりファンアウト パッケージングと垂直チャネルを組み合わせたものを使用しました。 Samsung Electronics の LPwide I/O メモリのビット幅は 512
 Lexar が Ares Wings of War DDR5 7600 16GB x2 メモリ キットを発売: Hynix A-die パーティクル、1,299 人民元
May 07, 2024 am 08:13 AM
Lexar が Ares Wings of War DDR5 7600 16GB x2 メモリ キットを発売: Hynix A-die パーティクル、1,299 人民元
May 07, 2024 am 08:13 AM
5月6日のこのウェブサイトのニュースによると、LexarはAres Wings of WarシリーズのDDR57600CL36オーバークロックメモリを発売しました。16GBx2セットは50元のデポジットで5月7日0:00に予約販売されます。 1,299元。 Lexar Wings of War メモリは、Hynix A-die メモリ チップを使用し、Intel XMP3.0 をサポートし、次の 2 つのオーバークロック プリセットを提供します: 7600MT/s: CL36-46-46-961.4V8000MT/s: CL38-48-49 -1001.45V放熱に関しては、このメモリ セットには厚さ 1.8 mm の全アルミニウム放熱ベストが装備されており、PMIC 独自の熱伝導性シリコン グリース パッドが装備されています。メモリは 8 つの高輝度 LED ビーズを使用し、13 の RGB 照明モードをサポートします。
 MIT の最新傑作: GPT-3.5 を使用して時系列異常検出の問題を解決する
Jun 08, 2024 pm 06:09 PM
MIT の最新傑作: GPT-3.5 を使用して時系列異常検出の問題を解決する
Jun 08, 2024 pm 06:09 PM
今日は、MIT が先週公開した記事を紹介します。GPT-3.5-turbo を使用して時系列異常検出の問題を解決し、時系列異常検出における LLM の有効性を最初に検証しました。プロセス全体に微調整はなく、GPT-3.5-turbo は異常検出に直接使用されます。この記事の核心は、時系列を GPT-3.5-turbo が認識できる入力に変換する方法とその設計方法です。 LLM が異常検出タスクを解決できるようにするためのプロンプトまたはパイプライン。この作品について詳しく紹介していきます。画像用紙タイトル:Large languagemodelscanbeゼロショタノマリデテ
 Kingbang が新しい DDR5 8600 メモリを発売、CAMM2、LPCAMM2、および通常のモデルから選択可能
Jun 08, 2024 pm 01:35 PM
Kingbang が新しい DDR5 8600 メモリを発売、CAMM2、LPCAMM2、および通常のモデルから選択可能
Jun 08, 2024 pm 01:35 PM
6 月 7 日のこのサイトのニュースによると、GEIL は 2024 台北国際コンピューター ショーで最新の DDR5 ソリューションを発表し、SO-DIMM、CUDIMM、CSODIMM、CAMM2、および LPCAMM2 バージョンから選択できるように提供しました。 ▲画像出典:Wccftech 写真に示すように、Jinbang が展示した CAMM2/LPCAMM2 メモリは非常にコンパクトな設計を採用しており、最大 128GB の容量と最大 8533MT/s の速度を実現できる製品もあります。 AMDAM5 プラットフォームで安定しており、補助冷却なしで 9000MT/s までオーバークロックされます。レポートによると、Jinbang の 2024 Polaris RGBDDR5 シリーズ メモリは最大 8400 のメモリを提供できます。
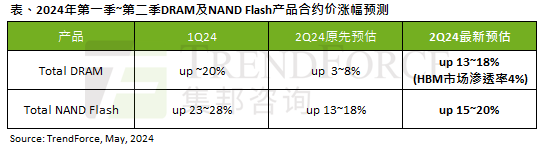 AIの波の影響は明らかで、トレンドフォースは今四半期のDRAMメモリとNANDフラッシュメモリの契約価格の上昇予測を上方修正した。
May 07, 2024 pm 09:58 PM
AIの波の影響は明らかで、トレンドフォースは今四半期のDRAMメモリとNANDフラッシュメモリの契約価格の上昇予測を上方修正した。
May 07, 2024 pm 09:58 PM
TrendForceの調査レポートによると、AIの波はDRAMメモリとNANDフラッシュメモリ市場に大きな影響を与えています。 5 月 7 日のこのサイトのニュースで、TrendForce は本日の最新調査レポートの中で、同庁が今四半期 2 種類のストレージ製品の契約価格の値上げを拡大したと述べました。具体的には、TrendForce は当初、2024 年第 2 四半期の DRAM メモリの契約価格が 3 ~ 8% 上昇すると予測していましたが、現在は NAND フラッシュ メモリに関しては 13 ~ 18% 上昇すると予測しています。 18%、新しい推定値は 15% ~ 20% ですが、eMMC/UFS のみが 10% 増加しています。 ▲画像出典 TrendForce TrendForce は、同庁は当初、今後も継続することを期待していたと述べた。
 Vivo の新しい X100 シリーズ メモリ、カラー露出: すべてのシリーズは 12+256GB から始まります
May 06, 2024 pm 03:58 PM
Vivo の新しい X100 シリーズ メモリ、カラー露出: すべてのシリーズは 12+256GB から始まります
May 06, 2024 pm 03:58 PM
5月6日のニュースによると、vivoは本日、新しいvivoX100シリーズが5月13日19時に正式にリリースされると正式に発表しました。このカンファレンスでは、vivoX100s、vivoX100sPro、vivoX100Ultraの3モデルと、vivoの自社開発イメージングブランドBlueImageブループリントイメージング技術が発表される予定であることがわかった。デジタルブロガー「Digital Chat Station」も本日、これら3モデルの公式レンダリング、メモリ仕様、カラーマッチングを公開しており、このうちX100sはストレートスクリーンデザインを採用しているのに対し、X100sProとX100Ultraは曲面スクリーンデザインを採用している。ブロガーは、vivoX100s にはブラック、チタン、シアン、ホワイトの 4 つの色があることを明らかにしました。 メモリの仕様。
