


Python クローラーによるデータ取得方法
Python クローラーは、リクエスト ライブラリを介して HTTP リクエストを送信したり、解析ライブラリを使用して HTML を解析したり、正規表現を使用してデータを抽出したり、データ スクレイピング フレームワークを使用してデータを取得したりできます。 Python クローラーに関するさらなる知識。詳細については、このトピックの下にある記事を参照してください。 PHP 中国語 Web サイトは、どなたでも学習しに来られることを歓迎します。
 162
162
 12
12
Python クローラーによるデータ取得方法

Python クローラーによるデータ取得方法
Python クローラーは、リクエスト ライブラリを介して HTTP リクエストを送信したり、解析ライブラリを使用して HTML を解析したり、正規表現を使用してデータを抽出したり、データ スクレイピング フレームワークを使用してデータを取得したりできます。詳細な紹介: 1. リクエスト ライブラリは、Requests、urllib などの HTTP リクエストを送信します; 2. 解析ライブラリは、BeautifulSoup、lxml などの HTML を解析します; 3. 正規表現はデータを抽出します。正規表現は次の目的で使用されます。文字列のパターンを記述するツールで、パターンのマッチングなどにより要件を満たすデータを抽出できます。
Nov 13, 2023 am 10:44 AM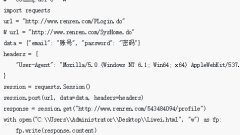
リクエストライブラリの基本的な使い方
1.response.contentとresponse.textの違い:response.contentはエンコードされたバイト型(「str」データ型)、response.textはunicode型です。これら 2 つの方法の使い分けは状況に応じて異なります。注: unicode -> str はエンコード プロセス (encode()) で、unicode はデコード プロセス (decode()) です。例は次のとおりです。 # --codin...
Jun 11, 2018 pm 10:55 PM
Python Web クローラーリクエストライブラリの使用方法
1. Web クローラーとは何ですか? 簡単に言うと、インターネットからデータを自動的にダウンロード、解析、整理するプログラムを構築することです。 Web を閲覧するときと同じように、次回簡単に読んだり閲覧したりできるように、興味のあるコンテンツをノートブックにコピー アンド ペーストします。Web クローラーを使用すると、これらのコンテンツを自動的に完成させることができます。コピーして貼り付けることができます - —Web クローラーはさらにその能力を発揮できます。Web クローラーが必要な理由は何ですか? データ分析を行う必要がある場合、多くの場合、このデータは Web ページに保存されており、手動でダウンロードするには時間がかかります。 。
May 15, 2023 am 10:34 AM
この記事では、Python の urllib ライブラリ (URL の操作) について説明します。
Python 言語を使用すると、誰もが Python をより良く学ぶことができます。 urllib が提供する機能は、プログラムを使用してさまざまな HTTP リクエストを実行することです。ブラウザをシミュレートして特定の機能を実行したい場合は、リクエストをブラウザとして偽装する必要があります。偽装の方法は、ブラウザから送信されるリクエストを監視し、ブラウザの識別に使用されるリクエストヘッダーであるUser-Agentヘッダーに基づいてリクエストを偽装することです。
Jul 25, 2023 pm 02:08 PM
python3.6 で urllib2 パッケージを使用したい場合はどうすればよいですか?
Pyhton2 の urllib2 ツールキットは、Python3 の urllib.request と urllib.error の 2 つのパッケージに分割されました。その結果、パッケージが見つからず、インストールする方法がありません。したがって、これら 2 つのパッケージをインストールし、インポート時にこのメソッドを使用します。
Jul 01, 2019 pm 02:18 PM
Python 2.x で urllib.urlopen() 関数を使用して GET リクエストを送信する方法
Python は、Web 開発、データ分析、自動化タスクなどの分野で広く使用されている人気のあるプログラミング言語です。 Python2.x バージョンでは、urllib ライブラリの urlopen() 関数を使用して、簡単に GET リクエストを送信し、応答データを取得できます。この記事では、Python2.x で urlopen() 関数を使用して GET リクエストを送信する方法を詳しく紹介し、対応するコード例を示します。 urlopen() 関数を使用して GET リクエストを送信する前に、まず次のことを行う必要があります。
Jul 29, 2023 am 08:48 AM
Pythonのurllibクローラ、リクエストモジュール、解析モジュールの詳細説明
urllib は、URL を処理するために使用される Python のツールキットです。この記事では、このツールキットを使用してクローラ開発について説明します。結局のところ、クローラ アプリケーションの開発は、Web インターネット データ収集において非常に重要です。記事ディレクトリ urllibrequest モジュールは URLRequest クラスにアクセスします 他のクラス parse モジュールは URL を解析します URLrobots.txt ファイル
Mar 21, 2021 pm 03:15 PM
Python beautifulsoup4モジュールの使い方
1. BeautifulSoup4 の基礎知識補足 BeautifulSoup4 は Python 解析ライブラリです, 主に HTML と XML の解析に使用されます. クローラー知識システムでは, より多くの HTML が解析されます. ライブラリのインストール コマンドは次のとおりです: pipinstallBeautifulsoup4BeautifulSoup は a に依存する必要がありますパーサー、一般的に使用されるパーサー、および利点は次のとおりです: Python 標準ライブラリ html.parser: Python 組み込み標準ライブラリ、強力なフォールト トレランス; lxml パーサー: 高速で強力なフォールト トレランス; html5lib: 最もフォールト トレラント、解析方法と閲覧 デバイスは一貫しています。次に段落を使用します
May 11, 2023 pm 10:31 PM
Python クローラー パーサー BeautifulSoup4 を 1 つの記事で理解する
この記事では、クローラー パーサー BeautifulSoup4 に関連する問題を主に整理し、Python に関する関連知識をお届けします Beautiful Soup は HTML または XML ファイルからデータを抽出できる Python ライブラリです 好みの変換を渡すことができます 実装方法を見てみましょう通常のドキュメントのナビゲーション、検索、およびドキュメントの変更について、皆さんのお役に立てれば幸いです。
Jul 12, 2022 pm 04:56 PM
BeautifulSoup と Requests を使用して Python クローラーを使用して Web ページ データをクロールする方法
1. はじめに Web クローラーの実装原理は、次のステップに要約できます。 HTTP リクエストの送信: Web クローラーは、HTTP リクエスト (通常は GET リクエスト) をターゲット Web サイトに送信することによって、Web ページのコンテンツを取得します。 Python では、リクエスト ライブラリを使用して HTTP リクエストを送信できます。 HTML の解析: ターゲット Web サイトから応答を受信した後、クローラーは HTML コンテンツを解析して有用な情報を抽出する必要があります。 HTML は Web ページの構造を記述するために使用されるマークアップ言語であり、一連のネストされたタグで構成されます。クローラーは、これらのタグと属性に基づいて必要なデータを見つけて抽出できます。 Python では、BeautifulSoup や lxml などのライブラリを使用して HTML を解析できます。データ抽出: HTML を解析した後、
Apr 29, 2023 pm 12:52 PM
Python 正規表現 - 入力が float かどうかを確認します
浮動小数点数は、数学的計算からデータ分析まで、さまざまなプログラミング タスクにおいて重要な役割を果たします。ただし、ユーザー入力または外部ソースからのデータを扱う場合は、入力が有効な浮動小数点数であることを確認することが重要になります。 Python は、この課題に対処するための強力なツールを提供します。その 1 つが正規表現です。この記事では、Python で正規表現を使用して入力が浮動小数点数かどうかを確認する方法を説明します。正規表現 (正規表現とも呼ばれます) は、パターンを定義し、テキスト内の一致を検索するための簡潔かつ柔軟な方法を提供します。正規表現を活用することで、浮動小数点形式に正確に一致するパターンを構築し、それに応じて入力を検証できます。この記事では、Pyt の使用方法を説明します。
Sep 15, 2023 pm 04:09 PM
正規表現とは何ですか
正規表現は、文字列の記述、一致、操作に使用されるツールです。一連の文字と特殊記号で構成されるパターンであり、テキスト内の特定のパターンに一致する文字列を検索、置換、抽出するために使用されます。正規表現はコンピュータ サイエンスやソフトウェア開発で広く使用されており、テキスト処理、データ検証、パターン マッチングなどの分野で使用できます。基本的な考え方は、パターンを定義することによって、特定のルールに準拠する文字列のタイプを記述することです。このパターンは、通常の文字と特殊文字で構成されます。特殊文字は、特定の文字または文字セットを表すために使用されます。
Nov 10, 2023 am 10:23 AM
人気の記事

ホットツール
Kits AI
AI アーティストの声であなたの声を変換します。独自の AI 音声モデルを作成してトレーニングします。
SOUNDRAW - AI Music Generator
SOUNDRAW の AI 音楽ジェネレーターを使用して、ビデオや映画などの音楽を簡単に作成できます。
Web ChatGPT.ai
効率的なブラウジングのためのOpenAIチャットボット付きの無料クロム拡張機能。

goHeather
契約の簡単なドラフトとレビューのためのAIプラットフォーム。
BLACKBOX.AI
仕事と学習体験を変革するためのAIエージェント。
ホットトピック
 7751
7751
 15
1643
14
1397
52
1293
25
1234
29
15
1643
14
1397
52
1293
25
1234
29