合計 10000 件の関連コンテンツが見つかりました

T5 に基づく 2 段階マルチタスク Text-to-SQL 事前トレーニング モデル MIGA
記事の紹介:事前トレーニング済み言語モデル (PLM) には豊富な知識が含まれていることが、ますます多くの研究で証明されており、さまざまなタスクに対して、適切なトレーニング方法を使用して PLM を活用することで、モデルの機能をより向上させることができます。 Text-to-SQL タスクでは、現在の主流のジェネレーターは構文ツリーに基づいており、SQL 構文用に設計する必要があります。最近、NetEase Interactive Entertainment AI Lab は広東外国語大学およびコロンビア大学と提携し、事前トレーニング済み言語モデル T5 の事前トレーニング方法に基づいた 2 段階のマルチタスク事前トレーニング モデル MIGA を提案しました。 MIGA は、事前トレーニング段階で 3 つの補助タスクを導入し、それらを統合生成タスク パラダイムに編成します。これにより、すべての Text-to-SQL データ セットを統合できます。
2023-04-13
コメント 0
1304

生物医学 NLP ドメインの特定の事前トレーニング済みモデル: PubMedBERT
記事の紹介:今年の大規模言語モデルの急速な開発により、BERT のようなモデルは「小規模」モデルと呼ばれるようになりました。 Kaggle の LLM 科学試験コンテストでは、deberta を使用しているプレイヤーが 4 位に入賞するという素晴らしい成績を収めました。したがって、特定のドメインやニーズでは、必ずしも大規模な言語モデルが最適なソリューションとして必要なわけではなく、小規模なモデルにも適した場所があります。したがって、今日紹介するのは、2022 年に Microsoft Research が ACM で発表した論文 PubMedBERT です。このモデルは、ドメイン固有のコーパスを使用して、BERT を最初から事前学習します。論文の主なポイントは次のとおりです。ラベルのないテキストが大量に含まれる特定のドメイン (生物医学など、最初から事前トレーニングされたもの)
2023-11-27
コメント 0
1235

ChatGPT PHP 技術分析: 事前トレーニングされたモデルを使用してインテリジェントなチャット アプリケーションを構築する方法
記事の紹介:ChatGPTPHP 技術分析: 事前トレーニング済みモデルを使用してインテリジェントなチャット アプリケーションを構築する方法 今日の情報化時代において、インテリジェントなチャット アプリケーションは日常生活とビジネスに不可欠な部分になっています。スマート チャット アプリケーションは、ユーザーが自然言語でコミュニケーションし、質問や提案に対してリアルタイムで回答できるようにします。最近オープンソースになった ChatGPT プロジェクトは、インテリジェントなチャット アプリケーションを構築する効果的な方法を提供します。この記事では、PHP プログラミング言語と事前トレーニング済みモデルを組み合わせてインテリジェントなチャット アプリケーションを構築し、提供する方法を詳しく紹介します。
2023-10-24
コメント 0
1097

CMU が Adobe と提携: GAN モデルは事前トレーニングの時代を到来させ、トレーニング サンプルのわずか 1% しか必要としません
記事の紹介:事前トレーニング時代に入ってから、視覚認識モデルの性能は急速に発展しましたが、敵対的生成ネットワーク (GAN) などの画像生成モデルは遅れを取っているようです。通常、GANのトレーニングは教師なしでゼロから行われるため、時間と労力がかかり、大規模な事前トレーニングでビッグデータから学習した「知識」が活用されないのがデメリットではないでしょうか。さらに、画像生成自体が、現実世界の視覚現象における複雑な統計データを取得してシミュレートできる必要があり、そうでない場合、生成された画像は物理世界の法則に準拠せず、すぐに「偽物」であると識別されてしまいます。一目。事前トレーニングされたモデルは知識を提供し、GAN モデルは生成機能を提供します。この 2 つの組み合わせは素晴らしいものになる可能性があります。問題は、どの事前トレーニング済みモデルとそれらをどのように組み合わせることで GAN モデルの生成能力を向上できるかということです。
2023-05-11
コメント 0
1466

強化学習のもう一つの革命! DeepMind が提案する「アルゴリズム蒸留」: 探索可能な事前トレーニング済み強化学習 Transformer
記事の紹介:現在のシーケンス モデリング タスクにおいて、Transformer は最も強力なニューラル ネットワーク アーキテクチャであると言えます。また、事前トレーニングされた Transformer モデルは、プロンプトを条件として使用したり、コンテキスト内学習を使用して、さまざまな下流タスクに適応したりできます。大規模な事前トレーニング済み Transformer モデルの汎化能力は、テキスト補完、言語理解、画像生成などの複数の分野で検証されています。昨年以来、オフライン強化学習 (オフライン RL) をシーケンス予測問題として扱うことで、モデルがオフライン データからポリシーを学習できることを証明する関連研究が行われてきました。しかし、現在のアプローチは、学習を含まないデータからポリシーを学習するか、
2023-04-12
コメント 0
1846

中国語音声の事前トレーニング済みモデルが見つかりませんか?中国語版 Wav2vec 2.0 と HuBERT が登場します
記事の紹介:Wav2vec 2.0 [1]、HuBERT [2]、WavLM [3] などの音声事前トレーニング モデルは、数万時間のラベルなし音声データ (Libri-light など) に対する自己教師あり学習を通じて自動学習を大幅に改善しました。自動音声認識 (ASR)、テキスト読み上げ (TTS)、音声変換 (VC) などの音声ダウンストリーム タスクのパフォーマンス。ただし、これらのモデルには公開中国語バージョンがないため、中国語音声研究シナリオに適用するには不便です。 WenetSpeech [4] はい
2023-04-08
コメント 0
1922

Mininglamp Technology が大規模モデルの事前トレーニングを促進するために無料のオープンソース TensorBoard.cpp をリリース
記事の紹介:最近、Mininglamp Technology Group は、機械学習視覚化ツールである TensorBoard の C++ インターフェイスを実装しました。これにより、C++ に基づく大規模モデル プロジェクトのツール セットがさらに強化され、大規模モデルの事前トレーニング プロセスのモニタリングがより便利かつ効率的になります。マーケティング分野における大規模モデルの事前トレーニングのプロセスを加速します。このツールは Github 上のオープンソースです。 TensorBoard は、Google によって開発された機械学習視覚化ツールであり、機械学習プロセスのさまざまな指標を監視するためによく使用されます。 Mininglamp Technology のシニア テクニカル ディレクターである Zhao Liang 氏は次のように述べています。「大規模モデルのトレーニングのプロセスでは、データのモニタリングが重要な側面であり、TensorBoard は、大規模モデルのトレーニング中に損失の変更や検証セットを記録するなど、モデル内のさまざまなパラメーターと結果を視覚化します。モデルのトレーニング プロセス。
2023-08-14
コメント 0
816

CVPR 2024 | 自動運転世界モデルの 4 次元時空事前トレーニング
記事の紹介:北京大学とEVLOイノベーションチームは共同で、自動運転のための4次元時空事前トレーニングアルゴリズムであるDriveWorldを提案した。この方法では、事前トレーニングにワールド モデルを使用し、4 次元時空間モデリング用の記憶状態空間モデルを設計し、シーンの占有グリッドを予測することで自動運転が直面するランダムな不確実性と知識の不確実性を軽減します。この論文はCVPR2024に採択されました。論文タイトル: DriveWorld: 4DPre-trainedSceneUnderstandingviaWorldModelsforAutonomousDriving 論文リンク: https://arxiv.org/abs/2405.04390 1. モーション
2024-08-07
コメント 0
840

BERT から ChatGPT まで、北杭大学を含む 9 つのトップ研究機関の包括的なレビュー: 私たちが長年にわたって一緒に追求してきた「事前トレーニング基本モデル」
記事の紹介:数ショットおよびゼロショットのシナリオにおける ChatGPT の驚くべきパフォーマンスにより、研究者は「事前トレーニング」が正しいルートであるとの決意をさらに強めました。事前トレーニングされた基盤モデル (PFM) は、さまざまなデータ モードでのさまざまなダウンストリーム タスクの基礎であると考えられます。つまり、大規模なデータ、事前トレーニングされた基本モデル (BERT、GPT-3、MAE、DALLE-E など) に基づいています。 ChatGPT はトレーニングされており、ダウンストリーム アプリケーションに適切なパラメータ初期化を提供します。 PFM の背後にある事前トレーニングのアイデアは、大規模なモデルの適用において重要な役割を果たします。畳み込みモジュールや再帰モジュールを使用した以前の特徴抽出方法とは異なり、新しい
2023-04-15
コメント 0
1455

Apple は自己回帰言語モデルを使用して画像モデルを事前トレーニングします
記事の紹介:1. 背景 GPT などの大規模モデルの出現後、nexttoken を予測する事前学習タスクである言語モデルの Transformer + 自己回帰モデリング手法が大きな成功を収めました。では、この自己回帰モデリング手法はビジュアル モデルでより良い結果を達成できるでしょうか?今回紹介する記事は、Apple が最近公開した Transformer+autoregressive pre-training をベースにしたビジュアルモデルのトレーニングに関する記事ですので、その成果を紹介させていただきます。絵用紙タイトル:ScalablePre-trainingofLargeAutoregressiveImageModels ダウンロードアドレス:https://ar
2024-01-29
コメント 0
1015

画像検索を効率的かつ正確に実行するにはどうすればよいですか?軽量ビジョンの事前トレーニング済みモデルを見てみましょう
記事の紹介:画像の検索で問題が発生したことがありますか?大量の画像の中から目的の画像を正確に見つけるのは難しいか、テキストベースの検索では不十分です。この問題に関して、Microsoft Research Asia と Microsoft Cloud Computing and Artificial Intelligence Division の研究者は、軽量ビジュアル モデルに関する詳細な研究を実施し、ビジュアル Transformer を実現するためのビジュアル事前トレーニング モデルの一連の設計および圧縮方法を提案しました。 。現在、この方法とモデルは Microsoft の Bing 検索エンジンに適用され、数百億枚の画像の正確かつ高速な推論と検索が実現されています。この記事では、軽量ビジュアル事前トレーニング モデルの開発、主要なテクノロジー、アプリケーション、可能性、さらには将来の機会と課題について詳しく説明します。
2023-04-08
コメント 0
1365

Pythonによるディープラーニング事前学習モデルの詳細説明
記事の紹介:人工知能と深層学習の発展に伴い、事前トレーニング モデルは、自然言語処理 (NLP)、コンピューター ビジョン (CV)、音声認識などの分野で一般的なテクノロジーになりました。現在最も人気のあるプログラミング言語の 1 つである Python は、当然のことながら、事前トレーニングされたモデルの適用において重要な役割を果たします。この記事では、Python のディープラーニング事前トレーニング モデルに焦点を当て、その定義、種類、アプリケーション、事前トレーニング モデルの使用方法について説明します。事前トレーニング済みモデルとは何ですか?深層学習モデルの主な困難は、高品質のデータを大量に分析することです。
2023-06-11
コメント 0
2008

転移学習技術を使用した深層学習モデルのカスタマイズされたトレーニング
記事の紹介:翻訳者 | Zhu Xianzhong によるレビュー | Sun Shujuan 転移学習は機械学習の一種で、トレーニング済みまたは事前トレーニング済みのニューラル ネットワークに適用される手法であり、これらの事前トレーニング済みニューラル ネットワークは何百万ものトレーニング済みデータを使用して作成されています。ポイント。現在、このテクノロジーの最もよく知られた用途は、ディープ ニューラル ネットワークのトレーニングです。この方法は、少ないデータを使用してディープ ニューラル ネットワークをトレーニングする際に優れたパフォーマンスを示しています。実際、ほとんどの実世界のデータには通常、堅牢な深層学習モデルをトレーニングするための数百万のデータ ポイントがないため、この手法はデータ サイエンスの分野でも役立ちます。現在、数百万のデータポイントを使用してトレーニングされた多くのモデルが存在しており、複雑な深層学習ニューラル ネットワークを最高の精度でトレーニングするために使用できます。
2023-04-23
コメント 0
1699

ChatGPT Python モデル トレーニング ガイド: チャットボットをカスタマイズする手順
記事の紹介:ChatGPTPython モデル トレーニング ガイド: チャット ロボットをカスタマイズするための手順の概要: 近年、NLP (自然言語処理) 技術の発展に伴い、チャット ロボットがますます注目を集めています。 OpenAI の ChatGPT は、マルチドメイン チャットボットの構築に使用できる強力な事前トレーニング済み言語モデルです。この記事では、データの準備、モデルのトレーニング、ダイアログ サンプルの生成など、Python を使用して ChatGPT モデルをトレーニングする手順を紹介します。ステップ 1: データの準備、収集、クリーニング
2023-10-24
コメント 0
1327

多機能 RNA 解析、Transformer に基づく Baidu チームの RNA 言語モデルが Nature サブジャーナルに掲載
記事の紹介:Editor | Radish コアの事前トレーニング済み言語モデルは、ヌクレオチド配列の解析において有望であることが示されていますが、単一の事前トレーニング済み重みセットを使用して、さまざまなタスクで適切に機能する多機能モデルを実現するにはまだ課題があります。 Baidu Big Data Lab (BDL) と上海交通大学のチームは、Transformer アーキテクチャに基づいた RNA 中心の事前トレーニング モデルである RNAErnie を開発しました。研究者らは 7 つのデータセットと 5 つのタスクでモデルを評価し、教師あり学習と教師なし学習の両方における RNAErnie の優位性を実証しました。 RNAErnie はベースラインを上回り、分類精度が 1.8%、相互作用予測精度が 2.2%、構造予測 F1 スコアが 3.3% 向上しました。
2024-06-10
コメント 0
598
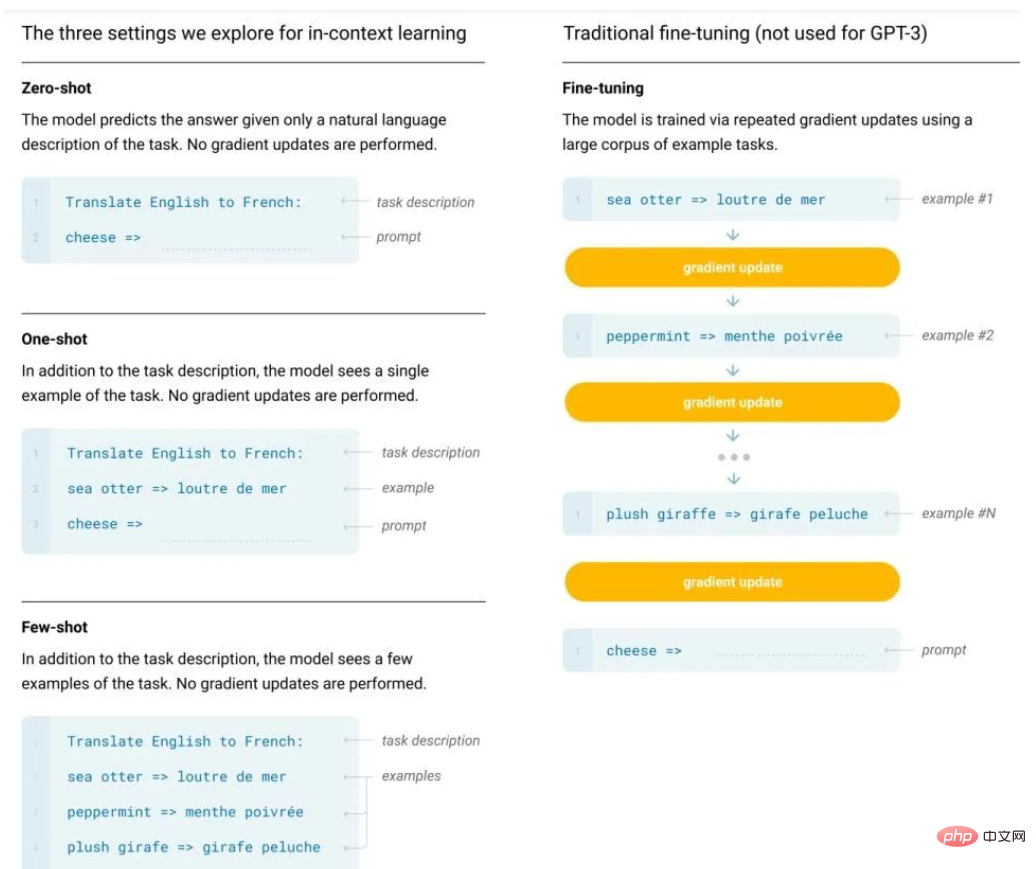
GPT によって推進されるインコンテキスト学習はなぜ機能するのでしょうか?モデルは秘密裏に勾配降下法を実行します
記事の紹介:BERT の後、研究者は大規模な事前トレーニング モデルの可能性に気づき、さまざまな事前トレーニング タスク、モデル アーキテクチャ、トレーニング戦略などが提案されています。ただし、BERT タイプのモデルには通常 2 つの大きな欠点があります: 1 つはラベル付きデータに過度に依存していること、もう 1 つは過剰適合現象です。具体的には、現在の言語モデルは事前トレーニング+下流タスクの微調整という2段階のフレームワークを採用する傾向にありますが、下流タスクの微調整プロセスで大量のサンプルが必要となり、効果が低下してしまいます。ただし、データにラベルを付けるコストは高くつきます。ラベル付きデータも限られており、モデルはトレーニング データの分布にのみ適合できますが、データが少ないと過剰適合につながりやすく、モデルの汎化能力が低下します。大規模モデル、大規模な事前トレーニング済み言語モデル、特に GPT-3 のパイオニアとして
2023-04-25
コメント 0
1544

北京大学と Wangshi Intelligence は、化学反応の事前トレーニングと条件付き分子生成の間のギャップを埋める新しいモデルを提案します。
記事の紹介:化学反応は創薬および有機化学研究の基礎です。研究コミュニティの間では、化学反応の基本的な規則を効果的に捉えることができる大規模な深層学習フレームワークに対するニーズが高まっています。最近、北京大学と Wangshi Intelligence の研究チームは、反応ベースの分子事前トレーニングと生成タスクの間のギャップを埋める新しい方法を提案しました。研究者らは、有機化学のメカニズムにヒントを得て、モデルに帰納的バイアスを組み込むことを可能にする新しい事前トレーニング フレームワークを開発しました。この提案されたフレームワークは、困難な下流タスクを実行する際に最先端の結果を達成します。このフレームワークは、化学の知識を活用することで、少数の反応テンプレートに依存する現在の分子生成モデルの制限を克服します。広範な実験により、このモデルは高品質の合成可能な薬物のような構造を生成しました。
2023-12-14
コメント 0
619


