合計 10000 件の関連コンテンツが見つかりました

強化学習における Golang の機械学習アプリケーション
記事の紹介:強化学習における Golang の機械学習アプリケーションの紹介 強化学習は、環境と対話し、報酬フィードバックに基づいて最適な動作を学習する機械学習手法です。 Go 言語には並列処理、同時実行性、メモリ安全性などの機能があり、強化学習に有利です。実践的なケース: Go 強化学習 このチュートリアルでは、Go 言語と AlphaZero アルゴリズムを使用して Go 強化学習モデルを実装します。ステップ 1: 依存関係をインストールする gogetgithub.com/tensorflow/tensorflow/tensorflow/gogogetgithub.com/golang/protobuf/ptypes/times
2024-05-08
コメント 0
503

強化学習におけるアルゴリズム選択の問題
記事の紹介:強化学習におけるアルゴリズム選択の問題には、特定のコード例が必要です。強化学習は、エージェントと環境の間の相互作用を通じて最適な戦略を学習する機械学習の分野です。強化学習では、適切なアルゴリズムを選択することが学習効果にとって非常に重要です。この記事では、強化学習におけるアルゴリズム選択の問題を調査し、具体的なコード例を示します。強化学習では、Q-Learning、DeepQNetwork (DQN)、Actor-Critic など、選択できるアルゴリズムが多数あります。適切なアルゴリズムを選択する
2023-10-08
コメント 0
1189

PHP を使用して強化学習アルゴリズムを構築する方法
記事の紹介:PHP を使用して強化学習アルゴリズムを構築する方法 はじめに: 強化学習は、環境と対話することで最適な意思決定を行う方法を学習する機械学習手法です。この記事では、PHP プログラミング言語を使用して強化学習アルゴリズムを構築する方法を紹介し、読者の理解を助けるコード例を提供します。 1. 強化学習アルゴリズムとは何ですか? 強化学習アルゴリズムは、環境からのフィードバックを観察することによって意思決定を行う方法を学習する機械学習手法です。他の機械学習アルゴリズムとは異なり、強化学習アルゴリズムは既存のデータのみに基づいているわけではありません。
2023-07-31
コメント 0
700

強化学習における報酬設計の問題
記事の紹介:強化学習における報酬設計の問題には、特定のコード例が必要です。強化学習は、環境との相互作用を通じて累積報酬を最大化するアクションの実行方法を学習することを目的とした機械学習手法です。強化学習では、報酬は重要な役割を果たし、エージェントの学習プロセスにおける信号であり、エージェントの行動を導くために使用されます。ただし、報酬の設計は難しい問題であり、合理的な報酬の設計は強化学習アルゴリズムのパフォーマンスに大きな影響を与える可能性があります。強化学習では、報酬はエージェント対環境として考えることができます。
2023-10-08
コメント 0
1435

C++ の深層強化学習テクノロジー
記事の紹介:深層強化学習技術は、人工知能の分野の一つとして大きな注目を集めており、複数の国際コンペティションで優勝しており、パーソナルアシスタント、自動運転、ゲームインテリジェンスなどの分野でも広く利用されています。深層強化学習を実現するプロセスにおいて、ハードウェア リソースが限られている場合、効率的で優れたプログラミング言語である C++ が特に重要になります。深層強化学習は、その名前が示すように、深層学習と強化学習の 2 つの分野のテクノロジーを組み合わせたものです。簡単に理解すると、ディープ ラーニングとは、多層のニューラル ネットワークを構築することでデータから特徴を学習し、意思決定を行うことを指します。
2023-08-21
コメント 0
1122

強化学習の定義、分類、アルゴリズムの枠組み
記事の紹介:強化学習 (RL) は、教師あり学習と教師なし学習の間の機械学習アルゴリズムです。試行錯誤と学習を通じて問題を解決します。トレーニング中、強化学習では一連の決定が行われ、実行されたアクションに基づいて報酬または罰が与えられます。目標は、報酬総額を最大化することです。強化学習には自律的に学習して適応する能力があり、動的な環境で最適化された意思決定を行うことができます。従来の教師あり学習と比較して、強化学習は明確なラベルのない問題により適しており、長期的な意思決定の問題で良好な結果を達成できます。強化学習の核心は、エージェントが実行したアクションに基づいてアクションを強制することであり、エージェントは全体的な目標に対するアクションのプラスの影響に基づいて報酬を受け取ります。強化学習アルゴリズムには、モデルベース学習アルゴリズムとモデルフリー学習アルゴリズムの 2 つの主なタイプがあります。
2024-01-24
コメント 0
690

強化学習における報酬関数設計の問題
記事の紹介:強化学習における報酬関数設計の問題 はじめに 強化学習は、エージェントと環境の間の相互作用を通じて最適な戦略を学習する方法です。強化学習では、報酬関数の設計がエージェントの学習効果にとって重要です。この記事では、強化学習における報酬関数の設計の問題を調査し、具体的なコード例を示します。報酬関数の役割と目標報酬関数は強化学習の重要な部分であり、特定の状態でエージェントが取得する報酬値を評価するために使用されます。その設計は、エージェントが最適なアクションを選択することで長期的な疲労を最大化するようにガイドするのに役立ちます。
2023-10-09
コメント 0
1716

階層型強化学習
記事の紹介:階層型強化学習 (HRL) は、高レベルの行動と意思決定を階層的に学習する強化学習手法です。従来の強化学習手法とは異なり、HRL はタスクを複数のサブタスクに分解し、各サブタスクでローカル戦略を学習し、これらのローカル戦略を組み合わせてグローバル戦略を形成します。この階層的な学習方法により、高次元の環境や複雑なタスクによって引き起こされる学習の困難さを軽減し、学習の効率とパフォーマンスを向上させることができます。階層的な戦略を通じて、HRL はさまざまなレベルで意思決定を行い、より高いレベルのインテリジェントな動作を実現できます。このアプローチは、ロボット制御、ゲームプレイ、自動運転などの多くの分野に応用できます。
2024-01-22
コメント 0
1405

機械学習: Github の強化学習 (RL) プロジェクトのトップ 19
記事の紹介:強化学習 (RL) は、エージェントが試行錯誤を通じて学習する機械学習方法です。強化学習アルゴリズムは、ゲーム、ロボット工学、金融などの多くの分野で使用されています。 RL の目標は、期待される長期利益を最大化する戦略を発見することです。強化学習アルゴリズムは、通常、モデルベースとモデルフリーの 2 つのカテゴリに分類されます。モデルベースのアルゴリズムは、環境モデルを使用して最適な行動経路を計画します。このアプローチは、環境の正確なモデリングと、そのモデルを使用したさまざまなアクションの結果の予測に依存しています。対照的に、モデルフリー アルゴリズムは環境との相互作用から直接学習するため、環境の明示的なモデリングを必要としません。この方法は、環境モデルの取得が困難または不正確な状況に適しています。実際の比較では、モデルフリーの強化学習アルゴリズムは、
2024-03-19
コメント 0
918
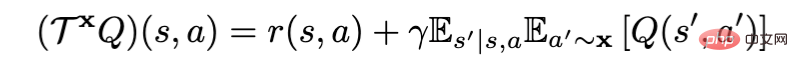
オフライン強化学習の新しいパラダイム! JD.comと清華大学が分離学習アルゴリズムを提案
記事の紹介:オフライン強化学習アルゴリズム (オフライン RL) は、強化学習の最も一般的なサブ方向の 1 つです。オフライン強化学習は環境と対話せず、以前に記録されたデータからターゲットのポリシーを学習することを目的としています。オフライン強化学習は、データ収集に費用がかかるか危険であるが、大量のデータが存在する可能性がある分野 (ロボット工学、産業用制御、自動運転など) において、オンライン強化学習 (オンライン RL) と比較して特に魅力的です。ポリシー評価に Bellman ポリシー評価演算子を使用する場合、現在のオフライン強化学習アルゴリズムは、X の差に応じて RL ベース (x=π) と模倣ベース (x=μ) に分けることができます。ここで、π がターゲットです。戦略、μ は行動戦略です
2023-04-11
コメント 0
996

強化学習とその応用シナリオを理解する
記事の紹介:犬を訓練する最良の方法は、ご褒美システムを使用して、良い行動にはご褒美を与え、悪い行動には罰を与えることです。同じ戦略は、強化学習と呼ばれる機械学習にも使用できます。強化学習は、問題に対する最適な解決策を見つけるための意思決定を通じてモデルをトレーニングする機械学習の分野です。モデルの精度を向上させるために、正の報酬を使用してアルゴリズムが正解に近づくように促し、負の報酬を使用して目標からの逸脱を罰することができます。目標を明確にしてからデータをモデル化するだけで、モデルはデータとの対話を開始し、手動介入なしで独自にソリューションを提案します。強化学習の例 犬のトレーニングを例に挙げると、犬用ビスケットなどのご褒美を与えて犬にさまざまな動作をさせます。犬は一定の戦略に従って報酬を追求するため、命令に従い、おねだりなどの新しい行動を学習します。
2024-01-22
コメント 0
1397

ポリシー勾配強化学習を用いたAB最適化手法
記事の紹介:ABテストはオンライン実験で広く使われている手法です。その主な目的は、ページまたはアプリケーションの 2 つ以上のバージョンを比較して、どのバージョンがより優れたビジネス目標を達成しているかを判断することです。これらの目標は、クリックスルー率、コンバージョン率などです。対照的に、強化学習は、試行錯誤学習を使用して意思決定戦略を最適化する機械学習方法です。ポリシー勾配強化学習は、最適なポリシーを学習することで累積報酬を最大化することを目的とした特別な強化学習手法です。どちらもビジネス目標の最適化において異なる用途を持っています。 AB テストでは、さまざまなページのバージョンをさまざまなアクションと考え、ビジネス目標は報酬シグナルの重要な指標と考えることができます。最大限のビジネス目標を達成するには、次のことを選択できる戦略を設計する必要があります。
2024-01-24
コメント 0
986

Xishanju AI 技術専門家 Huang Honbo 氏: ゲームにおける強化学習と動作ツリーの実践的な統合
記事の紹介:2022年8月6日から7日まで、AISummitグローバル人工知能技術カンファレンスは予定通り開催されます。 7日午後に開催された「人工知能フロンティア探索」サブフォーラムでは、西山州のAI技術専門家である黄紅波氏が「ゲームにおける強化学習と行動ツリーの実践的な組み合わせ」をテーマに、詳細を共有した。ゲーム分野における強化学習の影響。 Huang Honbo 氏は、強化学習テクノロジーの実装は、アルゴリズムをより強力に変更することではなく、強化学習テクノロジーを深層学習やゲーム プランニングと組み合わせて、完全なソリューション セットを形成し、実装することにあると述べました。強化学習によりゲームがよりインテリジェントになります。ゲームに強化学習を実装すると、ゲームがよりインテリジェントになり、よりプレイしやすくなります。これがゲームでの強化学習の使用です。
2023-04-09
コメント 0
1818

Vueコンポーネント通信の強化学習手法
記事の紹介:Vue コンポーネント通信の強化学習法 Vue 開発において、コンポーネント通信は非常に重要なテーマです。これには、複数のコンポーネント間でデータを共有する方法、イベントをトリガーする方法などが含まれます。一般的なアプローチは、親コンポーネントと子コンポーネント間の通信に props メソッドと $emit メソッドを使用することです。ただし、アプリケーションのサイズが大きくなり、コンポーネント間の関係が複雑になると、この単純な通信方法は煩雑になり、維持が困難になる可能性があります。強化学習は、試行錯誤と報酬メカニズムを使用して問題解決を最適化するアルゴリズムです。コンポーネント通信では、
2023-07-17
コメント 0
1269

強化学習戦略による特徴選択
記事の紹介:特徴の選択は、機械学習モデルを構築するプロセスにおける重要なステップです。モデルと達成したいタスクに適した特徴を選択すると、パフォーマンスが向上します。高次元のデータセットを扱う場合、特徴の選択が特に重要です。これにより、モデルはより速く、より適切に学習できるようになります。目的は、最適な数の特徴と最も意味のある特徴を見つけることです。この記事では、強化学習戦略による新しい特徴選択を紹介し、実装します。まず、強化学習、特にマルコフ決定プロセスについて説明します。これはデータ サイエンスの分野における非常に新しい手法であり、特に特徴の選択に適しています。次に、その実装と Python ライブラリ (FSRLearning) のインストールと使用方法を紹介します。最後に、これを説明するために簡単な例を使用します。
2024-06-05
コメント 0
484

強化学習における価値関数とそのベルマン方程式の重要性
記事の紹介:強化学習は機械学習の一分野であり、試行錯誤を通じて特定の環境で最適なアクションを学習することを目的としています。その中でも、価値関数とベルマン方程式は強化学習の重要な概念であり、この分野の基本原理を理解するのに役立ちます。値関数は、特定の状態から期待される長期収益です。強化学習では、アクションのメリットを評価するために報酬を使用することがよくあります。報酬は即時または遅延することができ、効果は将来のタイムステップで発生します。したがって、値関数を状態値関数とアクション値関数の 2 つのカテゴリに分けることができます。状態値関数は特定の状態でアクションを取ることの価値を評価し、アクション値関数は特定の状態で特定のアクションを取ることの価値を評価します。価値関数の計算と更新による強化学習アルゴリズム
2024-01-22
コメント 0
924

Transformer は強化学習においてどこまで発展しましたか?清華大学、北京大学などが共同でTransformRLのレビューを発表
記事の紹介:強化学習 (RL) は逐次的な意思決定のための数学的形式を提供し、深層強化学習 (DRL) も近年大きな進歩を遂げています。ただし、サンプル効率の問題により、現実世界における深層強化学習手法の広範な適用が妨げられています。この問題を解決するための効果的なメカニズムは、DRL フレームワークに誘導バイアスを導入することです。深層強化学習では、関数近似器が非常に重要です。ただし、教師あり学習 (SL) のアーキテクチャ設計と比較して、DRL のアーキテクチャ設計の問題はまだほとんど研究されていません。 RL アーキテクチャに関する既存の作業のほとんどは、教師あり/半教師あり学習コミュニティによって推進されています。たとえば、DRL で高次元画像に基づいて入力を処理するには、畳み込みニューラル ネットワーク (CNN) を導入するのが一般的なアプローチです。
2023-04-13
コメント 0
761

強化学習は誇張されすぎていませんか?
記事の紹介:翻訳者 | Li Rui によるレビュー | Sun Shujuan 友達とチェスをする準備をしていると想像できますが、彼は人間ではなく、ゲームのルールを理解していないコンピューター プログラムです。しかし、このアプリは、ゲームで勝つという 1 つの目標に向かって取り組んでいることを理解しています。コンピューター プログラムはルールを知らないため、実行を開始する手はランダムです。これらのトリックの中にはまったく意味をなさないものもありますが、勝つのは簡単です。この友人とチェスをするのがとても楽しくて、そのゲームにはまってしまったとします。しかし、コンピュータ プログラムは、あなたを倒す方法やトリックを徐々に学習するため、最終的には勝つでしょう。この仮説的なシナリオは突飛なように思えるかもしれませんが、機械学習の分野である強化学習についてのアイデアが得られるはずです。
2023-04-13
コメント 0
1139

強化学習ポリシーの勾配アルゴリズム
記事の紹介:ポリシー勾配アルゴリズムは重要な強化学習アルゴリズムであり、その中心的な考え方は、ポリシー関数を直接最適化することで最適な戦略を探索することです。価値関数を間接的に最適化する方法と比較して、ポリシー勾配アルゴリズムは収束性と安定性に優れ、連続的なアクション空間の問題を処理できるため、広く使用されています。このアルゴリズムの利点は、推定値関数を必要とせずにポリシー パラメーターを直接学習できることです。これにより、ポリシー勾配アルゴリズムが高次元状態空間と連続アクション空間の複雑な問題に対処できるようになります。さらに、ポリシー勾配アルゴリズムはサンプリングを通じて勾配を近似することもできるため、計算効率が向上します。つまり、ポリシー勾配アルゴリズムは強力かつ柔軟な手法です。ポリシー勾配アルゴリズムでは、ポリシー関数\pi(a|s) を定義する必要があります。
2024-01-22
コメント 0
1229

