合計 10000 件の関連コンテンツが見つかりました

データを取得するにはどのような方法がありますか?
記事の紹介:データを取得する方法: 1. Web ブラウザを使用する; 2. プログラミング言語を使用する; 3. データ クローラーを使用する; 4. API を使用する; 5. クローラーを使用するなど。
2023-11-10
コメント 0
2190

PHPを使用してデータを取得するにはどのような方法がありますか?
記事の紹介:PHP データのキャプチャ方法には、cURL ライブラリの使用、file_get_contents 関数の使用、Simple HTML DOM ライブラリの使用、サードパーティ ライブラリの使用などが含まれます。詳細な紹介: 1. cURL ライブラリを使用すると、PHP はデータのキャプチャに使用できる cURL 拡張機能を提供します。cURL ライブラリを使用すると、リクエスト ヘッダーの設定、POST または GET リクエストの送信、サーバーから返されるデータの取得が簡単に行えます。 2. file_get_contents関数メソッドなどを使用します。
2023-08-15
コメント 0
1306

BeautifulSoupを使用してWebページデータをスクレイピングする方法
記事の紹介:BeautifulSoup を使用して Web ページ データをクロールする方法 はじめに: インターネット情報時代において、Web ページ データは私たちが情報を取得するための主要なソースの 1 つです。 Web ページから有用な情報を抽出するには、Web ページのデータを解析してクロールするためのいくつかのツールを使用する必要があります。中でもBeautifulSoupはWebページから簡単にデータを抽出できる人気のPythonライブラリです。この記事では、BeautifulSoup を使用して Web ページ データをクロールする方法とサンプル コードを紹介します。 1. Beauをインストールする
2023-08-03
コメント 0
2166

Webスクレイピングとデータスクレイピングを実現するためのPHPとApache Nutchの統合
記事の紹介:インターネット時代の到来により、私たちは毎日膨大な量の情報やデータを扱っています。このプロセスでは、データの取得と収集が非常に重要な部分になります。開発者にとって、効率的な Web クローリングとデータ クローリングを実現する優れたツールを見つけることは、解決すべき問題となっています。数多くのクローリング ツールの中でも、ApacheNutch は、その強力な機能と優れたパフォーマンスにより、開発者の間で非常に人気のある選択肢となっています。同時に、PHP は成熟したバックエンド プログラミング言語として、
2023-06-25
コメント 0
1115
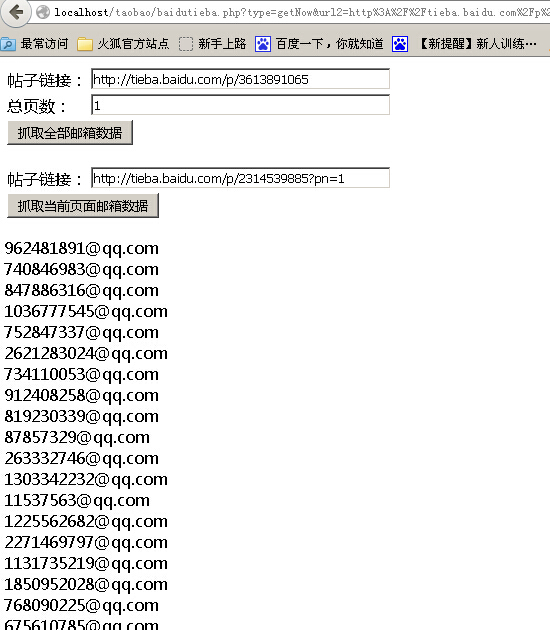
PHP网页抓取之抓取百度贴吧邮箱数据代码分享
記事の紹介:本文给大家介绍PHP网页抓取之抓取百度贴吧邮箱数据代码分享,程序实现了一键抓取帖子全部邮箱和分页抓取邮箱两个功能,感兴趣的朋友一起学习吧
2016-06-10
コメント 0
1104

PHP クローラーを使用して API インターフェース データをクロールするにはどうすればよいですか?
記事の紹介:PHP クローラーを使用して API インターフェース データをクロールするにはどうすればよいですか?クローラーは効率的なデータ スクレイピング ツールとして、Web ページから貴重なデータを抽出するためによく使用されます。実際の開発では、後続のデータ分析と処理のために、クローラを介して API インターフェイス データを取得する必要があることがよくあります。この記事では、PHP クローラー クラスを使用して API インターフェイス データをクロールする方法を紹介し、対応するコード例を添付します。ターゲット API インターフェイスを決定します。開始する前に、まず、インターフェイスの URL など、クロールする API インターフェイスを決定する必要があります。
2023-08-07
コメント 0
1459

PHP を使用してデータ スクレイピングと Web ページ解析機能を実装する方法
記事の紹介:PHP を使用してデータ キャプチャおよび Web ページ解析機能を実装する方法。現代のインターネット時代において、データは非常に貴重なリソースです。必要なデータを迅速かつ正確に取得できることは、データ分析、データ マイニング、または Web 開発の基本的なニーズです。 。 PHP プログラミング言語を使用すると、データ キャプチャと Web ページ解析機能を簡単に実装できます。この記事では、PHP を使用してデータ キャプチャおよび Web ページ解析機能を実装する方法を紹介し、対応するコード例を示します。 1. データ キャプチャでは、データ キャプチャに cURL ライブラリを使用します。
2023-09-05
コメント 0
1124

Python で Web データをスクレイピングする方法
記事の紹介:Python で Web スクレイピングを実行する方法 Web スクレイピングとは、インターネットから情報を取得するプロセスを指します。Python には、この目標の達成に役立つ強力なライブラリが多数あります。この記事では、Python を使用してネットワーク データをクロールする方法を紹介し、具体的なコード例を示します。必要なライブラリのインストール 始める前に、必要なライブラリをいくつかインストールする必要があります。その中で、次の 3 つのライブラリが最もよく使用されます。 urllib: URL からデータを取得するために使用されます。 request: より高度で簡潔なネットワーク リクエストです。
2023-10-20
コメント 0
882
phpQuery 数据抓取疑点
記事の紹介:
phpQuery 数据抓取疑问我想使用phpQuery 抓取某东产品的名字和价格,能取到产品名称,不能取到价格,因为源代码的价格是使用JS输出的,如果用Chrome浏览器审查元素是有价格的,应该怎样取得审查元素里的价格?------解决方案--------------------是ajax的吧?那就得多一次请求了如果是js代码,那就要用正则去匹
2016-06-13
コメント 0
889

Scrapy は、クローラー テンプレートが付属するデータ スクレイピング アプリケーションです。
記事の紹介:インターネット技術の継続的な発展に伴い、クローラー技術も広く使用されるようになりました。クローラー テクノロジーは、インターネット上のデータを自動的にクロールしてデータベースに保存することができ、データ分析やデータ マイニングに便利です。 Python の非常に有名なクローラー フレームワークである Scrapy には、ターゲット Web サイト上のデータを迅速にクロールし、ローカルまたはクラウド データベースに自動的に保存できるいくつかの一般的なクローラー テンプレートが付属しています。この記事では、Scrapy 独自のクローラー テンプレートを使用してデータをクロールする方法と、クロール後の使用方法を紹介します。
2023-06-22
コメント 0
806

PHP と REDIS を使用して Web クローリングとデータ スクレイピングを最適化する方法
記事の紹介:PHP と REDIS を使用して Web クローラーとデータ キャプチャを最適化する方法 はじめに: ビッグ データの時代において、データの価値はますます顕著になってきています。そのため、Web クローラーとデータ スクレイピングが研究開発の注目のスポットとなっています。ただし、大量のデータのクローリングは膨大なサーバー リソースを消費するため、クローリング プロセス中のタイムアウトや重複の問題も解決する必要があります。この記事では、PHP と REDIS テクノロジーを使用して Web クローリングとデータ スクレイピング プロセスを最適化し、それによって効率とパフォーマンスを向上させる方法を簡単に紹介します。 1. REDISREDISとは
2023-07-22
コメント 0
1361

Go言語でWebクローリングとデータスクレイピングを学ぶ
記事の紹介:Go 言語の Web クローラーとデータ キャプチャを学ぶ. Web クローラーは、インターネット上の特定のルールに従って Web ページを閲覧し、データをキャプチャできる自動プログラムです。インターネットの急速な発展とビッグデータ時代の到来により、データ収集は多くの企業や個人にとって不可欠な仕事になりました。 Go 言語は、高速かつ効率的なプログラミング言語として、Web クローラーやデータ キャプチャの分野で広く使用される可能性があります。 Go 言語の同時実行性の性質により、Go 言語は Web クローラーの実装に非常に適した言語になります。 Go 言語では、次のように使用できます。
2023-11-30
コメント 0
525

python抓取安居客小区数据的程序代码
記事の紹介:抓取数据不管用什么编程语言几乎都是可以实现了,今天我们需要采集安居客的小区数据,下面我们来看一个python抓取安居客小区数据的程序代码了,希望下文能够对大家有帮助。
2016-06-08
コメント 0
1993

Scrapy フレームワークの実践: Jianshu Web サイトのデータをクロールする
記事の紹介:Scrapy フレームワークの実践: Jianshu Web サイトのデータをクロールする Scrapy は、World Wide Web からデータを抽出するために使用できるオープンソースの Python クローラー フレームワークです。この記事では、Scrapy フレームワークを紹介し、それを使用して Jianshu Web サイトからデータをクロールします。 Scrapy のインストールScrapy は、pip や conda などのパッケージ マネージャーを使用してインストールできます。ここでは、pip を使用して Scrapy をインストールします。コマンドラインに次のコマンドを入力します: pipinstallscrapy インストールが完了したら
2023-06-22
コメント 0
1311

Python での Web スクレイピングとデータ抽出テクニック
記事の紹介:Python はさまざまなアプリケーションに選ばれるプログラミング言語となっており、その多用途性は Web スクレイピングの世界にも広がっています。ライブラリとフレームワークの豊富なエコシステムを備えた Python は、Web サイトからデータを抽出し、貴重な洞察を引き出すための強力なツールキットを提供します。データ愛好家、研究者、業界の専門家であっても、Python での Web スクレイピングは、オンラインで入手可能な膨大な量の情報を活用するための貴重なスキルとなります。このチュートリアルでは、Web スクレイピングの世界を深く掘り下げ、Web サイトからデータを抽出するために使用できる Python のさまざまなテクニックとツールを探索します。 Web スクレイピングの基本を明らかにし、この実践に関する法的および倫理的考慮事項を理解し、データ抽出の実践的な側面を詳しく掘り下げます。この記事の次の部分では
2023-09-16
コメント 0
1271

Java クローラー スキル: さまざまな Web ページからのデータ クローリングに対処する
記事の紹介:クローラー スキルの向上: Java クローラーがさまざまな Web ページ上のデータ クローリングにどのように対処するかには、特定のコード サンプルが必要です。 概要: インターネットの急速な発展とビッグ データ時代の到来により、データ クローリングの重要性がますます高まっています。強力なプログラミング言語として、Java のクローラー技術も大きな注目を集めています。この記事では、さまざまな Web ページ データのクローリングを処理する Java クローラーのテクニックを紹介し、読者がクローラーのスキルを向上させるのに役立つ具体的なコード例を示します。はじめに インターネットの普及により、私たちは大量のデータを簡単に入手できるようになりました。ただし、これらの数字は、
2024-01-09
コメント 0
902



