合計 10000 件の関連コンテンツが見つかりました

Visio2010 のリバース エンジニアリング データベース モデル図
記事の紹介:1. Visio で新しいデータベース モデル図を作成します。Visio2010 を開き、[ファイル] -> [新規作成] -> [データベース] -> [データベース モデル図] を選択します。データベースモデル図を作成すると、メニューバーに「データベース」というメニュー項目が追加されます。下の図を見てください。メニュー バーに追加のデータベース項目があります。 [リバース エンジニアリング] メニュー項目 [データベース]。リバース エンジニアリング ウィザードを開始し、リバース エンジニアリングの設定を段階的に完了します。 2.1. データベースとの接続を確立します。選択した Visio ドライバの種類によって、接続できるデータベースの種類と使用可能なオプションが決まります。データ ソースは、データベースの場所と接続情報を指定します。ここでは、Visio ドライバーとして MicrosoftSqlServer を選択し、データ ソースとして新しく作成した BASICDATA を選択します。 2.2
2024-06-02
コメント 0
1226
Visio2010でデータベースモデル図を作成する詳しい方法
記事の紹介:1. Visio で新しいデータベース モデル図を作成します。Visio2010 を開き、[ファイル] -> [新規作成] -> [データベース] -> [データベース モデル図] を選択します。データベースモデル図を作成すると、メニューバーに「データベース」というメニュー項目が追加されます。下の図を見てください。 メニューバーに追加のデータベース項目があります。 2. データベース内に作成された各テーブル、ビューなどを順に描画します。 インターフェースの左側が表示されたら、選択します。 [エンティティ] 描画モデルをマウスの左ボタンを押したまま、中央のルーラーで描画領域に直接ドラッグします。 次の主な作業は、テーブルのプロパティを設定することです。プログラムのメイン インターフェイス ウィンドウの下部にあるプロパティ設定を参照して、左側のカテゴリで [定義] を選択します。データ テーブルの物理名と概念名を順番に入力します。名前が矛盾している
2024-06-12
コメント 0
416

ICLR 2024 スポットライト | NoiseDiffusion: 拡散モデルのノイズを修正し、補間画像の品質を向上
記事の紹介:著者|PengfeiZheng Unit|USTC,HKBUTMLRGroup 近年、生成 AI の急速な発展により、テキストから画像への生成やビデオ生成などの注目を集める分野に大きな推進力が注入されています。これらの技術の中核は、拡散モデルの適用にあります。拡散モデルは、最初に連続的にノイズを追加する順方向プロセスを定義することによって画像を徐々にガウス ノイズに変更し、次に逆方向プロセスを通じてガウス ノイズを徐々に除去して鮮明な画像に変換して実際のサンプルを取得します。拡散常微分モデルは、生成された画像の値を補間するために使用され、ビデオや一部の広告クリエイティブの生成に大きな応用可能性があります。ただし、この方法を自然画像に適用すると、補間された画像効果が満足できない場合が多いことに気付きました。存在する
2024-05-06
コメント 0
1145

データベース設計において、ER 図をリレーショナル データ モデルに変換するプロセスはどのようなものですか?
記事の紹介:データベース設計において、E-R 図をリレーショナル データ モデルに変換するプロセスは、「論理設計フェーズ」に属します。 E-R 図は、現実世界の概念モデルを記述するために使用されます。論理設計段階の主な作業は、現実世界の概念データ モデルをデータベースの論理モデルに設計すること、つまり、データベースによってサポートされる論理データに適合させることです。特定のデータベース管理システムのモデル。
2021-05-07
コメント 0
30520
Visio でデータベース モデル図を表示する詳細な方法
記事の紹介:1. 以下に示すように、Visio を開きます。 2. 以下に示すように、「ファイル」、「新規」、「ソフトウェアおよびデータベース」をクリックします。 3. データベース モデル図を選択し、[作成] をクリックして、vsd ファイルを正常に作成します。以下に示すように。 4. 以下に示すように、左側のツールを選択し、エンティティをページにドラッグします。 5. ページの下部で、以下に示すようにエンティティ (テーブルなど) の関連情報を編集します。 6. 列をクリックすると、以下に示すようにキー名とデータ形式を設定できます。 7. 以下に示すように、pk をチェックしてテーブルの主キーを設定します。
2024-06-11
コメント 0
1137
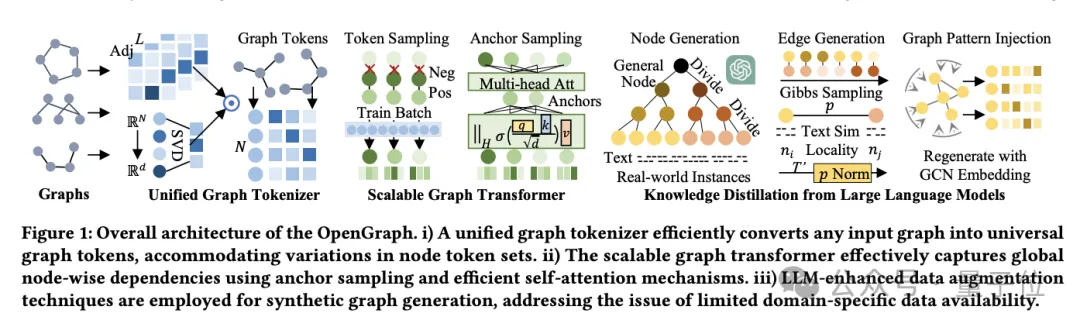
HKU の大規模なオープンソース グラフ基本モデル OpenGraph: 強力な一般化機能、新しいデータを予測するための順伝播
記事の紹介:グラフ学習の分野におけるデータ不足の問題を軽減する新しい方法があります。 OpenGraph は、さまざまなグラフ データセットでのゼロショット予測用に特別に設計された基本的なグラフベースのモデルです。香港大学データインテリジェンス研究所所長のChao Huangチームも、新しいタスクに対するモデルの適応性を向上させるためのモデルの改良および調整手法を提案した。現在、この作品はGitHubに公開されています。データ拡張技術を導入したこの研究では、グラフィカル モデルの汎化能力を強化する戦略の徹底的な探究に焦点を当てています (特にトレーニング データとテスト データに大きな違いがある場合)。 OpenGraph は、伝播予測を通じて順伝播を実行し、新しいデータのゼロサンプル予測を実現する一般的なグラフ構造モデルです。チームは目標を達成するために、
2024-05-09
コメント 0
391
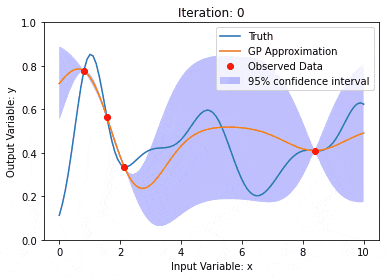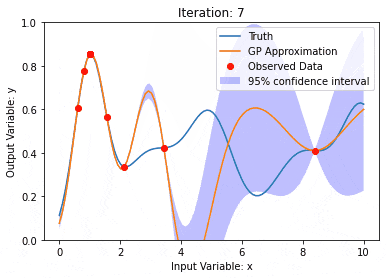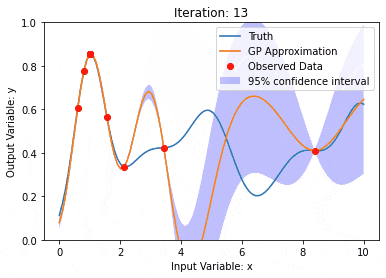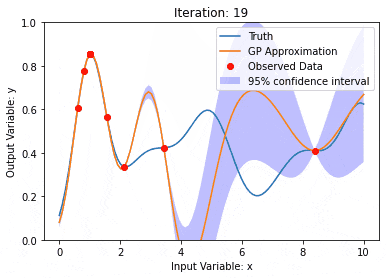
カーネル モデル ガウス プロセス (KMGP) を使用したデータ モデリング
記事の紹介:カーネル モデル ガウス プロセス (KMGP) は、さまざまなデータ セットの複雑さを処理するための高度なツールです。これは、カーネル関数を通じて従来のガウス プロセスの概念を拡張します。この記事では、KMGP の理論的基礎、実際の応用、課題について詳しく説明します。カーネル モデルのガウス プロセスは、従来のガウス プロセスの拡張であり、機械学習と統計で使用されます。 kmgp を理解する前に、ガウス過程の基礎知識を習得し、カーネル モデルの役割を理解する必要があります。ガウス プロセス (GP) は、ガウス分布で結合して分布する有限数の変数である一連の確率変数であり、関数の確率分布を定義するために使用されます。ガウス プロセスは、機械学習の回帰および分類タスクで一般的に使用され、データの確率分布を適合させるために使用できます。ガウス プロセスの重要な特徴は、不確実性の推定と予測を提供できることです。
2024-01-30
コメント 0
1050

Vue と ECharts4Taro3 の高度なチュートリアル: 混合チャート タイプのデータ視覚化を実装する方法
記事の紹介:Vue および ECharts4Taro3 の高度なチュートリアル: 混合チャート タイプのデータ視覚化を実装する方法 はじめに: 最新のデータ分析および視覚化では、混合チャート タイプのデータ表示が一般的な要件になっています。一般的なハイブリッド グラフの種類には、折れ線グラフ、棒グラフ、円グラフなどが含まれます。この記事では、Vue フレームワークと ECharts4Taro3 ライブラリを使用して、混合グラフ タイプのデータ視覚化を実装する方法を紹介します。 1. インストールと設定環境 まず、Vue と Taro をインストールし、新しいファイルを作成する必要があります。
2023-07-21
コメント 0
1441

高品質の AI データ ソリューションを見つける: ビッグ モデルの時代における企業の課題
記事の紹介:ビッグモデル時代の到来により、人工知能開発はモデル中心からデータ中心への変革が加速しています。 Qubit シンクタンクの「中国 AIGC データ アノテーション業界パノラマ レポート」は、現在大規模モデル データ ソリューションが多くの場所で開花しており、ワンストップのカスタマイズされたサービスに焦点を当て、大規模モデル開発のライフ サイクル全体 (事前トレーニングを含む) に焦点を当てていると指摘しました。 、監督と微調整、RLHF、レッドチームテスト、ベンチマークテストなど)、プロのデータサービスプロバイダー、大規模なモデル企業、AI企業、その他の関係者が関連するデータソリューションを考案しており、そのほとんどがワンストップです。カスタマイズされたサービス。垂直産業向けの大規模モデル データ ソリューションのケースとしてクラウド測定データを使用するこのソリューションは、継続的な事前トレーニング、タスク マイクロ加工など
2023-11-27
コメント 0
1005
AIデータの価値を高め、大型模型産業の発展を加速する
記事の紹介:人工知能産業の急速な発展に伴い、人工知能はあらゆる方向で商業化されています。 AI技術は金融、医療、製造、教育、セキュリティなど多くの分野で導入され、その活用シーンはますます豊富になり、データの重要性がますます高まっています。人工知能産業チェーンの重要なリンクとして、データの質と量は AI モデルの精度と信頼性を向上させる上で重要な役割を果たします。現在、人工知能(AI)は大型モデルを中心に急速に発展し、新たな時代をフルスピードで迎えています。高品質のシナリオベースの人工知能データ サービスの代表として、Cloud Measurement Data は、最先端の技術能力、優れたサービス品質、豊富な業界経験に依存して、人工知能業界に専門的で効率的かつ安全な AI データ サービスを提供します。
2023-11-03
コメント 0
861
大規模なモデルをトレーニングするための高品質のデータが不足していますか?新しい解決策を見つけました
記事の紹介:機械学習モデルのパフォーマンスを決定する 3 つの主要要素の 1 つであるデータが、大規模モデルの開発を制限するボトルネックになりつつあります。 「ガベージイン、ガベージアウト」[1] ということわざがあるように、アルゴリズムがどれほど優れていてコンピューティング リソースがどれほど強力であっても、モデルの品質はモデルのトレーニングに使用するデータに直接依存します。さまざまなオープンソースの大規模モデルの出現により、データ、特に高品質の業界データの重要性がさらに強調されるようになりました。ブルームバーグは、オープンソースの GPT-3 フレームワークに基づいて金融大規模モデル BloombergGPT を構築し、オープンソースの大規模モデル フレームワークに基づいて大規模な垂直産業モデルを開発する実現可能性を証明しました。実際、垂直産業向けのクローズドソースの軽量大規模モデルの構築またはカスタマイズは、国内の大規模モデルのスタートアップのほとんどが行っていることです。
2023-09-18
コメント 0
854

マルチオミックスデータを統合したBGIチームのグラフニューラルネットワークモデルSpatialGlueがNatureサブジャーナルに掲載されました
記事の紹介:編集者: KX 空間トランスクリプトミクスとマルチオミクス データの統合 空間トランスクリプトミクスは、単一細胞トランスクリプトミクスに続く主要な発展であり、マルチオミクス データの統合が重要になります。 SpatialGlue: 二重注意メカニズムを備えたグラフ ニューラル ネットワーク モデル シンガポール科学技術研究庁 (A*STAR)、BGI、上海交通大学付属仁吉病院の研究チームは、SpatialGlue と呼ばれるグラフ ニューラル ネットワークを提案しました。このモデルは、デュアル アテンション メカニズムを通じてマルチオミクス データを統合し、空間を認識した方法で組織サンプルの組織学的に関連する構造を明らかにします。 SpatialGlue の利点 SpatialGlue は、複数のデータ モダリティをそれぞれの空間コンテキストと組み合わせることができます。他の方法と比較して
2024-07-03
コメント 0
589

高品質なデータ供給能力を強化し、汎用人工知能大型モデル分野のイノベーションを促進する
記事の紹介:近年、大規模な事前トレーニングモデルは人工知能の進歩の重要な原動力の1つであり、人工知能工学の開発と普及のプロセスを加速しており、新世代のインテリジェントテクノロジーの基礎となることが期待されています。大規模人工知能モデルのブレークスルーは、高品質データの継続的な開発から生まれます。高品質データ供給能力の向上は、一般人工知能大規模モデル分野のイノベーションを促進する鍵です。2020 年の重要な研究では、モデルはそのパラメータとデータに関係しており、計算量と計算量の間にはべき乗則展開則、すなわち「ScalingLaws」が存在します。モデルのパラメータ、データ、計算量は指数関数的に増加しますが、テスト セットでのモデルの損失は指数関数的に減少し、モデルのパフォーマンスが向上していることを示します。小さい
2023-08-08
コメント 0
1421

柔軟なクラウドソーシング プラットフォームは、高品質のデータと効率的な人間の調整によって大規模模型産業を強化します
記事の紹介:8月23日、NetEase Fuxi User Portrait Groupのテクニカルディレクターであるウー・ルンゼ博士が、「沸騰する資本、波に乗るAGI」をテーマとする大型模型産業テーマフォーラムに招待されました。フォーラムでは、「大規模モデル実装アプリケーションのための効率的な人的調整」をテーマに講演し、NetEase Fuxi が大規模モデル データの閉ループの作成にどのように役立つかを大規模モデル業界の関連企業に紹介し、共有しました。大規模なモデルデータの閉ループを低コストで構築する方法、高品質のデータベースの事例と経験。大規模モデルの 3 つの要素であるデータ、コンピューティング能力、アルゴリズムのうち、事前トレーニング モデルの規模を強化し、データ品質を向上させることは、より優れた人工知能の効果を達成するための重要な方法です。ただし、単にモデル サイズを大きくするだけでは、必ずしも良い結果が得られるとは限りません。現実世界の多くのタスクに主観性が存在するモデルをスケールアップする
2024-01-22
コメント 0
932

Google MIT の最新調査によると、高品質のデータを取得するのは難しくなく、大規模なモデルが解決策となります
記事の紹介:現在の大規模モデルのトレーニングでは、高品質のデータを取得することが大きなボトルネックになっています。数日前、OpenAIはニューヨーク・タイムズ紙から訴訟を起こされ、数十億ドルの賠償を求められた。訴状にはGPT-4による盗作の複数の証拠が列挙されている。ニューヨーク・タイムズは、GPTなどの大型モデルのほぼすべてを廃棄するよう要求した。 AI 業界の多くの著名人は、「合成データ」がこの問題に対する最良の解決策である可能性があると長い間信じてきました。以前、Google チームは、LLM を使用して人間のラベル設定を置き換える手法である RLAIF も提案しましたが、その効果は人間に劣りません。現在、Google と MIT の研究者は、大規模なモデルから学習することで、実際のデータを使用してトレーニングされた最適なモデルを表現できることを発見しました。この最新の方法は SynCLR と呼ばれ、完全に合成画像と合成レンダリングから派生しています。
2024-01-14
コメント 0
1308

Go の SectionReader モジュールを利用して、大きなデータ ファイルの並べ替えと要約を効率的に処理するにはどうすればよいでしょうか?
記事の紹介:Go の SectionReader モジュールを利用して、大きなデータ ファイルの並べ替えと要約を効率的に処理するにはどうすればよいでしょうか?大きなデータ ファイルを処理する場合、多くの場合、ファイルを並べ替えて要約する必要があります。ただし、ファイル全体を一度に読み取る従来の方法は、メモリ制限を超える可能性があるため、大きなデータ ファイルには適していません。幸いなことに、Go 言語の SectionReader モジュールは、この問題に対処する効率的な方法を提供します。 SectionReader は Go 言語のパッケージです。
2023-07-23
コメント 0
1176

mysql はどのような種類のイメージを保存しますか?
記事の紹介:Mysql はイメージを BLOB、MEDIUMBLOB、LONGBLOB の 3 つのタイプで保存します。具体的な紹介: 1. BLOB タイプはバイナリ データを保存でき、アバターやアイコンなどの小さな画像の保存に適しています; 2. MEDIUMBLOB タイプは中サイズのバイナリ データを保存でき、わずかに大きい画像の保存に適しています3. LONGBLOB 型 より大きなバイナリ データを保存でき、大きな画像や高解像度で保存する必要がある画像の保存に適しています。
2023-07-18
コメント 0
10685