合計 10000 件の関連コンテンツが見つかりました

PHP8のデータ型を詳しく解説:ビッグデータ処理を最適化し、大量のデータを簡単に扱える
記事の紹介:PHP8 ビッグ データ タイプの包括的な分析: アプリケーションによる大量のデータの処理が容易になります 概要: インターネットの急速な発展に伴い、データ量は日々増加しています。開発者にとって、大量のデータをいかに効率的に処理するかが緊急の課題となっています。 PHP は人気のあるプログラミング言語であり、最新バージョンの PHP8 では、大量のデータをより簡単に処理できるようにする一連の強力なデータ型が提供されています。この記事では、PHP8 の 8 つの主要なデータ型を詳細に分析し、開発者がよりよく理解できるようにするための具体的なコード例を示します。
2024-01-05
コメント 0
1370

PHP で大量のデータを保存およびクエリするにはどうすればよいですか?
記事の紹介:インターネットや情報技術の発展に伴い、ビッグデータが注目を集めています。多くの企業がビッグ データのストレージと分析を行っており、一般的に使用される Web 開発言語として、PHP には大規模なデータのストレージとクエリに適したソリューションが数多くあります。この記事では、PHP で大量のデータを保存およびクエリする方法を紹介します。 1. 大容量データ ストレージ MySQL は一般的に使用されるリレーショナル データベースであり、データベースとテーブルを通じて大容量データを保存できます。データベース シャーディングとテーブル シャーディングとは、大規模なデータベースを複数の小さなデータベースに分割することを指します。
2023-05-21
コメント 0
954

RiSearch PHP が大量のデータの検索と分析を処理する方法
記事の紹介:RiSearchPHP が大量のデータの検索と分析にどのように対処するかについては、具体的なコード例が必要です 概要: インターネットの急速な発展に伴い、データ量は増加する傾向にあります。この場合、膨大なデータをいかに効率的に検索・分析するかが課題となります。全文検索エンジンとして、RiSearchPHP は強力な検索および分析機能を提供しており、大量のデータの検索および分析のニーズに対処するのに役立ちます。はじめに: 今日のビッグデータ時代では、大量のデータの処理が重要になっています。
2023-10-03
コメント 0
1138

PHP と phpSpider を使用して大量のデータをバッチでクロールする方法に関するヒントを共有します。
記事の紹介:PHP と phpSpider を使用して大量のデータをバッチでクロールする方法に関するヒントを共有します。インターネットの急速な発展に伴い、大量のデータは情報時代における最も重要なリソースの 1 つになりました。多くの Web サイトやアプリケーションにとって、このデータをクロールして取得することは非常に重要です。この記事では、PHP および phpSpider ツールを使用して大量のデータのバッチ クロールを実現する方法を紹介し、開始に役立ついくつかのコード例を示します。はじめに phpSpider は、PHP ベースのオープンソース クローラー ツールです。
2023-07-22
コメント 0
853

JavaScript 関数を使用したビッグ データ処理: 大量データを処理するための主要な方法
記事の紹介:JavaScript は、Web 開発やデータ処理で広く使用されているプログラミング言語であり、ビッグデータを処理する機能を備えています。この記事では、大量のデータを処理する際の JavaScript 関数の主なメソッドを紹介し、具体的なコード例を示します。ビッグデータを扱う場合、パフォーマンスは非常に重要です。 JavaScript の組み込み関数と構文は、少量のデータを処理する場合には良好なパフォーマンスを発揮しますが、データ量が増加すると、処理速度が大幅に低下します。ビッグデータを扱うためには、何らかの最適化策を講じる必要があります。 1.避ける
2023-11-18
コメント 0
1053

Java と Redis を使用して大量のデータを効率的に保存および取得する
記事の紹介:Java と Redis を使用した大量データの効率的な保存と取得 要約: 大量データの保存と取得は、コンピュータ サイエンスの分野において常に重要な問題です。最新のインターネット アプリケーションでは、大量のデータの保存と取得の効率がシステムのパフォーマンスとユーザー エクスペリエンスにとって非常に重要です。この記事では、Java と Redis を使用して効率的な大規模データの保存と取得システムを構築する方法を紹介します。データ モデルを適切に設計し、キャッシュ ツールとして Redis を使用し、Java の効率的な API 操作を組み合わせることで、高速なデータ処理を実現できます。
2023-07-29
コメント 0
1440

MySQL と Oracle: 大規模なデータ ストレージとアクセスのサポートの比較
記事の紹介:MySQL と Oracle: 大規模なデータ ストレージとアクセスのサポートの比較 今日のビッグ データ時代では、大規模なデータ ストレージとアクセスに対する需要が日に日に高まっています。 MySQL と Oracle は、非常に評判の高い 2 つのリレーショナル データベース管理システム (RDBMS) ですが、大規模なデータのストレージとアクセスにおいて一定の違いがあります。この記事では、この分野における MySQL と Oracle のサポートの比較を検討し、それを説明するコード例を提供します。 1. ストレージ容量とパフォーマンス MySQL と Oracle にはストレージ容量があります
2023-07-13
コメント 0
1267

Ruby 開発における Redis の応用: 大量のデータをキャッシュする方法
記事の紹介:Ruby 開発における Redis の応用: 大量のデータをキャッシュする方法 はじめに: 最新のアプリケーション開発では、効率的なデータ処理が重要です。キャッシュは、大量のデータを扱うアプリケーションの一般的な最適化戦略です。 Redis は、高いパフォーマンスと柔軟性を備え、Ruby 言語との互換性が高い、非常に人気のあるキャッシュ データベースです。この記事では、Redis を使用して Ruby 開発で大量のデータをキャッシュし、アプリケーションのパフォーマンスと効率を向上させる方法を紹介します。 Redis のインストールと構成: 最初に
2023-07-30
コメント 0
1276

Java のビッグ データ処理フレームワークを使用して大量のデータを分析および処理するにはどうすればよいですか?
記事の紹介:Java のビッグ データ処理フレームワークを使用して大量のデータを分析および処理するにはどうすればよいですか?インターネットの急速な発展に伴い、膨大なデータの処理が重要な課題となっています。このような膨大な量のデータに直面した場合、従来のデータ処理方法ではもはやニーズに十分に対応できないため、ビッグデータ処理フレームワークの登場が解決策となっています。 Java 分野では、Apache Hadoop や Apache Spark など、成熟したビッグ データ処理フレームワークが多数あります。通過方法はこちら
2023-08-02
コメント 0
1416

Vue フレームワークで大量のデータの統計グラフを実装する方法
記事の紹介:Vue フレームワークで大量のデータの統計グラフを実装する方法 はじめに: 近年、データ分析と視覚化があらゆる分野でますます重要な役割を果たしています。フロントエンド開発において、グラフはデータを表示する最も一般的で直感的な方法の 1 つです。 Vue フレームワークは、ユーザー インターフェイスを構築するための進歩的な JavaScript フレームワークであり、グラフを迅速に作成し、大量のデータを表示するのに役立つ多くの強力なツールとライブラリを提供します。この記事では、大量のデータの統計グラフを Vue フレームワークで実装する方法を紹介します。
2023-08-25
コメント 0
1672

大量のデータの検索リクエストを処理するために php Elasticsearch を最適化するにはどうすればよいですか?
記事の紹介:大量のデータの検索リクエストを処理するために phpElasticsearch を最適化するにはどうすればよいですか?要約: データの規模が拡大し続けるにつれて、検索エンジンに対する要件はますます高くなっており、大量のデータに対する検索リクエストを処理するために phpElasticsearch を最適化する方法が非常に重要な問題となっています。この記事では、最適化方法と具体的なコード例を紹介することで、読者がこの問題を解決できるように支援します。バッチ挿入を使用する: データの量が多い場合、バッチ挿入により書き込みパフォーマンスを向上させることができます。以下は例です
2023-09-13
コメント 0
811

PHP 配列のキーと値の交換: 大規模なデータ シナリオにおけるパフォーマンスのボトルネックと解決策
記事の紹介:ハッシュ テーブル実装を使用すると、PHP の大規模データ配列のキーと値の交換のパフォーマンス ボトルネックを効果的に解決できます。 パフォーマンス ボトルネック: array_flip() 関数は、大規模データ シナリオでは O(n) の時間計算量があり、パフォーマンスが低下します。 。効率的なソリューション: ハッシュ テーブル データ構造を使用すると、平均時間計算量が O(1) になり、パフォーマンスが大幅に向上します。
2024-05-04
コメント 0
585

PHPフラッシュセールシステムにおける大規模なデータストレージとページングクエリの最適化
記事の紹介:PHP フラッシュ セール システムにおける大容量データ ストレージとページング クエリの最適化 1. はじめに 電子商取引業界の急速な発展に伴い、さまざまなプロモーション活動がユーザーを引き付けるための重要な手段となり、高度に集中したオンライン プロモーションとしてのフラッシュ セールが行われています。システムのパフォーマンスと安定性には、非常に高い要件が求められます。その中でも、大規模なデータ ストレージとページング クエリの最適化は、効率的なフラッシュ セール システムを構築するための鍵の 1 つです。この記事では、PHP フラッシュ セール システムで大規模なデータ ストレージとページング クエリの最適化を実行する方法を紹介し、具体的なコード例を示します。 2. 大容量データストレージフラッシュセール
2023-09-22
コメント 0
1338

大量のデータを処理する必要があるアプリケーションを構築するのに最適な PHP フレームワークはどれですか?
記事の紹介:PHP で大量のデータを処理する場合、特定のニーズと次の基準に基づいて最適なフレームワークが決定されます。 パフォーマンス: 大量のデータを効率的に処理し、高速な応答時間を維持します。スケーラビリティ: データ量の増加に応じて簡単に拡張でき、ボトルネックを回避します。同時実行性: 高スループットのアプリケーションに対処するために同時データ処理をサポートします。コミュニティ サポート: 問題を迅速に解決するための活発なコミュニティと豊富なドキュメント。
2024-06-02
コメント 0
607

Nginx Proxy Manager と分散ストレージ システムの統合: 大規模なデータ アクセスの問題を解決
記事の紹介:NginxProxyManager と分散ストレージ システムの統合: 大量のデータ アクセスの問題を解決するには、特定のコード サンプルが必要です はじめに: ビッグ データ時代の到来により、多くの企業は大量のデータを処理するという課題に直面しています。従来のシングルノード ストレージ システムでは、高度な同時データ要求やリアルタイム データ処理のニーズを満たすことができません。この問題を解決するために、多くの企業が大量のデータを処理するために分散ストレージ システムを導入し始めています。この記事では、NginxProxyManager を分散ストレージ システムと統合する方法を紹介します。
2023-09-27
コメント 0
717

Ruby 開発における Redis の応用: 大量のユーザー データをキャッシュする方法
記事の紹介:Ruby 開発における Redis の応用: 大量のユーザー データをキャッシュする方法 最新の Web サイトやアプリケーションでは、データへの高速アクセスと応答時間がユーザー エクスペリエンスにとって非常に重要です。ただし、大量のユーザー データと高い同時実行性に直面すると、データベースのパフォーマンスが制限される可能性があります。この問題を解決するために、開発者はキャッシュ テクノロジを使用してデータ アクセスを高速化できます。 Redis は、高速、柔軟、スケーラブルなキャッシュ ソリューションを提供する、一般的に使用されるメモリ内キー/値ストレージ システムです。この記事ではその方法を紹介します
2023-07-31
コメント 0
1262

HP与Oracle在海量数据业务展开竞争
記事の紹介:6月20日HP公司发布Vertica Analytics Platform 5.0版,最新版将与HP自己的硬件产品结合到一起。HP在今年早些时候收购了Vertica,这将帮助HP在逐渐升温的海量数据市场发挥关键作用。 Vertica基于列存储。基于列存储的设计相比传统面向行存储的数据库具有巨大
2016-06-07
コメント 0
2194

世界初!チャイナユニコム、3,000キロメートルにわたる広域高スループットの大量データのロスレス伝送の検証を完了
記事の紹介:5月17日のニュースによると、チャイナユニコムの公式公式アカウントによると、チャイナユニコムグループは最近、インテリジェントコンピューティング/スーパーコンピューティングのビジネスアクセスと相互接続の実現に向けて重要な課題に共同で取り組むため、チャイナユニコム研究所、中国通信設計研究所などの部門を組織したという。世界初、実伝送距離3,000kmを超える大容量データの広域高スループットロスレス伝送検証。インテリジェント コンピューティングおよびスーパーコンピューティングのビジネス シナリオでは、従来の 100M またはギガビットの帯域幅を介したテラバイト レベルの大規模データの伝送の適時性が要件を満たすことができず、より高速な専用線を介した伝送コストが高すぎることが報告されています。したがって、大量のデータを効率的かつロスレスで送信することが業界では常に課題となっています。今回、チャイナユニコムの全国バックボーン全光ROADMネットワークと169のバックボーンインターネットに基づいて、上海インテリジェントコンピューティングビジネストレーニングデータが寧夏中衛インテリジェントコンピューティングトレーニングクラスターにインポートされました。
2024-06-01
コメント 0
883
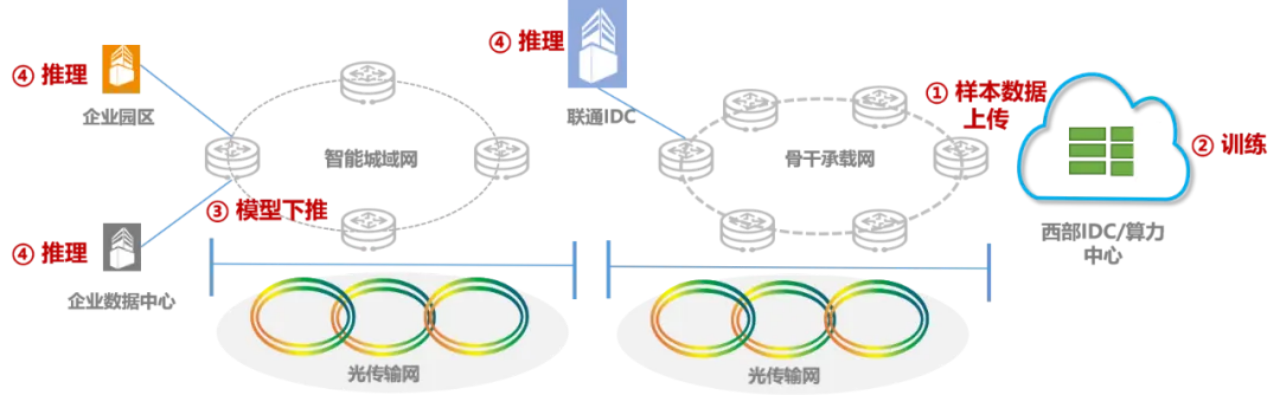
チャイナユニコムは世界で初めて、3,000キロメートルにわたる大規模データの広域高スループットロスレス伝送の検証を完了
記事の紹介:5月16日のニュースによると、チャイナユニコムは本日、チャイナユニコムグループがチャイナユニコム研究所、中勲設計研究所、上海支社、寧夏支社などの部門を組織し、インテリジェントコンピューティング/スーパーコンピューティングのビジネスアクセスと相互接続の実現に向けた重要な問題に共同で取り組むことを発表したと発表した。世界初、実伝送距離3,000kmを超える大容量データの広域高スループットロスレス伝送検証を既存ネットワーク上で完了。インテリジェント コンピューティングおよびスーパーコンピューティングのビジネス シナリオでは、従来の 100M またはギガビットの帯域幅を介してテラバイト レベルの大量のデータを送信するという適時性の要件を満たすことは困難であり、より高速な専用回線を介して効率的かつロスレスでデータを送信するにはコストが高すぎます。大量のデータは常に業界標準の問題です。今回、チャイナユニコムの全国バックボーン全光ROADMネットワークと169のバックボーンインターネットに基づいて、上海インテリジェントコンピューティングビジネストレーニングデータが寧夏中衛インテリジェントコンピューティングトレーニングクラスターにインポートされました。
2024-05-30
コメント 0
998

