合計 10000 件の関連コンテンツが見つかりました

データ不足がモデルトレーニングに及ぼす影響
記事の紹介:データ不足がモデル トレーニングに与える影響には、特定のコード サンプルが必要です。機械学習と人工知能の分野では、データはモデルをトレーニングするための中核要素の 1 つです。しかし、実際に私たちがよく直面する問題はデータ不足です。データ不足とは、トレーニング データの量が不足していること、またはアノテーション付きデータが不足していることを指し、この場合、モデルのトレーニングに一定の影響を及ぼします。データ不足の問題は、主に次の側面に反映されます。 過学習: トレーニング データの量が不十分な場合、モデルは過学習する傾向があります。過学習とは、モデルがトレーニング データに過剰に適応することを指します。
2023-10-08
コメント 0
1413

モデルトレーニングにおけるデータ前処理の重要性
記事の紹介:モデルトレーニングにおけるデータ前処理の重要性と具体的なコード例 はじめに: 機械学習およびディープラーニングモデルのトレーニングプロセスにおいて、データ前処理は非常に重要かつ不可欠なリンクです。データ前処理の目的は、一連の処理ステップを通じて生データをモデルのトレーニングに適した形式に変換し、モデルのパフォーマンスと精度を向上させることです。この記事の目的は、モデル トレーニングにおけるデータ前処理の重要性について説明し、一般的に使用されるデータ前処理のコード例をいくつか示すことです。 1. データ前処理の重要性 データクリーニング データクリーニングとは、
2023-10-08
コメント 0
1288

データ分割手法と落とし穴 - トレーニング セット、検証セット、テスト セットの使用方法
記事の紹介:信頼性の高い機械学習モデルを構築するには、データセットの分割が不可欠です。分割プロセスには、データ セットをトレーニング セット、検証セット、およびテスト セットに分割することが含まれます。この記事では、これら 3 つのコレクションの概念、データ分割手法、および発生しやすい落とし穴について詳しく紹介することを目的としています。トレーニング セット、検証セット、およびテスト セット トレーニング セット トレーニング セットは、データ内の隠れた特徴/パターンをモデルが学習できるようにトレーニングするために使用されるデータ セットです。各エポックで、同じトレーニング データが繰り返しニューラル ネットワーク アーキテクチャに供給され、モデルはデータの特性を学習し続けます。モデルがすべてのシナリオでトレーニングされ、将来起こり得るデータ サンプルを予測できるように、トレーニング セットには多様な入力セットが含まれている必要があります。検証セット 検証セットは、トレーニング中にモデルのパフォーマンスを検証するために使用される、トレーニング セットとは別のデータのセットです。
2024-01-22
コメント 0
807

C++ を使用した機械学習モデルのトレーニング: データの前処理からモデルの検証まで
記事の紹介:C++ での ML モデルのトレーニングには、次の手順が含まれます。 データの前処理: データの読み込み、変換、エンジニアリングを行います。モデルのトレーニング: アルゴリズムを選択し、モデルをトレーニングします。モデルの検証: データセットを分割し、パフォーマンスを評価し、モデルを調整します。これらの手順に従うことで、C++ で機械学習モデルを正常に構築、トレーニング、検証できます。
2024-06-01
コメント 0
660

週のキャンプ学習
記事の紹介:私は思い切って、LuxDevHQ が主催する初めてのデータ キャリア ブート キャンプに参加することにしました。これは、実践的なデータ スキルを身につける 5 週間のブートキャンプです。ブートキャンプは、少なくとも 4 つの分野でさまざまなデータ スキルを習得することを目的としています。
2024-08-07
コメント 0
1130

YOLOv7 モデルをトレーニングし、AI 火災検知を開発する
記事の紹介:1. データ セットの準備: データ セットは、煙と火でマークされた合計 6,000 個の火災画像を含むオープン ソース画像を使用します。 Fire and Smoke プロジェクトはトレーニングに YOLO を使用しています。データを YOLO 形式に変換し、トレーニング セットと検証セットに分割しました。データセット ディレクトリを参照してください。 2. トレーニングについては、YOLOv7 公式 Web サイトのトレーニング プロセスのドキュメントを参照してください。 data/coco.yaml ファイルを変更し、トレーニング データのパスとカテゴリを構成します。事前トレーニング済みモデル yolov7.pt をダウンロードすると、トレーニングを開始できます 3. 火災監視トレーニングが完了したら、yolov7 ディレクトリの下の run ディレクトリで生成されたモデル ファイル best.pt を見つけます。私はトレーニングします
2023-05-11
コメント 0
996
NVIDIA が新時代を開く: ロボット トレーニング データ用の「永久運動マシン」
記事の紹介:これまでの合成データのほとんどは AI の大規模モデルのトレーニングに使用されていましたが、今回 NVIDIA はロボットのトレーニング用に「データ倉庫」を構築しました ロボット技術の開発ペースが他の AI 分野に大きく遅れている主な理由の 1 つは、データの。わずか 200 人の人間によるデモンストレーション ソース データで、システムは 50,000 のトレーニング データを直接生成できます。 AIによる膨大なデータ需要により、データリソースがほぼ枯渇しつつあるため、さまざまな企業がデータを取得する「新たな方法」、つまり独自のデータを「作成」する方法を模索し始めています。しかし、これまでの合成データのほとんどは大規模な AI モデルのトレーニングに使用されていましたが、今回 NVIDIA はロボットのトレーニング用に「データ倉庫」を作成しました。 NVIDIA とテキサス大学オースティン校による最近の研究論文では、「Mimic」と呼ばれる新技術が発表されました。
2023-10-30
コメント 0
709

データ拡張技術によるモデルの学習効果向上の課題
記事の紹介:データ拡張テクノロジーのモデル トレーニング効果を向上させるには、特定のコード サンプルが必要です。近年、深層学習は、コンピューター ビジョンや自然言語処理などの分野で大きな進歩を遂げています。ただし、シナリオによっては、データ拡張テクノロジーのサイズが小さいため、データセット、モデル 一般化能力と精度が満足のいくレベルに達するのは困難です。現時点では、データ拡張テクノロジーがトレーニング データセットを拡張し、モデルの一般化能力を向上させることで重要な役割を果たすことができます。データ拡張とは、元のデータに対する一連の変換と変換を指します。
2023-10-10
コメント 0
1457

貧困は私を準備させてくれる
記事の紹介:1. 事前トレーニングは必要ですか? 事前トレーニングの効果は直接的ですが、多くの場合、必要なリソースが法外なものになります。このような事前トレーニング方法があれば、必要な計算能力、データ、手動リソースは非常に少なく、たった 1 人の人間とオリジナルのコーパス 1 枚のカードから始めることができます。教師なしデータ処理と事前トレーニングを独自のドメインに転送した後、ゼロサンプル NLG、NLG、およびベクトル表現の推論機能を取得できます。他のベクトル表現の再現能力は BM25 を超えています。試すことに興味がありますか?何かをやりたいかどうかは、インプットとアウトプットを天秤にかけることによって決まります。事前トレーニングは非常に重要であり、実装する前にいくつかの前提条件とリソース、および期待される十分なメリットが必要です。通常必要な条件は次のとおりです: 十分なコーパス構築 一般に、量よりも質の方が希少であるため、コーパスは
2023-06-26
コメント 0
830

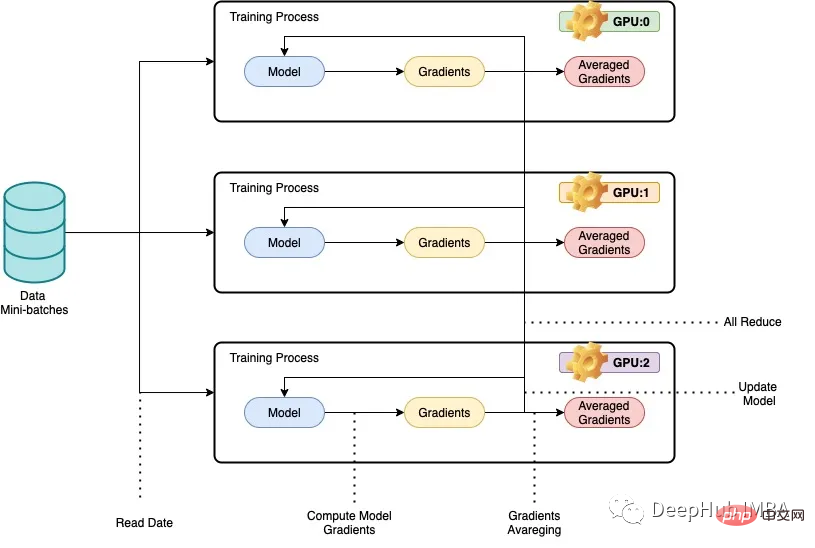
PyTorch 並列トレーニング DistributedDataParallel の完全なコード例
記事の紹介:大規模なデータセットを使用して大規模なディープ ニューラル ネットワーク (DNN) をトレーニングするという問題は、ディープ ラーニングの分野における大きな課題です。 DNN とデータセットのサイズが増加するにつれて、これらのモデルをトレーニングするための計算要件とメモリ要件も増加します。そのため、コンピューティング リソースが限られている 1 台のマシンでこれらのモデルをトレーニングすることが困難または不可能になります。大規模なデータセットを使用して大規模な DNN をトレーニングする際の主な課題には次のようなものがあります。 長いトレーニング時間: モデルの複雑さとデータセットのサイズによっては、トレーニング プロセスが完了するまでに数週間、場合によっては数か月かかる場合があります。メモリの制限: 大規模な DNN では、トレーニング中にすべてのモデル パラメーター、勾配、中間アクティベーションを保存するために大量のメモリが必要になる場合があります。これにより、メモリ不足エラーが発生し、単一マシンでトレーニングできる内容が制限される可能性があります。
2023-04-10
コメント 0
1335


AI学習データは著作権の問題を心配する必要はありませんか?日本政府の立場が激しい議論を巻き起こした
記事の紹介:生成 AI がブームになっている今、その背後にあるモデルをトレーニングするために使用される情報データの著作権問題が常に人々の注目の的となっています。法的なトレーニング データとは何とみなされますか?うっかり他人の著作権を侵害してしまうことはありますか?これに関連して、一部の海外メディアは、日本の政府の人工知能戦略委員会が5月26日、人工知能の訓練に使用されるデータに著作権法の遵守を強制しないとする草案を提出したと報じた。日本の文部科学大臣(国内の文部省に相当)の長岡桂子氏は現地会議でこのニュースを認め、日本の法律はAIトレーニングに使用される教材の著作権を保護していないと述べた。出典:長岡恵子氏の文部科学省公式ウェブサイト 具体的には、4月24日、衆議院決算管理監視委員会第二小委員会において、紀伊議員が発言した。たかし
2023-06-03
コメント 0
709

自己訓練の概念と半教師あり学習との関係
記事の紹介:自己トレーニングは、滑らかさとクラスタリングの仮定を含む半教師あり分類方法です。したがって、自己ラベル付けまたは意思決定指向学習とも呼ばれます。一般に、ラベル付きデータセットにデータ生成プロセスに関する多くの情報が含まれており、ラベルなしサンプルがアルゴリズムを微調整するためにのみ使用される場合は、セルフ トレーニングが適切な選択となります。ただし、これらの条件が満たされていない場合、自己トレーニングの結果は理想的ではありません。したがって、自己トレーニングはラベル付けされたサンプルに大きく依存します。自己トレーニングの各ステップでは、現在の決定関数に従ってラベルのないデータにラベルを付け、予測を使用して再トレーニングします。自己トレーニングの仕組み アルゴリズムを自己トレーニングして、以前に学習した別の教師ありモデルによって予測された擬似ラベルを適合させます。自己トレーニングには次のような重要なポイントがあります。データ インスタンスはトレーニング セットとテスト セットに分割され、分類アルゴリズムはラベル付けされたトレーニング セット上でトレーニングされます。
2024-01-23
コメント 0
714

Huggingface 微調整 BART のコード例: 翻訳用に新しいタグをトレーニングするための WMT16 データ セット
記事の紹介:カスタム データセットで新しいマーカーをトレーニングするなど、翻訳タスクで新しいアーキテクチャをテストしたい場合、扱いが面倒になるため、この記事では新しいマーカーを追加するための前処理手順を紹介します。モデルを微調整する方法。 Huggingface Hub には事前トレーニングされたモデルが多数あるため、事前トレーニングされたタガーを見つけるのは簡単です。ただし、マーカーを追加するのは少し難しいかもしれません。実装方法を完全に紹介します。まず、データセットを読み込み、前処理します。データセットの読み込み WMT16 データセットとそのルーマニア語と英語のサブセットを使用します。 load_dataset() 関数は、Huggingface から利用可能なデータセットをダウンロードしてロードします。
2023-04-10
コメント 0
1366

ローラをコンフィユイと訓練する
記事の紹介:この記事では、ComfyUI を使用して LORA モデルを効率的にトレーニングするための包括的なガイドを提供します。ハイパーパラメータの最適化、データ拡張、転移学習、正則化のための最適な設定と手法を探ります。ユーザーの友人
2024-09-02
コメント 0
976




