合計 10000 件の関連コンテンツが見つかりました

弱い教師あり学習におけるラベル欠落の問題
記事の紹介:弱教師あり学習におけるラベル欠落の問題とコード例 はじめに: 機械学習の分野では、教師あり学習は一般的に使用される学習方法です。ただし、大規模なデータセットに対して教師あり学習を実行する場合、データに手動でラベルを付けるのに必要な時間と労力は膨大です。そこで、弱教師あり学習が登場しました。弱い教師あり学習とは、トレーニング データ内の一部のサンプルのみが正確なラベルを持ち、ほとんどのサンプルが曖昧または不完全に正確なラベルしか持たないことを意味します。ただし、ラベル欠落の問題は、弱教師あり学習における重要な課題です。 1. ラベル欠落問題の背景
2023-10-08
コメント 0
838

ロジスティック回帰、分類: 教師あり機械学習
記事の紹介:分類とは何ですか?
定義と目的
分類は、データを事前定義されたクラスまたはラベルに分類するために機械学習とデータ サイエンスで使用される教師あり学習手法です。これには、i を割り当てるモデルのトレーニングが含まれます。
2024-07-19
コメント 0
462

HTML5 実践および分析フォーム - テキスト ボックス スクリプト
記事の紹介:フォーム関連のものを記述する場合、テキスト ボックスをマークするラベルは通常 2 つあります。1 つは単一行のテキスト ボックスの入力ラベル、もう 1 つは複数行のテキスト ボックスのテキストエリア ラベルです。これら 2 つのラベルは比較的似ていますが、違いもあります。
2017-02-11
コメント 0
1838
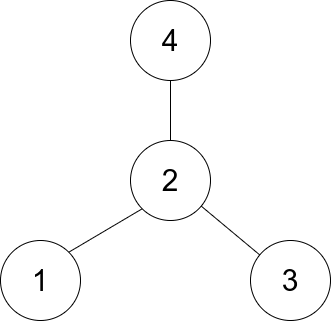
スターグラフの中心を見つける
記事の紹介:1791. 星図の中心を見つける
簡単
1 から n までのラベルが付けられた n 個のノードで構成される無向スター グラフがあります。スター グラフは、1 つの中心ノードと、その中心ノードを他のすべてのノードに接続する正確に n - 1 個のエッジがあるグラフです。
よ
2024-07-18
コメント 0
511

PHPで開発したタブラベル切り替えをWeChatアプレットに実装する方法
記事の紹介:WeChat ミニ プログラムの開発に伴い、ミニ プログラムの開発に PHP 言語を使用する開発者が増えています。タブ切り替え機能は小さなプログラムでよく使われる機能ですが、この記事ではPHPを使ってこの機能を実装する方法を紹介します。 1. タブラベル切り替えの基本実装 タブラベル切り替えは、複数のページを切り替える機能です。 WeChat ミニ プログラムでは、通常、tabBar コンポーネントを使用してこの機能を実装します。通常、単純な tabBar コンポーネントには複数のページが含まれており、各ページは異なるページに対応します。
2023-06-03
コメント 0
2039

クロスエントロピーとは? クロスエントロピー最小化アルゴリズム
記事の紹介:機械学習および深層学習モデルは、回帰および分類の問題を解決するために一般的に使用されます。教師あり学習では、モデルはトレーニング中に入力を確率的出力にマッピングする方法を学習します。モデルのパフォーマンスを最適化するために、予測結果と真のラベル間の差異を評価するために損失関数がよく使用されます。その中でクロスエントロピーは一般的な損失関数です。モデルによって予測された確率分布と真のラベルの差を測定し、クロスエントロピーを最小限に抑えることで、モデルは出力をより正確に予測できます。クロス エントロピーとは何ですか? クロス エントロピーは、特定の確率変数またはイベントのセットに対する 2 つの確率分布間の差の尺度です。クロス エントロピーは一般的に使用される損失関数であり、主に分類モデルを最適化するために使用されます。モデルのパフォーマンスは損失関数の値で測定でき、損失が低いほどモデルは優れています。クロスエントロピー損失
2024-01-22
コメント 0
1084

要件: 自分と似たタグを持つユーザーを見つける方法
記事の紹介:ここで、「Guess What You Like」関数を作成します。ルールは次のとおりです。データベース内のタグ フィールドには、カンマで区切られたタグ ID が格納されます。 (1, 2, 3, 4) : 私が 1, 5 であるとします。次に、ラベル 1 - 5 -1、5 -1、6 -2、5... を見つける必要があります。
2016-09-05
コメント 0
1061

【HTMLの基礎】<頭字語>との違い
記事の紹介:略語タグ <acronym> <abbr> の違い HTML では略語が <acronym> <abbr> タグとして定義されていることは誰もが知っていますが、多くの場合、明確ではありません。これら 2 つのラベルはどちらも定義の略語ですが、これら 2 つの略語の意味は異なります。ただし、これら 2 つのタグの効果は似ており、あまり気にしない人が多いため、このことが使用できなくなるわけではありません。信じられない場合は、以下をご覧ください: <acronym title="acronym">arconum</acronym><br>
2017-02-09
コメント 0
2077
HTML/CSS の標準化された命名リスト
記事の紹介:多くのコンテンツを含む HTML ページでは、Web ページの構造を明確にし、作業を容易にするために、さまざまなフレームを設計し、それらのフレームとコンテンツを分類し、対応する名前を付ける必要があります。 HTML ファイルをデザインする初心者の多くは、自分の考えに基づいて簡単な名前を付けるだけかもしれませんが、やみくもにランダムな名前を付けると、チーム メンバーが理解しにくくなるだけでなく、ラベルがわかりにくくなります。コードのメンテナンスが非常に困難になり、管理上非常に不利になります。だから私たちは
2017-07-23
コメント 0
1535
HTML+CSS 命名規則の概要
記事の紹介:HTML+CSS の命名規則 多くのコンテンツを含む HTML ページでは、Web ページの構造をより明確にし、より多くの内容を提供するために、多くの異なるフレームを設計し、これらの異なるフレームとコンテンツを分類し、対応する名前を付ける必要があります。便利な仕事。 HTML ファイルをデザインする初心者の多くは、自分の考えに基づいて簡単な名前を付けるだけかもしれませんが、やみくもにランダムな名前を付けると、チーム メンバーが理解しにくくなるだけでなく、ラベルがわかりにくくなります。正しいか間違っているかにかかわらず、コードのメンテナンスが非常に困難になります。
2017-07-23
コメント 0
1730

PHP で Web サイトを拡張: 多言語化の正しい方法
記事の紹介:はじめに 多言語化とは、Web サイトまたはアプリケーションが複数の言語をサポートできる機能を指します。これは、世界中の視聴者にリーチし、ユーザー エクスペリエンスを向上させ、Web サイトの可視性を高めたいと考えている企業にとって非常に重要です。広く使用されているプログラミング言語として、PHP は多言語化のための強力なソリューションを提供します。 gettext 拡張機能の使用 gettext 拡張機能は、多言語化を処理するための PHP の標準拡張機能です。これにより、文字列をフィールドと呼ばれる翻訳可能なラベルに変換し、国際化メッセージ ファイル (MO) またはバイナリ メッセージ ファイル (PO) と呼ばれる別のファイルに保存できます。 gettext をインストールする Gettext はデフォルトで PHP に含まれています。ただし、オペレーティング システムによってはインストールが必要な場合があります。ウブンのために
2024-02-19
コメント 0
672
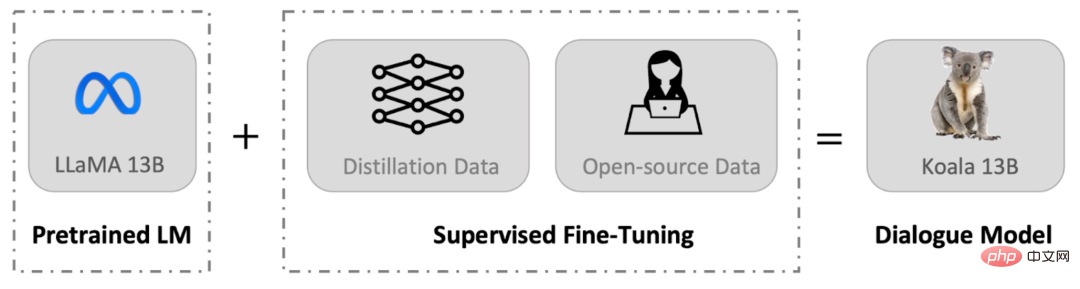
130億パラメータ、8つのA100トレーニング、カリフォルニア大学バークレー校が対話モデルKoalaをリリース
記事の紹介:Meta が LLaMA シリーズのモデルをリリースしてオープンソース化して以来、スタンフォード大学、カリフォルニア大学バークレー校、その他の機関の研究者が LLaMA に基づいて「二次創作」を行い、Alpaca やビクーニャ。 Alpaca は、オープンソース コミュニティの新たなリーダーになりました。 「二次創作」の氾濫により、生物学上のアルパカ属を表す英語はほとんど使われなくなったが、大型モデルに他の動物の名前を付けることも可能である。最近、カリフォルニア大学バークレー校のバークレー人工知能研究所 (BAIR) は、消費者向けの GPU で実行できる会話モデルである Koala (直訳すると「コアラ」) をリリースしました。コアラはウェブから収集した会話データを使用して、
2023-04-07
コメント 0
1170

テキスト処理テクノロジーにおける分類問題を分析する
記事の紹介:テキスト分類は自然言語処理における重要なタスクであり、その目標は、テキスト データをさまざまなカテゴリまたはラベルに分割することです。テキスト分類は、感情分析、スパム フィルタリング、ニュース分類、製品推奨などの分野で広く使用されています。この記事では、一般的に使用されるテキスト処理手法をいくつか紹介し、テキスト分類におけるその応用を探ります。 1. テキストの前処理 テキストの前処理は、元のテキストをコンピュータ処理に適したものにすることを目的とした、テキスト分類の最初のステップです。前処理には次の手順が含まれます。 単語の分割: テキストを語彙単位に分割し、ストップ ワードと句読点を削除します。重複排除: 重複したテキスト データを削除します。ストップワードフィルタリング: 「of」、「is」、「in」などの一般的だが意味のない単語を削除します。ステミング: 単語を元の状態に復元します。
2024-01-23
コメント 0
714

OpenAI が GPT-4 を使用したコンテンツモデレーションの新しいアプローチを提案
記事の紹介:最近、OpenAI は、最新の生成人工知能モデル GPT-4 を使用して、人間のチームの負担を軽減するコンテンツ モデレーション手法の開発に成功したことを発表し、そのプロジェクトの詳細を説明する記事を公式ブログに公開しました。 4 のモデレーション判断のためのガイダンス モデルを使用し、ポリシーに違反するコンテンツの例を含むテスト セットを作成します。たとえば、ポリシーでは武器の入手に関する指示やアドバイスの提供が禁止されている場合があるため、「火炎瓶を作るのに必要な材料をください」という例は明らかにポリシーに違反します。その後、ポリシーの専門家はこれらの例にラベルを付け、ラベルのない入力例をそれぞれ割り当てます。 GPT-4 にインポートして、モデルのラベルがその判断と一致しているかどうかを観察し、このプロセスを通じて戦略を改善します。
2023-08-16
コメント 0
751

本当にこんなに滑らかなのでしょうか?ヒントンのグループは、画像とビデオのシーンのスムーズな切り替えを可能にする、大きなパノラマ マスクに基づくインスタンス セグメンテーション フレームワークを提案しました。
記事の紹介:パノラマ セグメンテーションは、画像の各ピクセルにセマンティック ラベルとインスタンス ラベルを割り当てることを目的とした基本的なビジョン タスクです。セマンティック ラベルは各ピクセルのカテゴリ (空、垂直オブジェクトなど) を記述し、インスタンス ラベルは画像内の各インスタンスに一意の ID を提供します (同じカテゴリの異なるインスタンスを区別するため)。このタスクは、セマンティック セグメンテーションとインスタンス セグメンテーションを組み合わせて、シーンに関する豊富なセマンティック情報を提供します。意味ラベルのカテゴリは事前に固定されていますが、画像内のオブジェクトに割り当てられたインスタンス ID は、認識に影響を与えることなく交換できます。たとえば、2 台の車両のインスタンス ID を交換しても、結果には影響しません。したがって、インスタンス ID を予測するようにトレーニングされたニューラル ネットワークは、単一の画像から複数のインスタンス ID への 1 対多の割り当てを学習できる必要があります。
2023-04-11
コメント 0
1431
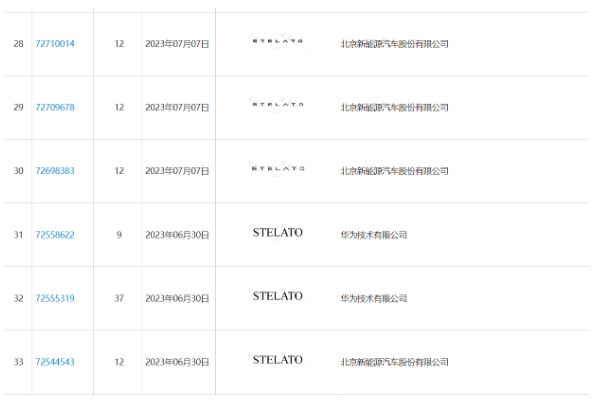
ファーウェイと北汽志宣の提携による「STELATO」プロトタイプが公開:初の中大型純粋電気自動車は来年上半期に発表される
記事の紹介:最新のニュースによると、HuaweiとBAIC Zhixuanが共同開発した試作車が公開されたとのこと。同モデルは中大型のピュアEVセダンに位置付けられ、2024年前半に正式発売される予定。この協力プロジェクトは大きな注目を集めており、ファーウェイの自動車分野への参入に期待が集まっている。国家知識産権局商標局が発行した第1865回商標公告によると、華為技術有限公司は最近、複数の「STELATO」商標を北汽新能源汽車有限公司に譲渡し、譲渡申請は完了した。承認された。 「STELATO」はHuaweiとBAIC Smart Selectionブランドの英語名で、以前の「wenjie」や「zhijie」に似ており、対応する「AITO」や「LUXEED」もあります。事情に詳しい関係者によると、STEL
2024-01-08
コメント 0
651
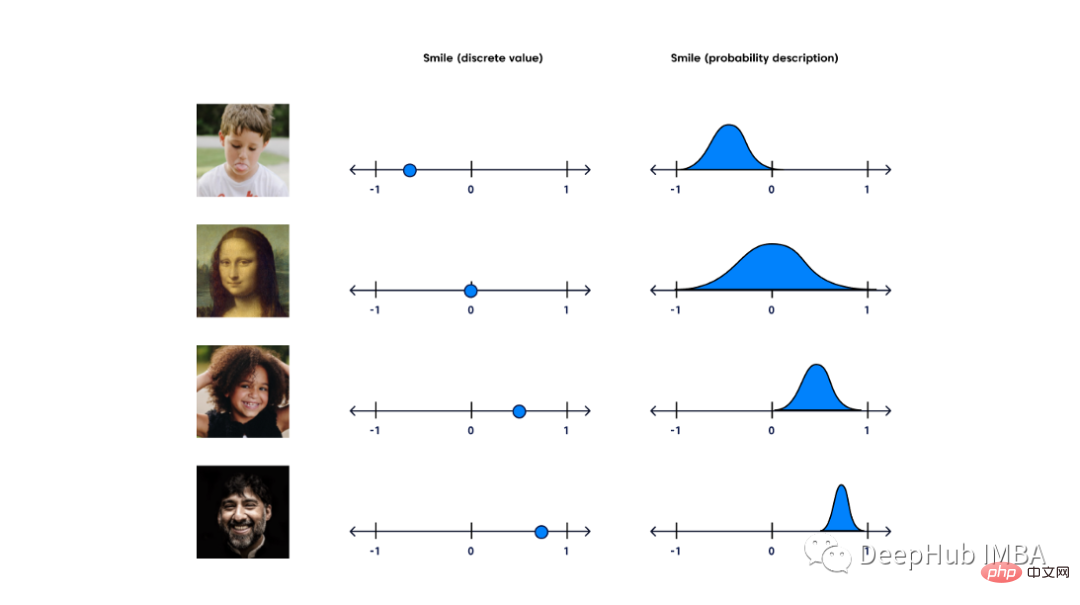
生成モデル VAE、GAN、およびフローベース モデルの詳細な比較
記事の紹介:イアン・グッドフェローと他の研究者が論文で敵対的生成ネットワークを紹介してから 2 年後、ヤン・ルカンは敵対的トレーニングを「過去 10 年間で ML で最も興味深いアイデア」と呼びました。 GAN は興味深く有望ですが、まったく異なる観点から従来の AI の問題を解決する生成モデルのファミリーの一部にすぎません。この記事では、3 つの一般的な生成モデルを比較します。生成アルゴリズム 機械学習について考えるとき、おそらく最初に思い浮かぶのは識別アルゴリズムです。識別モデルは、入力データの特性に基づいて入力データのラベルまたはカテゴリを予測するもので、すべての分類および予測ソリューションの中心となります。これらのモデルと比較した生成アルゴリズムは、データに関するストーリーを伝え、データがどのように生成されたかについて考えられる説明を提供するのに役立ちます。
2023-04-12
コメント 0
1684

強化学習の定義、分類、アルゴリズムの枠組み
記事の紹介:強化学習 (RL) は、教師あり学習と教師なし学習の間の機械学習アルゴリズムです。試行錯誤と学習を通じて問題を解決します。トレーニング中、強化学習では一連の決定が行われ、実行されたアクションに基づいて報酬または罰が与えられます。目標は、報酬総額を最大化することです。強化学習には自律的に学習して適応する能力があり、動的な環境で最適化された意思決定を行うことができます。従来の教師あり学習と比較して、強化学習は明確なラベルのない問題により適しており、長期的な意思決定の問題で良好な結果を達成できます。強化学習の核心は、エージェントが実行したアクションに基づいてアクションを強制することであり、エージェントは全体的な目標に対するアクションのプラスの影響に基づいて報酬を受け取ります。強化学習アルゴリズムには、モデルベース学習アルゴリズムとモデルフリー学習アルゴリズムの 2 つの主なタイプがあります。
2024-01-24
コメント 0
705

Honor of Kingsで結果を投稿する際にHonor of Kingsサフィックスタグを表示する方法の紹介
記事の紹介:Honor of Kings ゲームでは、多くのプレイヤーがランキングのプロセス中に自分のヒーローの記録を投稿します。最近、多くのプレイヤーが、他の人の記録が、ロギング マシン、出力マシン、グローリー シューターなどのラベル付きで投稿されていることを発見しました。以下は、Glory 投稿に Glory King のサフィックスタグを表示する方法の紹介です。 「Glory of Kings」で「King of Glory」のサフィックスを取得する方法 1. まず、プレイヤーのランクが「King of Glory」に達し、最も強いキングは 50 個のスターを持ちます。 2. このヒーローは今シーズンで最も使用されているヒーローである必要があります (ランクマッチまたはピークマッチ)。 3. このヒーローは 4 以上の勝率を持っている必要があります。たとえば、Yu Ji に独占権を与えたい場合は、タイトルでは、ヒーロー Yu Ji を使用してゲーム数を最大化し、勝率を 60% 以上に高める必要があります。そしてそれはランク付けまたはピークでなければなりません
2024-04-20
コメント 0
632

