合計 10000 件の関連コンテンツが見つかりました

Go 言語を使用して深層強化学習の研究を行うにはどうすればよいですか?
記事の紹介:深層強化学習(DeepReinforcementLearning)は、深層学習と強化学習を組み合わせた高度な技術で、音声認識、画像認識、自然言語処理などの分野で広く利用されています。 Go 言語は、高速、効率的、信頼性の高いプログラミング言語として、深層強化学習の研究に役立ちます。この記事では、Go言語を使用して深層強化学習の研究を行う方法を紹介します。 1. Go 言語と関連ライブラリをインストールし、深層強化学習に Go 言語の使用を開始します。
2023-06-10
コメント 0
1226
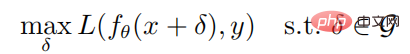
深層強化学習における敵対的な攻撃と防御
記事の紹介:01 はじめに この論文は、攻撃に対する深層強化学習の働きについて説明しています。この論文では、著者はロバスト最適化の観点から、敵対的攻撃に対する深層強化学習戦略のロバスト性を研究します。ロバストな最適化の枠組みの下では、戦略の期待利益を最小限に抑えることで最適な敵対的攻撃が与えられ、それに応じて最悪のシナリオに対処する戦略のパフォーマンスを向上させることで優れた防御メカニズムが実現されます。攻撃者は通常、訓練環境では攻撃できないことを考慮して、著者は、環境と相互作用することなく戦略の期待利益を最小限に抑えることを試みる貪欲な攻撃アルゴリズムを提案します; さらに、著者はまた、敵対的訓練を行う防御アルゴリズムも提案します。最大最小ゲームを使用した深層強化学習アルゴリズム。 Atari ゲーム環境での実験結果は次のことを示しています。
2023-04-08
コメント 0
1333
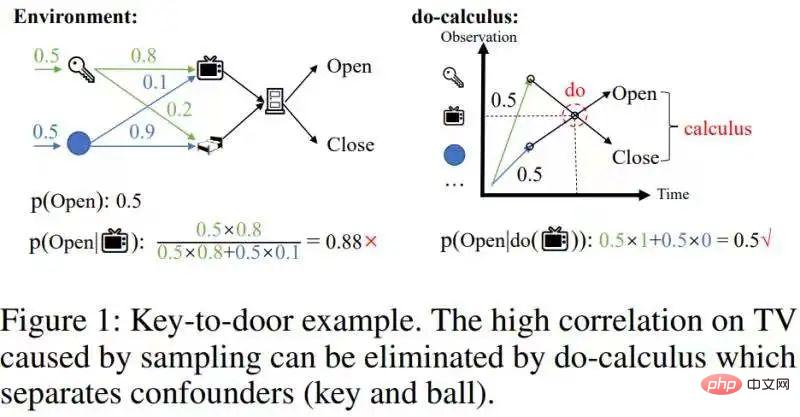
初めて導入しました!因果推論を使用して部分的に観察可能な強化学習を行う
記事の紹介:この記事「履歴ベースの強化学習のための高速反事実推論」では、因果推論の計算複雑さをオンライン強化学習と組み合わせられるレベルまで大幅に軽減する高速因果推論アルゴリズムを提案しています。この記事の理論的貢献は主に 2 点です: 1. 時間平均因果効果の概念を提案した; 2. 有名なバックドア基準を単変量介入効果推定から多変量介入効果推定に拡張し、ステップ バックドア基準と呼ばれます。背景には、部分観察可能な強化学習と因果推論に関する基礎知識の準備が必要です。ここではあまり詳しく説明せずに、いくつかのポータルを紹介します。 部分的に観察可能な拡張機能
2023-04-15
コメント 0
1083

逆強化学習: 定義、原理、応用
記事の紹介:逆強化学習 (IRL) は、観察された動作を使用して、その背後にある根本的な動機を推測する機械学習手法です。従来の強化学習とは異なり、IRL は明示的な報酬信号を必要としませんが、代わりに行動を通じて潜在的な報酬関数を推測します。この方法は、人間の行動を理解し、シミュレートする効果的な方法を提供します。 IRL の動作原理は、マルコフ決定プロセス (MDP) のフレームワークに基づいています。 MDP では、エージェントはさまざまなアクションを選択することによって環境と対話します。環境はエージェントの行動に基づいて報酬シグナルを与えます。 IRL の目標は、観察されたエージェントの行動から未知の報酬関数を推測して、エージェントの行動を説明することです。さまざまな状態でエージェントが選択したアクションを分析することで、IRL はエージェントの行動をモデル化できます。
2024-01-22
コメント 0
887

ポリシー勾配強化学習を用いたAB最適化手法
記事の紹介:ABテストはオンライン実験で広く使われている手法です。その主な目的は、ページまたはアプリケーションの 2 つ以上のバージョンを比較して、どのバージョンがより優れたビジネス目標を達成しているかを判断することです。これらの目標は、クリックスルー率、コンバージョン率などです。対照的に、強化学習は、試行錯誤学習を使用して意思決定戦略を最適化する機械学習方法です。ポリシー勾配強化学習は、最適なポリシーを学習することで累積報酬を最大化することを目的とした特別な強化学習手法です。どちらもビジネス目標の最適化において異なる用途を持っています。 AB テストでは、さまざまなページのバージョンをさまざまなアクションと考え、ビジネス目標は報酬シグナルの重要な指標と考えることができます。最大限のビジネス目標を達成するには、次のことを選択できる戦略を設計する必要があります。
2024-01-24
コメント 0
996

階層型強化学習
記事の紹介:階層型強化学習 (HRL) は、高レベルの行動と意思決定を階層的に学習する強化学習手法です。従来の強化学習手法とは異なり、HRL はタスクを複数のサブタスクに分解し、各サブタスクでローカル戦略を学習し、これらのローカル戦略を組み合わせてグローバル戦略を形成します。この階層的な学習方法により、高次元の環境や複雑なタスクによって引き起こされる学習の困難さを軽減し、学習の効率とパフォーマンスを向上させることができます。階層的な戦略を通じて、HRL はさまざまなレベルで意思決定を行い、より高いレベルのインテリジェントな動作を実現できます。このアプローチは、ロボット制御、ゲームプレイ、自動運転などの多くの分野に応用できます。
2024-01-22
コメント 0
1415

強化学習における報酬関数設計の問題
記事の紹介:強化学習における報酬関数設計の問題 はじめに 強化学習は、エージェントと環境の間の相互作用を通じて最適な戦略を学習する方法です。強化学習では、報酬関数の設計がエージェントの学習効果にとって重要です。この記事では、強化学習における報酬関数の設計の問題を調査し、具体的なコード例を示します。報酬関数の役割と目標報酬関数は強化学習の重要な部分であり、特定の状態でエージェントが取得する報酬値を評価するために使用されます。その設計は、エージェントが最適なアクションを選択することで長期的な疲労を最大化するようにガイドするのに役立ちます。
2023-10-09
コメント 0
1727

強化学習におけるアルゴリズム選択の問題
記事の紹介:強化学習におけるアルゴリズム選択の問題には、特定のコード例が必要です。強化学習は、エージェントと環境の間の相互作用を通じて最適な戦略を学習する機械学習の分野です。強化学習では、適切なアルゴリズムを選択することが学習効果にとって非常に重要です。この記事では、強化学習におけるアルゴリズム選択の問題を調査し、具体的なコード例を示します。強化学習では、Q-Learning、DeepQNetwork (DQN)、Actor-Critic など、選択できるアルゴリズムが多数あります。適切なアルゴリズムを選択する
2023-10-08
コメント 0
1197

PHP で深層強化学習と自然言語翻訳を実行するにはどうすればよいですか?
記事の紹介:現代のテクノロジーの開発において、深層強化学習と自然言語翻訳は 2 つの最も代表的な応用分野です。シンプルで習得しやすいプログラミング言語である PHP もこれら 2 つの分野に参加でき、AI テクノロジーの広範な応用にさらなる可能性をもたらします。 1. 深層強化学習 深層強化学習は、人工知能の分野で人気のある研究方向であり、ゲーム、自動運転、ロボット制御などの多くの分野で広く使用されています。中心となるアイデアは、特定の入力とターゲット出力を使用してディープ ニューラル ネットワークをトレーニングすることです。
2023-05-22
コメント 0
724

PHP で深層強化学習とユーザー行動分析を実行するにはどうすればよいですか?
記事の紹介:ディープラーニング技術の継続的な開発により、人工知能はさまざまな業界でますます使用されています。さまざまなプログラミング言語の中でも、サーバーサイド言語として人気のある PHP は、ユーザー行動分析に深層強化学習テクノロジーを使用することもできます。ディープラーニングは、大量のデータをトレーニングすることでパターンや規則性を発見する機械学習テクノロジーです。深層強化学習は、深層学習と強化学習を組み合わせた手法で、複雑な意思決定の問題を解決するために使用されます。 PHP で深層強化学習を実装するには、関連する PHP ライブラリとボックスを使用する必要があります
2023-05-26
コメント 0
1004

迷路を歩くネズミから人間を倒すAlphaGoまで、強化学習の発展
記事の紹介:強化学習のことになると、多くの研究者のアドレナリンが制御不能に急増します。ゲーム AI システム、現代のロボット、チップ設計システム、その他のアプリケーションにおいて非常に重要な役割を果たします。強化学習アルゴリズムにはさまざまな種類がありますが、主に「モデルベース」と「モデルフリー」の 2 つのカテゴリに分類されます。 TechTalks との対談の中で、神経科学者であり『知能の誕生』の著者である Daeyel Lee 氏は、人間と動物、人工知能と自然知能における強化学習のさまざまなモデル、および将来の研究の方向性について話し合いました。モデルフリーの強化学習 19 世紀後半、心理学者のエドワード ソーンダイクによって提案された「効果の法則」がモデルフリーの強化学習の基礎となりました。 Th
2023-05-09
コメント 0
877

Xishanju AI 技術専門家 Huang Honbo 氏: ゲームにおける強化学習と動作ツリーの実践的な統合
記事の紹介:2022年8月6日から7日まで、AISummitグローバル人工知能技術カンファレンスは予定通り開催されます。 7日午後に開催された「人工知能フロンティア探索」サブフォーラムでは、西山州のAI技術専門家である黄紅波氏が「ゲームにおける強化学習と行動ツリーの実践的な組み合わせ」をテーマに、詳細を共有した。ゲーム分野における強化学習の影響。 Huang Honbo 氏は、強化学習テクノロジーの実装は、アルゴリズムをより強力に変更することではなく、強化学習テクノロジーを深層学習やゲーム プランニングと組み合わせて、完全なソリューション セットを形成し、実装することにあると述べました。強化学習によりゲームがよりインテリジェントになります。ゲームに強化学習を実装すると、ゲームがよりインテリジェントになり、よりプレイしやすくなります。これがゲームでの強化学習の使用です。
2023-04-09
コメント 0
1829

PromptPG: 強化学習が大規模言語モデルと出会うとき
記事の紹介:数学的推論は人間の知性の中核となる能力ですが、抽象的思考と論理的推論は依然として機械にとって大きな課題です。 GPT-3 や GPT-4 などの大規模な事前トレーニング済み言語モデルは、テキストベースの数学的推論 (数学的な文章題など) において大幅な進歩を遂げました。ただし、これらのモデルが表形式データなどの異種情報を含むより複雑な問題を処理できるかどうかは現時点では不明です。このギャップを埋めるために、UCLA とアレン人工知能研究所 (AI2) の研究者は、38,431 個のオープンドメイン問題のデータセットである表形式数学単語問題 (TabMWP) を導入しました。
2023-04-07
コメント 0
1232

Transformer は強化学習においてどこまで発展しましたか?清華大学、北京大学などが共同でTransformRLのレビューを発表
記事の紹介:強化学習 (RL) は逐次的な意思決定のための数学的形式を提供し、深層強化学習 (DRL) も近年大きな進歩を遂げています。ただし、サンプル効率の問題により、現実世界における深層強化学習手法の広範な適用が妨げられています。この問題を解決するための効果的なメカニズムは、DRL フレームワークに誘導バイアスを導入することです。深層強化学習では、関数近似器が非常に重要です。ただし、教師あり学習 (SL) のアーキテクチャ設計と比較して、DRL のアーキテクチャ設計の問題はまだほとんど研究されていません。 RL アーキテクチャに関する既存の作業のほとんどは、教師あり/半教師あり学習コミュニティによって推進されています。たとえば、DRL で高次元画像に基づいて入力を処理するには、畳み込みニューラル ネットワーク (CNN) を導入するのが一般的なアプローチです。
2023-04-13
コメント 0
781
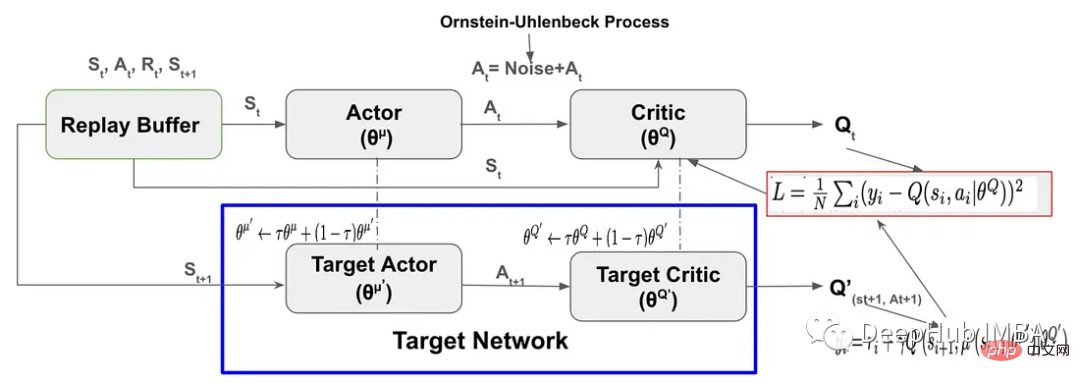
PyTorch コードの実装と DDPG 強化学習の段階的な説明
記事の紹介:Deep Deterministic Policy Gradient (DDPG) は、Deep Q-Network からインスピレーションを得た、モデルフリーの非ポリシーの深層強化アルゴリズムです。これは、ポリシー勾配を使用する Actor-Critic に基づいています。この記事では、pytorch を使用して完全に実装します。 DDPG の主要なコンポーネントは、再生バッファー、アクタークリティック ニューラル ネットワーク、探索ノイズ、ターゲット ネットワーク、ターゲット ネットワーク用のソフト ターゲット アップデートです。
2023-04-13
コメント 0
1764

Python の深層強化学習とは何ですか?
記事の紹介:Python の深層強化学習とは何ですか?深層強化学習 (DRL) は、近年、人工知能の分野、特にゲーム、ロボット、自然言語処理などのアプリケーションにおいて重要な研究の焦点となっています。 TensorFlow、PyTorch、Keras など、Python 言語に基づく強化学習および深層学習ライブラリを使用すると、DRL アルゴリズムをより簡単に実装できます。深層強化学習の理論的基礎
2023-06-04
コメント 0
1826

釣り愛好家を高度な装備にアップグレードする方法 釣り愛好家が装備をアップグレードするためのチュートリアル
記事の紹介:釣り愛好家向けの装備強化のチュートリアルですので、装備の強化方法に注目しているプレイヤーも多いと思います。このセクションの具体的な内容を見ていきましょう。 1. 強化を開始します。自分の装備インターフェースで釣り竿をクリックすると、図に示すように強化ボタンが表示されます。 2. 通常の強化には 2 つのオプションがあります。通常の強化はアップグレードに失敗する可能性がありますが、現金の強化ではアップグレードが 100% 成功します。 +4までは強化が失敗しないので、まずは金貨を使って強化することをおすすめします。 3. 強化に成功すると、釣り竿のダメージが強化されます。ダメージは魚の体力消費量に影響し、ダメージが大きいほど毎回の体力消費が多くなります。珍しい大きな魚を釣りたいなら、
2024-07-20
コメント 0
511

強化学習における Golang の機械学習アプリケーション
記事の紹介:強化学習における Golang の機械学習アプリケーションの紹介 強化学習は、環境と対話し、報酬フィードバックに基づいて最適な動作を学習する機械学習手法です。 Go 言語には並列処理、同時実行性、メモリ安全性などの機能があり、強化学習に有利です。実践的なケース: Go 強化学習 このチュートリアルでは、Go 言語と AlphaZero アルゴリズムを使用して Go 強化学習モデルを実装します。ステップ 1: 依存関係をインストールする gogetgithub.com/tensorflow/tensorflow/tensorflow/gogogetgithub.com/golang/protobuf/ptypes/times
2024-05-08
コメント 0
510

強化学習における報酬設計の問題
記事の紹介:強化学習における報酬設計の問題には、特定のコード例が必要です。強化学習は、環境との相互作用を通じて累積報酬を最大化するアクションの実行方法を学習することを目的とした機械学習手法です。強化学習では、報酬は重要な役割を果たし、エージェントの学習プロセスにおける信号であり、エージェントの行動を導くために使用されます。ただし、報酬の設計は難しい問題であり、合理的な報酬の設計は強化学習アルゴリズムのパフォーマンスに大きな影響を与える可能性があります。強化学習では、報酬はエージェント対環境として考えることができます。
2023-10-08
コメント 0
1448

