合計 10000 件の関連コンテンツが見つかりました

PHP マイクロサービスで分散アルゴリズムとモデル トレーニングを実装する方法
記事の紹介:PHP マイクロサービスで分散アルゴリズムとモデル トレーニングを実装する方法 はじめに: クラウド コンピューティングとビッグ データ テクノロジの急速な発展に伴い、データ処理とモデル トレーニングの需要が増加しています。分散アルゴリズムとモデルのトレーニングは、効率、速度、拡張性を達成するための鍵となります。この記事では、PHP マイクロサービスで分散アルゴリズムとモデル トレーニングを実装する方法を紹介し、いくつかの具体的なコード例を示します。 1. 分散アルゴリズムとモデル トレーニングとは何ですか? 分散アルゴリズムとモデル トレーニングは、複数のマシンまたはサーバー リソースを使用してデータ処理とモデル トレーニングを同時に実行するテクノロジーです。
2023-09-25
コメント 0
1465

モデルトレーニングにおけるデータ前処理の重要性
記事の紹介:モデルトレーニングにおけるデータ前処理の重要性と具体的なコード例 はじめに: 機械学習およびディープラーニングモデルのトレーニングプロセスにおいて、データ前処理は非常に重要かつ不可欠なリンクです。データ前処理の目的は、一連の処理ステップを通じて生データをモデルのトレーニングに適した形式に変換し、モデルのパフォーマンスと精度を向上させることです。この記事の目的は、モデル トレーニングにおけるデータ前処理の重要性について説明し、一般的に使用されるデータ前処理のコード例をいくつか示すことです。 1. データ前処理の重要性 データクリーニング データクリーニングとは、
2023-10-08
コメント 0
1296

Python の基礎となるテクノロジーが明らかに: モデルのトレーニングと予測を実装する方法
記事の紹介:Python の基盤テクノロジーを明らかにする: モデルのトレーニングと予測を実装する方法、具体的なコード例が必要です Python は、学びやすく使いやすいプログラミング言語として、機械学習の分野で広く使用されています。 Python は、Scikit-Learn、TensorFlow など、多数のオープンソースの機械学習ライブラリとツールを提供します。これらのオープンソース ライブラリの使用とカプセル化により、多くの利便性が提供されますが、機械学習の基礎となるテクノロジを深く理解したい場合は、これらのライブラリとツールを使用するだけでは十分ではありません。この記事ではさらに詳しく説明します
2023-11-08
コメント 0
1704

データ不足がモデルトレーニングに及ぼす影響
記事の紹介:データ不足がモデル トレーニングに与える影響には、特定のコード サンプルが必要です。機械学習と人工知能の分野では、データはモデルをトレーニングするための中核要素の 1 つです。しかし、実際に私たちがよく直面する問題はデータ不足です。データ不足とは、トレーニング データの量が不足していること、またはアノテーション付きデータが不足していることを指し、この場合、モデルのトレーニングに一定の影響を及ぼします。データ不足の問題は、主に次の側面に反映されます。 過学習: トレーニング データの量が不十分な場合、モデルは過学習する傾向があります。過学習とは、モデルがトレーニング データに過剰に適応することを指します。
2023-10-08
コメント 0
1439

MongoDBと人工知能の組み合わせ演習とモデル学習
記事の紹介:人工知能(AI)技術の発展に伴い、さまざまな分野での応用がますます広がっています。 MongoDB は、新興データベース テクノロジとして、人工知能の分野でも大きな可能性を示しています。この記事では、MongoDB と人工知能を組み合わせた実践とモデル トレーニング、およびそれらがもたらす有益な影響について説明します。 1. 人工知能における MongoDB の応用 MongoDB は、JSON に似たデータ構造を使用するドキュメント指向のデータベース管理システムです。従来のリレーショナル データベースとの比較
2023-11-02
コメント 0
1508
Pythonで線形回帰を実装する方法
記事の紹介:Python で線形回帰を実装する手順は、使用するライブラリをインポートし、データを読み取り、前処理を実行することです。データを分析して線形回帰モデルを確立し、モデルのトレーニングを実施してモデルの効果をテストします。
2019-04-08
コメント 0
11579

Python で分類に SVM を使用するにはどうすればよいですか?
記事の紹介:SVM は一般的に使用される分類アルゴリズムであり、機械学習とデータ マイニングの分野で広く使用されています。 Python では、SVM の実装は非常に便利で、関連するライブラリを使用することで完了できます。この記事では、データの前処理、モデルのトレーニング、パラメーターの調整など、Python での分類に SVM を使用する方法を紹介します。 1. データの前処理 SVM を分類に使用する前に、データが SVM アルゴリズムの要件を満たしていることを確認するためにデータを前処理する必要があります。通常、データの前処理には次のものが含まれます。
2023-06-03
コメント 0
2103

ChatGPT Python モデル トレーニング ガイド: チャットボットをカスタマイズする手順
記事の紹介:ChatGPTPython モデル トレーニング ガイド: チャット ロボットをカスタマイズするための手順の概要: 近年、NLP (自然言語処理) 技術の発展に伴い、チャット ロボットがますます注目を集めています。 OpenAI の ChatGPT は、マルチドメイン チャットボットの構築に使用できる強力な事前トレーニング済み言語モデルです。この記事では、データの準備、モデルのトレーニング、ダイアログ サンプルの生成など、Python を使用して ChatGPT モデルをトレーニングする手順を紹介します。ステップ 1: データの準備、収集、クリーニング
2023-10-24
コメント 0
1344

人工知能における Python ラムダ式の応用: 無限の可能性を探る
記事の紹介:ラムダ式は、コードを簡素化し、効率を向上させることができる Python の匿名関数です。人工知能の分野では、ラムダ式はデータの前処理、モデルのトレーニング、予測などのさまざまなタスクに使用できます。 1. ラムダ式のアプリケーション シナリオ データの前処理: ラムダ式は、正規化、標準化、特徴抽出などのデータの前処理に使用できます。 #正規化データnORMalized_data=list(map(lambdax:(x-min(data))/(max(data)-min(data)),data))#標準化データstandardized_data=list(m
2024-02-24
コメント 0
643

AI モデルのトレーニング: 強化アルゴリズムと進化アルゴリズム
記事の紹介:強化学習アルゴリズム (RL) と進化アルゴリズム (EA) は、機械学習の分野における 2 つのユニークなアルゴリズムであり、どちらも機械学習のカテゴリに属しますが、問題解決の手法と概念には明らかな違いがあります。強化学習アルゴリズム: 強化学習は、エージェントが環境と対話し、累積報酬を最大化するために試行錯誤を通じて最適な行動戦略を学習することに核となる機械学習手法です。強化学習の鍵は、エージェントが常にさまざまな行動を試み、報酬信号に基づいて戦略を調整することです。エージェントは環境と対話することで、確立された目標を達成するために意思決定プロセスを徐々に最適化します。この手法は人間の学習方法を模倣し、継続的な試行錯誤と調整を通じてパフォーマンスを向上させ、エージェントが強化学習の主要コンポーネントを含む複雑なタスクを実行できるようにします。
2024-03-25
コメント 0
700

C++ で非構造化データと半構造化データを処理するにはどうすればよいですか?
記事の紹介:C++ での非構造化データの処理には、データの前処理、特徴抽出、モデルのトレーニングが含まれます。半構造化データの処理には、データの解析、抽出、変換が含まれます。具体的な手順は次のとおりです。 非構造化データ: データの前処理: ノイズの除去と正規化。特徴抽出: データから特徴を抽出します。モデルのトレーニング: 機械学習アルゴリズムを使用してパターンを学習します。半構造化データ: データ解析: 適切な形式 (XML、JSON、YAML) への変換。データ抽出: 必要な情報を取得します。データ変換: さらなる処理に適した形式へ。
2024-06-01
コメント 0
893
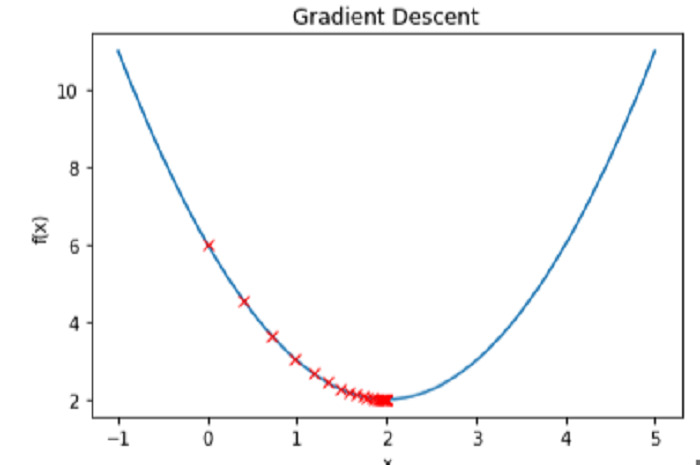
極小値を見つけるために Python で勾配降下法アルゴリズムを実装するにはどうすればよいですか?
記事の紹介:勾配降下法は機械学習における重要な最適化手法であり、モデルの損失関数を最小限に抑えるために使用されます。平たく言えば、損失関数を最小化する理想的な値の範囲が見つかるまで、モデルのパラメーターを繰り返し変更する必要があります。この方法は、損失関数の負の勾配の方向に、より具体的には最急降下経路に沿って小さなステップを踏むことによって機能します。学習率は、アルゴリズムの速度と精度の間のトレードオフを調整するハイパーパラメーターであり、ステップ サイズのサイズに影響します。線形回帰、ロジスティック回帰、ニューラル ネットワークなどの多くの機械学習手法では、勾配降下法が採用されています。その主な用途はモデルのトレーニングで、目標はターゲット変数の期待値と実際の値の差を最小限に抑えることです。この投稿では、Python でのグラデーションの実装について見ていきます。
2023-09-06
コメント 0
810

Golang テクノロジーは機械学習におけるモデル トレーニングを加速します
記事の紹介:Go の高性能な同時実行性を利用することで、機械学習モデルのトレーニングを高速化できます。 1. データのロードに Goroutine を最大限に活用する並列データのロード。 2. チャネル メカニズムによる最適化アルゴリズム、分散コンピューティング。ネイティブ ネットワーク サポートを使用して、複数のマシンでトレーニングします。
2024-05-09
コメント 0
888

ModelScope-Agent を使用すると、初心者でも専属エージェントを作成でき、乳母レベルのチュートリアルが含まれています。
記事の紹介:ModelScope-Agent は、ユーザーが独自のエージェントを簡単に作成できるよう、汎用的でカスタマイズ可能なエージェント フレームワークを提供します。このフレームワークは、コアとしてオープン ソースの大規模言語モデル (LLM) に基づいており、次の特徴を持つユーザー フレンドリーなシステム ライブラリを提供します。 カスタマイズ可能で包括的なフレームワーク: データ収集、ツールの取得、ツールの登録、ストレージをカバーするカスタマイズ可能なエンジン設計を提供します。管理、カスタマイズされたモデルのトレーニング、実用的なアプリケーションなどを使用して、実際のシナリオでアプリケーションを迅速に実装できます。コア コンポーネントとしてのオープン ソース LLM: ModelScope コミュニティで複数のオープン ソース LLM でのモデル トレーニングをサポートし、中国語と英語のツール命令データ セットをサポートする MSAgent-Bench をオープン ソースで提供します。
2023-09-20
コメント 0
1257

AI ML ソリューションを作成する手順
記事の紹介:データ収集、モデルのトレーニング、展開をガイドする詳細なロードマップ。このプロセスは反復的なものであるため、ソリューションを微調整するときに、以前のステップに戻ることがよくあります。
ステップ 1: 問題を理解する
gの前
2024-12-24
コメント 0
587

JavaScript の配列操作
記事の紹介:JavaScript での 2D、3D、または 4D 配列の操作は、AI モデルのトレーニングと画像/音声/ビデオ分析に必要です。
以下は、Tensorflow.js のような行列パッケージを使用せずに純粋な JavaScript を使用して配列を操作するための便利な関数をいくつか示しています。
転置
2024-09-01
コメント 0
1215

LLaMA 微調整によりメモリ要件が半分に削減、清華社は 4 ビット オプティマイザを提案
記事の紹介:大規模なモデルのトレーニングと微調整にはビデオ メモリに対する高い要件があり、オプティマイザの状態はビデオ メモリを主に消費するものの 1 つです。最近、清華大学の Zhu Jun 氏と Chen Jianfei 氏のチームは、ニューラル ネットワーク トレーニング用の 4 ビット オプティマイザーを提案しました。これにより、モデル トレーニングのメモリ オーバーヘッドが節約され、全精度オプティマイザーに匹敵する精度を達成できます。 4 ビット オプティマイザーは、多数の事前トレーニングおよび微調整タスクで実験されており、精度を維持しながら LLaMA-7B の微調整のメモリ オーバーヘッドを最大 57% 削減できます。論文: https://arxiv.org/abs/2309.01507 コード: https://github.com/thu-ml/low-bit-optimizers モデルトレーニングにおけるメモリボトルネック
2023-09-12
コメント 0
656

Pythonを使って住宅価格予測ガジェットを作ってみよう!
記事の紹介:こんにちは、みんな。これは Kaggle Web サイトからの住宅価格予測の例で、多くのアルゴリズム初心者にとって最初のコンテストの質問です。このケースには、EDA、特徴エンジニアリング、モデル トレーニング、モデル融合などを含む、機械学習の問題を解決するための完全なプロセスが含まれています。この事例については、住宅価格予測プロセスについて以下をご覧ください。長い言葉や冗長なコードはなく、単純な説明だけです。 1. EDA 探索的データ分析 (EDA) の目的は、データセットを完全に理解できるようにすることです。このステップでは、次のコンテンツを調べます。 EDA コンテンツ 1.1 入力データセット train = pd.read_csv('
2023-04-12
コメント 0
1382