
コース 上級 13980
コース紹介:この問題は依然として、基礎知識がゼロの学生、またはバックエンドからフロントエンドに切り替えた学生を対象として、業界の専門家によるライブブロードキャスト授業です。コース設計は、オリジナルの HTML5+CSS3+JS+Vue3+Vant プロジェクトに基づいて、4 つの段階に分かれており、合計 50 日間の学習が行われます。現在最も人気のある Vue3+Vite+TS+ElementPlus が追加され、モールのフロントエンド、モールのバックエンド管理システム、ミニプログラム、APP などのマルチエンド開発が完了します。詳しいお問い合わせはWeChat:phpcn01(Yueyue先生)までご連絡ください。

コース 初級 7942
コース紹介:XLink と XPointer チュートリアル XLink は、XML ドキュメント内にハイパーリンクを作成する標準的な方法を定義します。 XPointer を使用すると、これらのハイパーリンクが XML ドキュメント内のより具体的な部分 (フラグメント) を指すことができます。今すぐ XLink と XPointer の学習を始めましょう! 目次 XLink と XPointer の概要 この章では、XLink と XPointer の概念について説明します。 XLink および XPointer の構文 XLink および XPointer の構文

コース 初級 10662
コース紹介:「XML スキーマのチュートリアル」 XML スキーマは、XML ドキュメントの構造を記述します。このチュートリアルでは、アプリケーションで XML スキーマ言語を読み取って作成する方法、XML スキーマが DTD よりも強力な理由、およびアプリケーションで XML スキーマを使用する方法を学びます。今すぐ XML スキーマの学習を始めましょう!

コース 初級 22007
コース紹介:デザイン パターン (デザイン パターン) は、ほとんどの人に知られている、繰り返し使用されるコード設計エクスペリエンスを分類してカタログ化した一連の概要です。デザイン パターンを使用する目的は、コードを再利用し、コードを他の人が理解しやすくし、コードの信頼性を確保することです。デザイン パターンが自分自身、他者、およびシステムにとって Win-Win であることは疑いの余地がありません。デザイン パターンにより、コード作成が真のエンジニアリングになります。デザイン パターンは、建物の構造と同じように、ソフトウェア エンジニアリングの基礎です。

コース 初級 27922
コース紹介:正規表現。正規表現とも呼ばれます。 (英語: Regular Expression、コード内では regex、regexp、または RE と略されることがよくあります)、コンピューター サイエンスの概念。通常のテーブルは、特定のパターン (ルール) に一致するテキストを取得および置換するために使用されます。
大規模な Laravel プロジェクトでブートストラップのバージョンを更新する
皆さん、私は大規模な Laravel プロジェクトを持っています。プロジェクトの Bootstrap バージョンは 3 です。変えたいです。どうすればいいですか?
2023-09-03 19:24:13 0 1 664
PHP中国語ウェブサイト大規模生放送公共福祉無料クラス登録ポスト。 。 。
2018-06-04 13:03:08 32 848 66034
4日連続! PHP 中国語 Web サイトの大規模な福祉生放送クラス:「php フルスタック開発経験の共有」が開始され、引き続き興奮しています。
2018-10-17 09:05:25 1 1 3060
PHP中国語ウェブサイトの大規模な福祉生放送が始まります! PHPフレームワークをゼロから開発し、オリジナル開発フレームワークを使って恥ずかしいこと百科サイトを真似てみる(終了しました)
2018-01-22 11:04:52 29 418 55290

コース紹介:この包括的なコースでは、大規模な言語モデル(LLMS)を調査し、2つの異なる学習パスを提供します。最適なLLMを構築するためのLLM科学者トラックと、LLMベースのアプリケーションを開発および展開するためのLLMエンジニアトラックです。 インタラクティブ
2025-02-25 コメント 0 729

コース紹介:Deepseek:LLMSの強化学習に深く潜ります Deepseekの最近の成功は、低コストで印象的なパフォーマンスを達成し、大規模な言語モデル(LLM)トレーニング方法の重要性を強調しています。この記事では、補強に焦点を当てています
2025-02-26 コメント 0 1134

コース紹介:目次 はじめに なぜ大規模な言語モデルを微調整するのでしょうか?ソリューションの概要 環境のセットアップ Python を使用したトレーニングと微調整 .NET Core への微調整されたモデルの統合 Azure への展開のベスト プラクティス 結論 はじめに 大規模言語モデル (LLM) は、人間のようなテキストを理解して生成する機能で広く注目されています。ただし、多くの組織は、汎用モデルでは完全には捕捉できない可能性のある、独自のドメイン固有のデータ セットと語彙を持っています。微調整により、開発者はこれらの大規模なモデルを特定の環境や業界に適応させることができるため、精度と関連性が向上します。この記事では、Python を使用して LLM を微調整し、結果のモデルを .NETCoreC# アプリケーションに統合してデプロイする方法について説明します。
2025-01-14 コメント 0 1046

コース紹介:ラップトップで独自のchatgptを実行する:LLM量子化のガイド ラップトップで直接自分のchatgptを実行することを夢見たことはありませんか? 大規模な言語モデル(LLMS)の進歩のおかげで、これは現実になりつつあります。 重要なのは量子化です - Techniq
2025-03-05 コメント 0 791
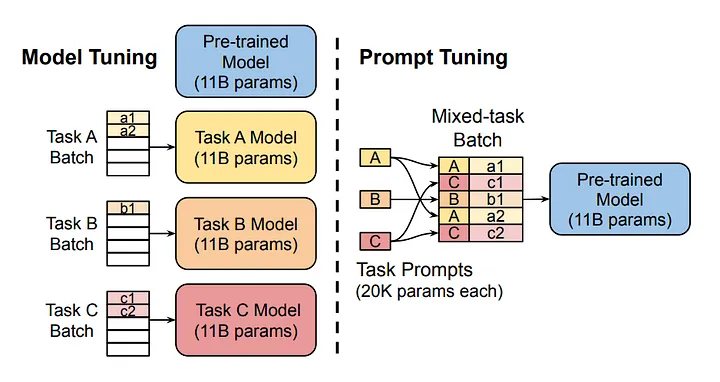
コース紹介:プロンプトチューニング:大規模な言語モデルを強化するためのパラメーター効率の高いアプローチ 大規模な言語モデル(LLMS)の急速に前進する分野では、競争力を維持するために迅速なチューニングなどの技術が重要です。 この方法はpre-tを強化します
2025-03-06 コメント 0 945
