
コース 中級 11382
コース紹介:「独習 IT ネットワーク Linux ロード バランシング ビデオ チュートリアル」では、主に nagin の下で Web、lvs、Linux 上でスクリプト操作を実行することで Linux ロード バランシングを実装します。

コース 上級 17696
コース紹介:「Shangxuetang MySQL ビデオチュートリアル」では、MySQL データベースのインストールから使用までのプロセスを紹介し、各リンクの具体的な操作を詳しく紹介します。

コース 上級 11395
コース紹介:「Brothers Band フロントエンド サンプル表示ビデオ チュートリアル」では、誰もが HTML5 と CSS3 を使いこなせるように、HTML5 と CSS3 テクノロジーのサンプルを紹介します。
問題 2003 (HY000) を修正する方法: MySQL サーバー 'db_mysql:3306' に接続できません (111)
2023-09-05 11:18:47 0 1 884
2023-09-05 14:46:42 0 1 769
CSS グリッド: 子コンテンツが列幅をオーバーフローした場合に新しい行を作成する
2023-09-05 15:18:28 0 1 650
AND、OR、NOT 演算子を使用した PHP 全文検索機能
2023-09-05 15:06:32 0 1 620
2023-09-05 15:34:44 0 1 1035

コース紹介:深層強化学習(DeepReinforcementLearning)は、深層学習と強化学習を組み合わせた高度な技術で、音声認識、画像認識、自然言語処理などの分野で広く利用されています。 Go 言語は、高速、効率的、信頼性の高いプログラミング言語として、深層強化学習の研究に役立ちます。この記事では、Go言語を使用して深層強化学習の研究を行う方法を紹介します。 1. Go 言語と関連ライブラリをインストールし、深層強化学習に Go 言語の使用を開始します。
2023-06-10 コメント 0 1220
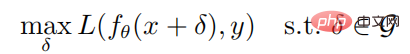
コース紹介:01 はじめに この論文は、攻撃に対する深層強化学習の働きについて説明しています。この論文では、著者はロバスト最適化の観点から、敵対的攻撃に対する深層強化学習戦略のロバスト性を研究します。ロバストな最適化の枠組みの下では、戦略の期待利益を最小限に抑えることで最適な敵対的攻撃が与えられ、それに応じて最悪のシナリオに対処する戦略のパフォーマンスを向上させることで優れた防御メカニズムが実現されます。攻撃者は通常、訓練環境では攻撃できないことを考慮して、著者は、環境と相互作用することなく戦略の期待利益を最小限に抑えることを試みる貪欲な攻撃アルゴリズムを提案します; さらに、著者はまた、敵対的訓練を行う防御アルゴリズムも提案します。最大最小ゲームを使用した深層強化学習アルゴリズム。 Atari ゲーム環境での実験結果は次のことを示しています。
2023-04-08 コメント 0 1326
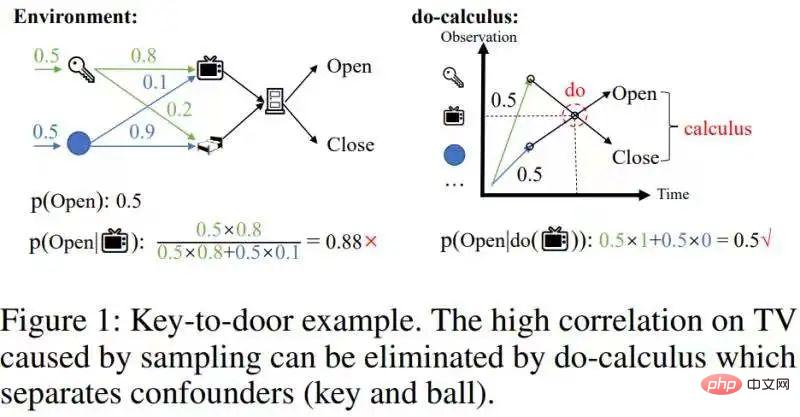
コース紹介:この記事「履歴ベースの強化学習のための高速反事実推論」では、因果推論の計算複雑さをオンライン強化学習と組み合わせられるレベルまで大幅に軽減する高速因果推論アルゴリズムを提案しています。この記事の理論的貢献は主に 2 点です: 1. 時間平均因果効果の概念を提案した; 2. 有名なバックドア基準を単変量介入効果推定から多変量介入効果推定に拡張し、ステップ バックドア基準と呼ばれます。背景には、部分観察可能な強化学習と因果推論に関する基礎知識の準備が必要です。ここではあまり詳しく説明せずに、いくつかのポータルを紹介します。 部分的に観察可能な拡張機能
2023-04-15 コメント 0 1081

コース紹介:逆強化学習 (IRL) は、観察された動作を使用して、その背後にある根本的な動機を推測する機械学習手法です。従来の強化学習とは異なり、IRL は明示的な報酬信号を必要としませんが、代わりに行動を通じて潜在的な報酬関数を推測します。この方法は、人間の行動を理解し、シミュレートする効果的な方法を提供します。 IRL の動作原理は、マルコフ決定プロセス (MDP) のフレームワークに基づいています。 MDP では、エージェントはさまざまなアクションを選択することによって環境と対話します。環境はエージェントの行動に基づいて報酬シグナルを与えます。 IRL の目標は、観察されたエージェントの行動から未知の報酬関数を推測して、エージェントの行動を説明することです。さまざまな状態でエージェントが選択したアクションを分析することで、IRL はエージェントの行動をモデル化できます。
2024-01-22 コメント 0 885

コース紹介:ABテストはオンライン実験で広く使われている手法です。その主な目的は、ページまたはアプリケーションの 2 つ以上のバージョンを比較して、どのバージョンがより優れたビジネス目標を達成しているかを判断することです。これらの目標は、クリックスルー率、コンバージョン率などです。対照的に、強化学習は、試行錯誤学習を使用して意思決定戦略を最適化する機械学習方法です。ポリシー勾配強化学習は、最適なポリシーを学習することで累積報酬を最大化することを目的とした特別な強化学習手法です。どちらもビジネス目標の最適化において異なる用途を持っています。 AB テストでは、さまざまなページのバージョンをさまざまなアクションと考え、ビジネス目標は報酬シグナルの重要な指標と考えることができます。最大限のビジネス目標を達成するには、次のことを選択できる戦略を設計する必要があります。
2024-01-24 コメント 0 995
