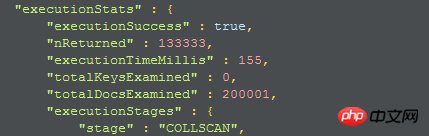
find を直接使用してすべてのフィールドを返すと、結果は次のようになり、クエリ時間は 155
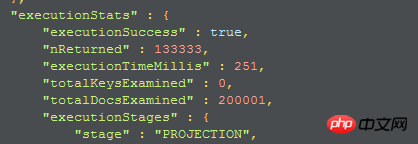
戻りフィールドが制限されている場合、クエリ時間は長くなり、クエリ時間は 251
光阴似箭催人老,日月如移越少年。
投稿した実行計画では主に次の情報が明らかになります:
1. 最初の実行計画:
インデックスが使用されていないため、collscan はそれが完全なコレクション スキャンであることを明らかにするため、インデックスの作成を検討できます
2. 2 番目の実行計画:
やはりフルコレクションスキャンであり、条件を満たすドキュメントがメモリにスキャンされ、メモリ上で投影が完了し、指定されたフィールドが選択されてフィールドが返されます。このままではさらに時間がかかりそうです。
指定されたフィールドのみが返されますが、ストレージの読み取りまたはコレクション全体のスキャンの場合は、ドキュメント全体のみを返すことができます。これはおそらくデータベースの基本原則です。ドキュメントに従って読み取りと書き込みを行います。また、一部の列型データベースは列に従って保存されますが、多くのデータベースは行またはドキュメントに従って保存されます。
指定したフィールドにカバーされたインデックスを作成し、指定したフィールドのみを返す場合、インデックスをスキャンするだけで指定したフィールドを返すことができるため、これが最も効率的です。
ご参考までに。
MongoDB が大好きです!楽しむ!


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




投稿した実行計画では主に次の情報が明らかになります:
1. 最初の実行計画:
インデックスが使用されていないため、collscan はそれが完全なコレクション スキャンであることを明らかにするため、インデックスの作成を検討できます
2. 2 番目の実行計画:
やはりフルコレクションスキャンであり、条件を満たすドキュメントがメモリにスキャンされ、メモリ上で投影が完了し、指定されたフィールドが選択されてフィールドが返されます。このままではさらに時間がかかりそうです。
指定されたフィールドのみが返されますが、ストレージの読み取りまたはコレクション全体のスキャンの場合は、ドキュメント全体のみを返すことができます。これはおそらくデータベースの基本原則です。ドキュメントに従って読み取りと書き込みを行います。また、一部の列型データベースは列に従って保存されますが、多くのデータベースは行またはドキュメントに従って保存されます。
指定したフィールドにカバーされたインデックスを作成し、指定したフィールドのみを返す場合、インデックスをスキャンするだけで指定したフィールドを返すことができるため、これが最も効率的です。
ご参考までに。
MongoDB が大好きです!楽しむ!