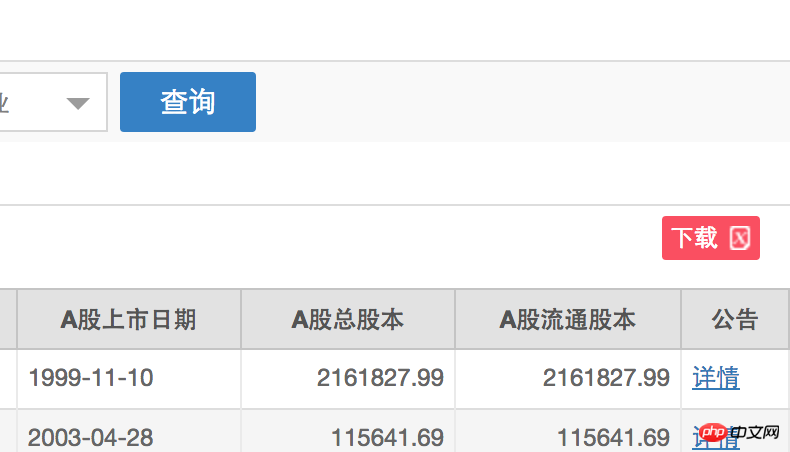
以下の小さな赤いボックスに示すように、urllib を使用して上海証券取引所の株式リストの xls ダウンロード リンクを取得したいと考えています。
リーリー
闭关修行中......
赤い線でマークされた URL で返された企業情報を確認できます。残りは、この URL をリクエストするブラウザをシミュレートすることです。省略しないと 403 が報告されます。
これは既存のソリューションです
Cookie、リファラーを表示
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




赤い線でマークされた URL で返された企業情報を確認できます。残りは、この URL をリクエストするブラウザをシミュレートすることです。省略しないと 403 が報告されます。
Refer の値をシミュレーションすることを忘れないでください。
http://blog.csdn.net/ssshen14...これは既存のソリューションです
Cookie、リファラーを表示