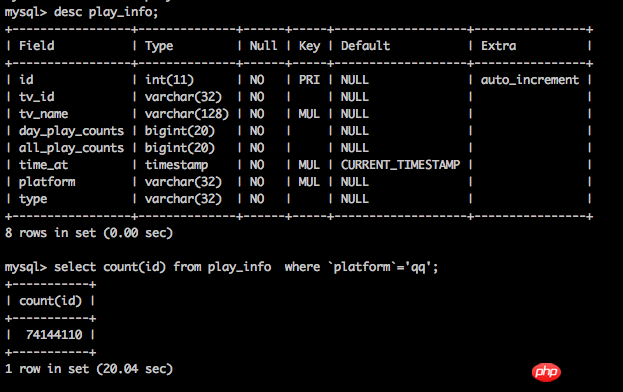
テーブル構造は図のとおりです。
現在のデータ量は 8000W 行です。
最適化の手法やアイデアはありますか?
count(*) は各列の値を (null であるかどうかに関係なく) カウントしませんが、行数を直接カウントするため、より効率的です。
たとえば、プラットフォームが qq でデータが多い場合は、合計データを使用して platform=other;
ビジネスの観点から見ると、正確な値を取得するコストは非常に高くなりますが、要件が厳密でない場合は、代わりに近似値を使用できます。
1. このような問題が発生した場合の解決策は、統計用の playfrom_count などの新しいテーブルを作成することです。 そうでない場合は、自分でテーブルを作成することをお勧めします。このようなクエリ ビジネスの量がそれほど多くない場合、またはあまり正確でない場合は、それを時々更新するタスクを実行できます。ここに追加すると、テーブル全体がスキャンされるため、主キーを追加することで取得速度を向上させることができます。
オプション 1. プラットフォームのパーティション テーブルを作成する オプション 2. プラットフォームごとにテーブルを分割する オプション 3. プラットフォームに個別のインデックスを作成する ただし、プラットフォームの値セットがそれほど大きくないことを考慮すると、それほど大きくはありませんこのインデックスを実行するのに適しています
この問題は、従来のリレーショナル データベースで発生します。一般的な解決策は、各テーブルのデータ行数を含むシステム テーブルにアクセスすることです。これは、COUNT(*) よりも数え切れないほど高速です。
マシンをアップグレードするのは単純なカウントでも 20 秒かかりますが、パーティション テーブルなどの方法はたくさんありますが、投資に見合う価値はないと感じます。
最初にビジネス シナリオのニーズを検討することをお勧めします。純粋に技術的なソリューションのコストは高すぎるため、多くの場合、それを実装することは基本的に不可能です。 考えられる解決策は次のとおりです: 1. テーブルを分割する: ストレージ エンジンは MyISAM に変更され、テーブル内の合計行数が保存されます。クエリ効率が非常に向上します。 MyISAM はトランザクションをサポートしていないため、サブテーブルによるシステム変換の負荷と MyISAM がシステム要件を満たせるかどうかを考慮する必要があります。
この場合、月または四半期ごとに複数の統計テーブルに分割することができます。たとえば、800 万件のデータがある場合、新しいテーブルを作成し、各行が 1 か月の合計レコードを表します。これにより、統計が大幅に高速化されます。















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




count(*) は各列の値を (null であるかどうかに関係なく) カウントしませんが、行数を直接カウントするため、より効率的です。
たとえば、プラットフォームが qq でデータが多い場合は、合計データを使用して platform=other;
のデータを差し引くこともできます。ビジネスの観点から見ると、正確な値を取得するコストは非常に高くなりますが、要件が厳密でない場合は、代わりに近似値を使用できます。
さらに、この時間のかかるデータ取得を維持するために、redis などの「メモリ データベース」の使用を検討することもできます。1. このような問題が発生した場合の解決策は、統計用の playfrom_count などの新しいテーブルを作成することです。
そうでない場合は、自分でテーブルを作成することをお勧めします。このようなクエリ ビジネスの量がそれほど多くない場合、またはあまり正確でない場合は、それを時々更新するタスクを実行できます。ここに追加すると、テーブル全体がスキャンされるため、主キーを追加することで取得速度を向上させることができます。
オプション 1. プラットフォームのパーティション テーブルを作成する
オプション 2. プラットフォームごとにテーブルを分割する
オプション 3. プラットフォームに個別のインデックスを作成する ただし、プラットフォームの値セットがそれほど大きくないことを考慮すると、それほど大きくはありませんこのインデックスを実行するのに適しています
この問題は、従来のリレーショナル データベースで発生します。一般的な解決策は、各テーブルのデータ行数を含むシステム テーブルにアクセスすることです。これは、COUNT(*) よりも数え切れないほど高速です。
マシンをアップグレードするのは単純なカウントでも 20 秒かかりますが、パーティション テーブルなどの方法はたくさんありますが、投資に見合う価値はないと感じます。
最初にビジネス シナリオのニーズを検討することをお勧めします。純粋に技術的なソリューションのコストは高すぎるため、多くの場合、それを実装することは基本的に不可能です。
2. 冗長なテーブルまたはフィールドを作成し、変更時に集計する必要があるデータを再計算します。大量の更新操作によってシステムの負荷が増加するかどうかを考慮する必要があります。考えられる解決策は次のとおりです: 1. テーブルを分割する: ストレージ エンジンは MyISAM に変更され、テーブル内の合計行数が保存されます。クエリ効率が非常に向上します。 MyISAM はトランザクションをサポートしていないため、サブテーブルによるシステム変換の負荷と MyISAM がシステム要件を満たせるかどうかを考慮する必要があります。
3. クエリ結果が完全に正確である必要がない場合は、クエリ時に元のテーブルを直接クエリせずに結果を定期的に計算して保存できます。この場合、月または四半期ごとに複数の統計テーブルに分割することができます。たとえば、800 万件のデータがある場合、新しいテーブルを作成し、各行が 1 か月の合計レコードを表します。これにより、統計が大幅に高速化されます。