上記のコードを通じて Apache ログ IP を抽出し、統計的重複排除を実行します。
抽出された IP データは次のとおりです: 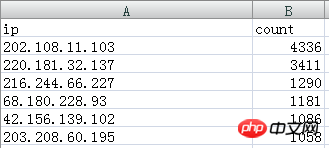
これらの IP アドレスに名前を付けて分類する方法について説明します。
たとえば、
202.108.11.103 と 220.181.32.137 は Baidu Spider IP です。
達成したい効果は次のとおりです。
この 2 つは、 IP には Baidu Spider という名前が付けられ、それらの統計を合計すると、4336 3411
Baidu Spider 7747














![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




リーリー
キーとして辞書、値としてクローラー名を使用して大規模な辞書を構築してみることができます。
リーリーパンダを使ったピボットテーブル
なんて疲れるのでしょう!
この IP グループに IPGroup (id, ip, groupname) という名前の別のテーブルを作成してみてはいかがでしょうか
その後は、たった 1 つの SQL で実行できます。とても簡単です (投稿者には IPStastics を使用させます)
リーリー