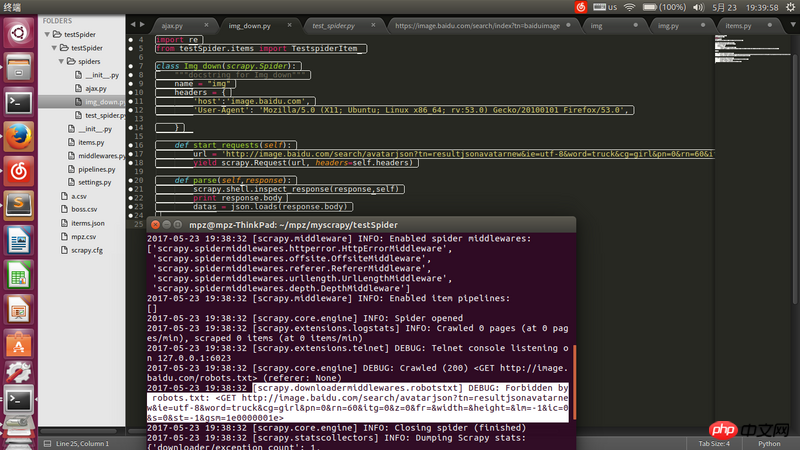
リクエストアドレスのurlはfirefoxで取得したjsonのアドレスですブラウザでは開けますがscrapyでクローリングするとBANされましたので解決してください。
https://image.baidu.com/search...
settings.py 将 ROBOTSTXT_OBEY = Falseでお試しください。
settings.py
ROBOTSTXT_OBEY = False
聴覚者を追加せずに試してください
まだ壁があるなら、私は二階に同意します。 Scrapy+Selenium+phantomjsという方法が使えます。














![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




settings.py将ROBOTSTXT_OBEY = Falseでお試しください。聴覚者を追加せずに試してください
まだ壁があるなら、私は二階に同意します。 Scrapy+Selenium+phantomjsという方法が使えます。