
JD.com 上のすべての携帯電話情報をクロールしているときに、次の問題が発生しました:
1. 次の図に示すように、戻り値が多すぎます: 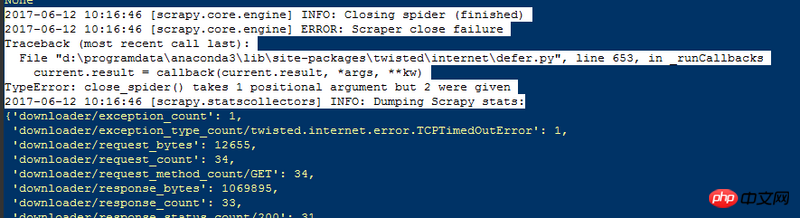
2. スパイダーのコードは次のとおりです:
importscrapy
fromscrapy.http importRequest
fromueinfo.itemsimportUeinfoItem
クラスMrueSpider(scrapy.Spider):
リーリーパイプラインのコードは次のとおりです:
インポートpymysql
クラスueinfoPipeline(オブジェクト):
リーリー














![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




パイプライン内
def closeメソッドの定義が間違っています
こうあるべき
def close(self, Spider)
内容が空の一部の値を無視する場合についてはfor を使用するとコードを節約できる可能性があります。
リーリー