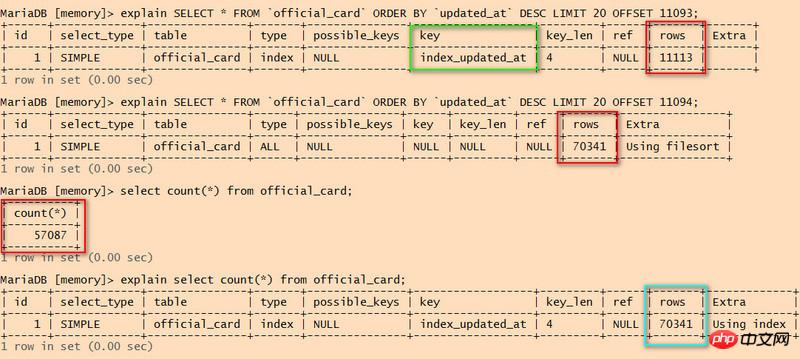
最初の 2 つのステートメントを比較すると、2 番目のステートメントではインデックスが使用されていません。スキャンされた行数が一定の数に達すると、インデックスは放棄されると記憶しています。重要な値は何ですか?
フル テーブル スキャンでは、スキャンされた行数は 70341 であることが示されていますが、データ行の合計数は 57087 のみですか?
select count(*) はインデックスを使用しますが、70341 行もスキャンします。このステートメントはパフォーマンス上の問題を引き起こしますか?















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




CBO 最適化メカニズムのデータベースでは、インデックスを使用するかどうかについての明確な重要な値はありません。実行計画の最小 COST が基準として使用されます。テーブル内の行の合計数は 5% 未満です。
2 番目のステートメントはテーブルの統計データを使用していることを理解しています。テーブルに最近大きな変更が加えられ、統計データが適時に更新されている場合、2 つのステートメントの間に大きな差異が生じることになります。
count(*) はインデックスを使用します。これは、update_at フィールドに NOT NULL の定義があることを意味し、テーブル全体のスキャンと比較して、インデックスのスキャンのコストが低くなります。