
我们知道,在mysql中执行以下语句会报错:
select count(*),concat(version(),floor(rand(0)*2))x from information_schema.tables group by x
会提示#1062 - Duplicate entry '5.6.171' for key 'group_key' ,主键重复了。
group by 实际是将查询到的每列插入到临时表中,然后再排序。那为什么插入包含一个随机数的值就会主键重复呢?
看到这个解释:http://www.jinglingshu.org/?p=4507
“通过floor报错的方法来爆数据的本质是group by语句的报错。group by语句报错的原因是floor(random(0)*2)的不确定性,即可能为0也可能为1(group by key的原理是循环读取数据的每一行,将结果保存于临时表中。读取每一行的key时,如果key存在于临时表中,则不在临时表中则更新临时表中的数据;如果该key不存在于临时表中,则在临时表中插入key所在行的数据。group by floor(random(0)*2)出错的原因是key是个随机数,检测临时表中key是否存在时计算了一下floor(random(0)*2)可能为0,如果此时临时表只有key为1的行不存在key为0的行,那么数据库要将该条记录插入临时表,由于是随机数,插时又要计算一下随机值,此时floor(random(0)*2)结果可能为1,就会导致插入时冲突而报错。即检测时和插入时两次计算了随机数的值。具体原理参考:http://www.mysqlops.com/2012/05/15/mysql-sql-analyze.html)。”
好像很有道理,按照这个说法,floor(rand(0)*2)可能产生0或1。那每次执行上述SQL,有50%几率应该是可以执行成功的。但实际每次执行都是失败的。是跟rand生成随机数有关吗?
然后我又做了一些试验:
试验1
换成select count(*),concat(version(),floor(rand(0)*1))x from information_schema.tables group by x,SQL语句每次都能成功,这个也可以理解,每次值都一样。
试验2
换成select count(*),concat(version(),rand(0)*2)x from information_schema.tables group by x。实际是能执行成功的。而是用floor取整后反而失败。
试验3
换成select count(*),concat(version(),floor(rand(0)*100))x from information_schema.tables group by x。失败
试验3
换成select count(*),concat(version(),floor(rand(0)*100000))x from information_schema.tables group by x。失败
试验4
换成select count(*),concat(version(),floor(rand(0)*1000000))x from information_schema.tables group by x。成功。
由于是随机数,插时又要计算一下随机值,此时floor(random(0)*2)结果可能为1,就会导致插入时冲突而报错。即检测时和插入时两次计算了随机数的值
这就解释不通了。随机数的值大到一定程度,又可以执行成功了?
为什么group by floor(rand(0)*2会提示主键重复呢?group by原理是什么?















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




“按照这个说法,floor(rand(0)*2)可能产生0或1。那每次执行上述SQL,有50%几率应该是可以执行成功的。”这个应该是rand函数是伪随机,所以给定种子每次执行的结果是一样的,可以用select rand(0)from information_schema来验证,多次执行后,结果相同。
group by的执行过程,是扫描过程,会建立临时表来在验证key。但是楼主的问题,我也在思考,期待高手解惑。
另外除了你描述的问题外,还有一个现象。对于不同的种子,成功和失败的情况也是不一样的,如下图。
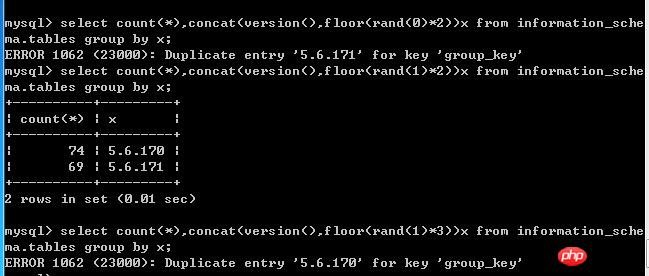
执行结果:
[Err] 1062 - Duplicate entry '5.5.20-log-95655' for key 'group_key'说明:执行floor(rand(0)*100000)结果中包含多个数值等于95655的项
证明
select count(*),concat(version(),'-',floor(rand(0)*1000000))x from information_schema.tables group by x执行结果: