
描述问题:
目前想用SQL语句来查询一个表(50万条),并将表内昵称为空的用户Openid拿出来,每百条查询一次。环境MySQL。
问题关键:
一次性取出,分百条查询,也会给服务器造成很大压力(*1),能不能让SQL查询出100条符合结果的记录,并返回最后一条的ID?
拓展:
除了我这种想法,业界有没有一个合适的方案?或者关于SQL大容量查询 的一些书籍。
*1:首先,我的服务器是小水管,50万条已经相当重了。其次,就算我现在扩展服务器配置,假设某天达到了1亿条,也会成为很大的负载压力。
表结构:
id openid nickname avatar
部分openid的nickname或avatar(头像)是空的,想要每次查出100个nickname或avatar(头像)为空的openid,并调用微信接口,将获取到的信息插入。














![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




この質問は少し変です。100 個のデータを返しますか?それとも、これら 100 個のデータのうち最後の
IDを返す必要がありますか?まず第一に、サーバーがデプロイされているマシンのパフォーマンスが非常に悪い場合を除き、500,000 個のデータは多すぎません。そのため、(非常に複雑なコードや低パフォーマンスのコードを作成しない限り) クエリ速度がそれほど遅くなる必要はありません。 SQL) を複数回取得することは確かに可能ですが、データベースの負荷は軽減されますが、ネットワークの送信負荷は増加します。
さらに、50W テーブル データのソリューションは 1E テーブル データのソリューションとは完全に異なるため、1 つのソリューションで完全に解決できると想定しないでください。
添付された SQL:
リーリーORが使用されているため、nicknameとavatarのインデックスは必要ないと推定されます。または、レコードが完了したかどうかを示すためにcompletedというフィールドを追加することもできます (つまり、 とnicknameは空ではありません。このフィールドはプログラムがデータを挿入するときに維持されるため、クエリ SQL はavatar接続を回避できます。OR現在のシナリオでは、クエリが必要なすべてのフィールドにインデックスを作成します。
1.インデックスは追加されましたか?
2. SQL を最適化する
500,000 データは実際には多くありません。
どのような機能を実現したいのかわかりません。100 個の項目を検索しても最後の 1 列だけを返すのは意味がありません。インデックス付きの書き込みストレージ処理を実装する必要がある場合、それはほぼ完了です。同じ
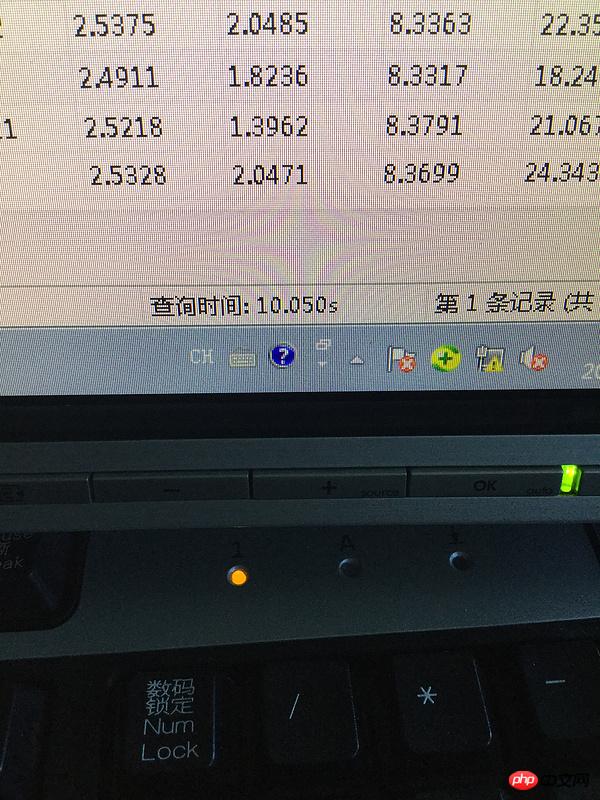 480w 行のテーブルは修飾された列をチェックし、すべての行を返します。問題は、修飾された行が多すぎて、出力時にメモリが不足している可能性があります。結果を 1 つずつ新しいテーブルに挿入すると、時間が遅くなるだけです。
480w 行のテーブルは修飾された列をチェックし、すべての行を返します。問題は、修飾された行が多すぎて、出力時にメモリが不足している可能性があります。結果を 1 つずつ新しいテーブルに挿入すると、時間が遅くなるだけです。
インデックスを追加するか、定期的にデータベースをキャッシュに書き込みます
このようなことは退屈ですし、結果が理想的でない場合は、削除しても構いません。